Całkowanie to jeden ze wzbudzających najsilniejsze lęki działów analizy matematycznej na studiach wyższych. Całka to dość rozległe i wieloznaczne pojęcie i na studiach niematematycznych (np. na studiach politechnicznych) studenci zapoznają się tylko z niewielkim wycinkiem teorii związanej z całkami. Niniejszy artykuł jest pierwszym z serii artykułów dotyczących całek nieoznaczonych, czyli tych całek, od których studenci zaczynają swą całkową edukację i które wydają się najpowszechniej kojarzonym rodzajem całek.
Co to jest całka nieoznaczona
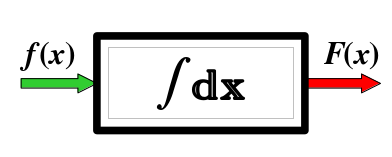
W skrócie, gdybyśmy ideę całki mieli przedstawić np. licealiście, całka nieoznaczona jest przykładem funkcjonału, czyli pewnej funkcji, której argumentem oraz wartością są inne funkcje. Jest to takie „pudełko”, na wejściu którego podajemy jedną funkcję, a na wyjściu otrzymujemy inną funkcję. Funkcja w tym ujęciu to też pudełko, tyle, że na wejściu mamy liczbę, a na wyjściu mamy inną liczbę. Zilustrowane to zostało na rysunkach 1 oraz 2.
Rysunek 1. Schemat działania funkcji
Rysunek 2. Schemat działania całki nieoznaczonej, jako funkcjonału
Zrozumienie istoty całki nieoznaczonej, wymaga poznania pojęcia pochodnej i różniczkowania funkcji jednej zmiennej. Jeśli znamy pojęcie pochodnej funkcji, całkę nieoznaczoną zdefiniować można jako operację odwrotną do obliczania pochodnej funkcji, czyli różniczkowania. Pochodna funkcji, to po prostu takie samo „pudełko”, jak to przedstawione na rysunku 2, tyle, że działające „w drugą stronę”.
Funkcja $F(x)$ nazywana jest funkcją pierwotną funkcji $f(x)$, lub całką nieoznaczoną z funkcji $f(x)$ w danym przedziale, jeśli w całym tym przedziale, funkcja $f(x)$ jest pochodną funkcji $F(x)$, lub też – co jest równoznaczne – wyrażenie $f(x) \mathrm{dx}$ jest różniczką funkcji $F(x)$, tj:
$$F'(x) = f(x) \tag {1a} \label {eq:{1a}}$$
oraz:
$$dF(x) = f(x) dx \tag {1b} \label {eq:{1b}}$$
To, że całkowanie jest operacją odwrotną do różniczkowania nie oznacza, że jest ono podobnej skali trudności do różniczkowania. Jest, niestety, znacznie trudniejsze. Moim Klientom zawsze powtarzam, że różniczkowanie, czyli obliczanie pochodnych, porównać można do „rozkręcania” tradycyjnego, mechanicznego zegarka i zmienienia go w kupkę śrubek i trybików. Może to zrobić nawet małe dziecko – kto wie, może nawet Tobie, Drogi Czytelniku, się to przytrafiło. Ba, nawet niejeden, co sprytniejszy, przedstawiciel małp człowiekowatych tego bez problemu dokona, po krótkim szkoleniu.
Rysunek 3. Przystępujemy do całkowania
Całkowanie tymczasem, jest jak montowanie sprawnego zegarka z kupki śrubek i trybików. Prawda, że dużo trudniejsze? Mało tego. Każdy, mechaniczny zegarek, da się zamienić w kupkę śrubek i trybików, ale nie z każdej kupki śrubek i trybików da się zmontować sprawny zegarek. Dokładnie tak samo jest z różniczkowaniem i całkowaniem. By nauczyć się pochodnych, wystarczy poznać trochę wzorów, zrobić dosłownie kilka przykładów na różniczkowanie funkcji złożonej, by bez większego problemu zróżniczkować każdąfunkcję elementarną.
Z całkowaniem jest inaczej. Tylko najprostsze przykłady mogą być wykonane w prosty sposób, zbliżony do różniczkowania. Ogromna większość funkcji wymaga poznania określonych „chwytów”. Nie wystarczy się nauczyć zasady, trzeba „kombinować”. To tak, jak z dowcipami typu „wisi na ścianie i śmierdzi” – mało kto wpadnie od razu na to, że chodzi o „zegar ze zdechłą kukułką”, ale jeśli raz już ktoś nam taką, lub podobną, zagadkę na jakiejś imprezie poda wraz z rozwiązaniem, przy kolejnej okazji będziemy już wiedzieć.
Nie ma więc innej drogi do nauczenia się całkowania, jak przerobienie wielu przykładów i zapamiętywanie, jakie to chwyty, tricki i sztuczki się tam pojawiały. Wówczas, gdy na egzaminie zobaczymy podobny przykład, otwieramy w głowie stosowną szufladkę i kojarzymy, że trzeba to zrobić tak, czy tak.
Ale to nie wszystko. Okazuje się, że pewnych funkcji – i to całkiem banalnych, których pochodne obliczymy „z zamkniętymi oczami” nie da się scałkować. Ściślej mówiąc one posiadają swoje całki nieoznaczone, ale nie są to funkcje elementarne. Czyli nie da się ich zapisać w postaci znanych symboli matematycznych1.
Przykładem takiej funkcji, której całki nie da się wyrazić za pomocą funkcji elementarnych jest np. całkiem niegroźnie wyglądająca funkcja:
$$f(x) = {\text e}^{x^2}$$
albo też funkcje:
$\frac {\sin x} x $, $\frac {\cos x} x$, $\sin{x^2}$ czy $\cos{x^2}$
Dla zapisania całek nieoznaczonych z tych i podobnych funkcji, opisano i wprowadzono do matematyki wyższej wiele nowych funkcji, jak funkcja błędu, funkcje Fresnela, sinus całkowy, czy logarytm całkowy, ale nie są to funkcje elementarne.
Wzory rachunku całkowego
Wzory rachunku całkowego są w zasadzie odwróceniem wzorów rachunku różniczkowego. Są to dokładnie te same wzory, ale czytane „od drugiej strony”. Pomiędzy operacją różniczkowania a całkowania nieoznaczonego jest też jedna, istotna różnica. Różniczkowanie jest zawsze jednoznaczne. Każda funkcja posiada tylko jedną pochodną. Ale, weźmy np. funkcję $f(x)=x^2$, jak wiemy – np. po lekturze naszego artykułu o obliczaniu pochodnych – pochodną tej funkcji jest $f'(x)=2x$. Ale przecież jest to także pochodna innej funkcji – np. takiej: $g(x) = x^2 + 5$. Ona również ma pochodną $g'(x) = 2x$.
Funkcją pierwotną (całką nieoznaczoną) funkcji $f(x)=2x$ mogą być zatem zarówno funkcje $F(x)=x^2$, jak też $F(x)=x^2+5$, ba – nawet $F(x)=x^2 + \sin^2 x + \cos^2 x$ (bo przecież $\sin^2 x + \cos^2 x = 1$).
Zatem całkowanie nieoznaczone to operacja jednoznaczna, ale z dokładnością, co do stałej. Dlatego też, wzory rachunku całkowego zawsze podaje się z dodaniem stałej (zwyczajowo oznaczanej $C$) do funkcji po prawej stronie.
Inną rzeczą, na którą nalezy zwrócić uwagę jest operator całkowania. Operatorem całkowania nie jest sam symbol $\int$, ale dopiero zestaw symboli: $\int\,\,\mathrm{dx}$, gdzie całkowana funkcja znajduje się w środku, pomiędzy znakiem $\int$ a wyrażeniem $\mathrm{dx}$, gdzie litera $x$ jest taka sama, jak zmienna, po której całkujemy.
Wyrażenie $\mathrm{dx}$ nie tylko wskazuje na zmienną, po której aktualnie całkujemy (możemy całkowac funkcję kilku zmiennych), ale jest ono elementarnym przyrostem tej zmiennej i gdy, korzystając z metody całkowania przez podstawienie, zamienimy zmienną $x$ na funkcję innej zmiennej, na zasadzie $x=g(t)$, to miejsce $\mathrm{dx}$ zajmie elementarny przyrost tej nowej zmiennej, czyli różniczka $g'(t)\mathrm{dt}$. To szalenie ważne – i należy sobie po prostu zakodować, że całka nieoznaczona, to $\int\,\,\mathrm{dx}$.
Innymi słowy, gdyby potraktować sam tylko symbol $\int$, jako operator całkowania nieoznaczonego, to jego argumentem nie jest funkcja, będąca pochodną wyznaczanej funkcji pierwotnej, ale różniczka funkcjipierwotnej. Całka nieoznaczona więc, to jakby „przepis” na obliczenie sumy z różniczki funkcji. Ale skąd dokąd ta suma ma być liczona, to już jest przedmiotem innego działania matematycznego – całki oznaczonej, która nie jest funkcją, a właśnie sumą. Całki oznaczone jednak będą przedmiotem zupełnie innego artykułu.
Wzory wyrażające własności całki nieoznaczonej
W przeciwieństwie do wzorów rachunku różniczkowego, wzory rachunku całkowego podamy tylko w dwu zestawach: wzory określające własności całki nieoznaczonej oraz wzory na całki nieoznaczone konkretnych funkcji. Nie będziemy tu wyróżniać wzorów ważniejszych i mniej ważnych, bo aby się sprawnie poruszać w rachunku całkowym, musimy znać wszystkie te wzory.
W przypadku pochodnych bowiem, procedura jest taka: patrzymy, jaką funkcję mamy zróżniczkować i dopasowujemy stosowny wzór. Jeśli „zapomniał” się nam on, to go sobie pomocniczo, „na boku”, wyprowadzamy. Obliczanie całek nieoznaczonych, to jednak zupełnie inna bajka. Tutaj musimy, patrząc na funkcję podcałkową, od razu rozpoznać któryś ze znanych wzorów. Jeśli jakiegoś wzoru zapomnimy, to go tam po prostu nie zauważymy i nawet nie będziemy wiedzieli, co mamy wyprowadzić.
Wzór (2), to tzw. „wyłączanie stałej przed całkę”, a wzór (3) pozwala na obliczenie sumy bądź różnicy całek różnych funkcji. Wzory te określają liniowość całki nieoznaczonej i mogą być zastąpione jednym wzorem o bardziej ogólnym charakterze, tak samo, jak miało to miejsce w przypadku wzorów rachunku różniczkowego:
$$\int \left[a \cdot f(x) + b \cdot g(x) \right] \mathrm{dx} = a \cdot \int f(x) \mathrm{dx} + b \cdot \int g(x) \mathrm{dx} \tag {3a} \label {eq:{3a}}$$
Wsród arsenału wzorów wyrażających własności całki nieoznaczonej, nie znajdziemy, niestety, wzorów na całkę ilorazu bądź iloczynu funkcji. Sprawa nie jest taka prosta, że aby scałkować wyrażenie będące iloczynem, bądź ilorazem, wystarczy użyć dedykowanego wzoru.
Istnieją jednak dwa „specjalne” wzory, będące swego rodzaju odwróceniem wzorów na pochodną iloczynu oraz wzoru na pochodną funkcji złożonej, które to wzory są fundamentem dwu najważniejszych metod całkowania – metody całkowania przez podstawienie (zamianę zmiennej) oraz metody całkowania przez części.
gdzie: $u=g(x)$ jest funkcją mającą ciągłą pochodną a $f(u)$ jest ciągła – przynajmniej w interesującym nas przedziale.2 Choć tego na pierwszy rzut oka może nie być widać, wzór ten jest odwróceniem wzoru na pochodną funkcji złożonej.
Wzór na całkowanie przez części, będący odwróceniem wzoru na pochodną iloczynu, ma następujące dwie najczęściej stosowane postaci:
$$\int u \mathrm {dv} = uv - \int v \mathrm{du} \tag {5b} \label {eq:{5b}}$$
Osobiście jestem gorącym zwolennikiem drugiej z powyższych postaci (5b) i z takiej też postaci będziemy korzystali w niniejszym artykule. Oczywiście obie funkcje, tj $f$ oraz $g$ (czyli odpowiednio $u$ oraz $v$) są funkcjami zmiennej $x$, posiadającymi ciągłe pochodne.
ale nie jest to wzór, który można by określić mianem wzoru podstawowego. Jak się później okaże, wynika on ze wzorów (4) oraz (9) i stanowi niejako część metody całkowania przez podstawienie.
$$\int \sin x \mathrm{dx} = -\cos x + C \tag {12} \label {eq:{12}}$$
$$\int \cos x \mathrm{dx} = \sin x + C \tag {13} \label {eq:{13}}$$
$$\int \frac {\mathrm{dx}}{\cos^2 x} = \tg x + C \tag {14} \label {eq:{14}}$$
$$\int \frac {\mathrm{dx}}{\sin^2 x} = -\ctg x + C \tag {15} \label {eq:{15}}$$
$$\int \frac {\mathrm{dx}}{\sqrt{1-x^2}} = \arcsin x + C = -\arccos x + C \tag {16} \label {eq:{16}}$$
$$\int \frac {\mathrm{dx}}{x^2+1} = \arctg x + C = -\arcctg x + C \tag {17} \label {eq:{17}}$$
$$\int \sinh x \mathrm{dx} = \cosh x + C \tag {18} \label {eq:{18}}$$
$$\int \cosh x \mathrm{dx} = \sinh x + C \tag {19} \label {eq:{19}}$$
$$\int \frac {\mathrm{dx}}{\cosh^2 x} = \tgh x + C \tag {20} \label {eq:{20}}$$
$$\int \frac {\mathrm{dx}}{\sinh^2 x} = -\ctgh x + C \tag {21} \label {eq:{21}}$$
$$\int \frac {\mathrm{dx}}{\sqrt{1+x^2}} = \arsinh x + C = \ln \left(x + \sqrt{x^2+1} \right) + C \tag {22} \label {eq:{22}}$$
$$\int \frac {\mathrm{dx}}{\sqrt{x^2-1}} = \arcosh x + C = \ln \left| x + \sqrt{x^2-1} \right| + C \tag {23} \label {eq:{23}}$$
We wzorze (7) „pozwoliłem” sobie pominąć czynnik $\mathrm{dx}$, gdyż i tak funkcją podcałkową jest zero. Zauważmy, że wzór (8), to odwrócenie wzoru na pochodną funkcji potęgowej. To bodaj najważniejszy wzór rachunku całkowego. Często zdarza się, że np. w kursie statystyki matematycznej, czy rachunku prawdopodobieństwa (probabilistyki) w pewnym momencie studenci dostają zadania, gdzie występuje całka. W zasadzie zawsze w takim wypadku będzie jakaś funkcja potęgowa, ewentualnie funkcja wykładnicza.
Zauważmy, że w przeciwieństwie do wzoru na pochodną funkcji potęgowej: $\left(x^a \right)' = ax^{a-1}$, który bierze pod uwagę absolutnie wszystkie potęgi: dodatnie, ujemne, ułamkowe – nawet z potęgą zerową sobie poradzi, o tyle wzór (8) nie poradzi sobie z potęgą $-1$, tj. nie da się za jego pomocą policzyć całki nieoznaczonej z funkcji $f(x) = \frac 1 x$. Całka ta wymaga odrębnego wzoru, niejako „dedykowanego” dla potęgi $-1$, czyli wzoru (9). Zwróćmy przy tym uwagę na wartość bezwzględną występującą po prawej stronie. Jest to odwrócenie „rozszerzonego” wariantu wzoru na pochodną z logarytmu naturalnego, wg którego $\left( \ln|x| \right)' = \frac 1 x$.
Warto też przyzwyczaić się do stosowanej w zapisie wzorów (9), (14), (15) i podobnych konwencji pisania $\mathrm{dx}$ w liczniku ułamka. We wzorach, w których występują mianowniki bądź pierwiastki, należy poczynić stosowne zastrzeżenia co do dziedziny, które na ogół korespondują z zastrzeżeniami, co do dziedziny funkcji po prawej stronie wzoru. Przykładowo we wzorze (16), musi być spełniony warunek $-1 < x < 1$, który gwarantuje zarówno istnienie w zbiorze liczb rzeczywistych wartości występującego w tym wzorze pierwiastka w mianowniku, jak też i funkcji $\arcsin$ bądź $\arccos$, choć dla nich warunek mógłby być nieco mniej restrykcyjny ($-1 \leq x \leq 1$).
Zresztą godne zwrócenia uwagi jest też alternatywne wyrażenie całek ze wzorów (16) oraz (17) poprzez, odpowiednio $\arcsin x$ bądź $\arccos x$ oraz $\arctg x$ bądź $\arcctg x$. W praktyce niemal zawsze wykorzystuje się wariant bez „arkus kofunkcji”, czyli odpowiednio $\arcsin x$ i $\arctg x$, jako, że są one bardziej „eleganckie” od swoich „kofunkcyjnych braci”, choćby ze względu na symetryczny zbiór wartości oraz rosnącą monotoniczność.
Całkowanie bezpośrednie
Odnosząc się do naszej analogii ze składaniem zegarka, zadania na całkowanie bezpośrednie, porównać można do składania zestawu, gdzie mamy złożony cały werk, a nalezy np. przykręcić cyferblat i wskazówki. Najprostszy wariant takeigo zadania, to po prostu funkcja żywcem wyjęta ze wzorów (7)–(23), ewentualnie ich suma bądź różnica z jakimiś współczynnikami. Spróbujmy zrobić kilka takich przykładów:
Zwyczajowo ctałą całkowania $C$ dopisuje się dopiero na samym końcu, choć formalnie należałoby ją pisać, gdy tylko zniknie ostatni znak całki w sumie całek. Często też całkę taką robi się bez rozpisywania explicite sumy całek, po prostu robiąc to w pamięci i zapis wygląda wówczas tak:
Czasem może się zdarzyć, że bezpośrednia całka będzie nieco bardziej „zakamuflowana”. Obliczmy całkę z takiej funkcji $f(x) = \frac {x^2 + 2} {x^2 +1}$. Funkcja ta jest funkcją wymierną, i dla takich funkcji dedykowany jest dość złożony algorytm, który będzie przedmiotem innego artykułu. W tym jednak przypadku można to rozwiązać stosunkowo prosto. Zauważmy bowiem, że:
Ten bardzo prosty przykład, to już wprowadzenie w „klimaty” całkowania, czyli przykład typowego dla obliczania całek „kombinowania na wszelkie sposoby”. Czyli obliczamy nasza całkę tak:
$$ = \int \mathrm{dx} + \int \frac {\mathrm{dx}}{x^2 + 1} = x + \arctg x + C $$
Przykład 3
Czasem, aby obliczyć całkę bezpośrednio, należy się „pobawić” w tożsamości trygonometryczne. Spróbujmy obliczyć całkę nieoznaczoną funkcji $f(x) = \tg^2(x)$. W pierwszej chwili konsternacja. Jak to, to jest całka obliczana bezpośrednio? Przecież nie ma wzoru na całkę z tangensa? Nie ma. A nawet, gdyby był, mógłby się niewiele przydać, gdyż funkcją podcałkową jest kwadrat tangensa. Ale wystarczy zrobić tak:
$$ =\int \frac {\mathrm{dx}} {\cos^2 x} - \int \mathrm{dx} = \tg x - x + C$$
A zatem obliczenie całki wymagało skorzystania z zależności pomiędzy tangensem a sinusem i cosinusem oraz z „jedynki trygonometrycznej”, dzięki której możliwe stało się przekształcenie licznika: $\sin^2 x = 1 - \cos^2 x$.
Przykład 4
Obliczmy całkę nieoznaczoną z funkcji $f(x) = \frac {\cos 2x}{\cos x - \sin x}$. Pomocny będzie tutaj wzór na cosinus podwojonego kąta: $\cos 2x = \cos^2 x - \sin^2 x$.
$$\int \frac {\cos 2x}{\cos x - \sin x} {\mathrm{dx}} = \int \frac {\cos^2 x - \sin^2 x}{\cos x - \sin x} {\mathrm{dx}} = $$
$$ = \int \frac {\cancel {(\cos x - \sin x)}(\cos x + \sin x)}{\cancel{\cos x - \sin x}} {\mathrm{dx}} = $$
$$ = \int \left(\cos x + \sin x \right)\mathrm{dx}= \sin x - \cos x + C$$
Przykład 5
A teraz „klasyka” całkowania bezpośredniego. Czyli „funkcja pseudowymierna”, tj. wyrażenie zawierające pierwiastki z $x$ oraz potęgi $x$ . Ważne by rozróżniać podobne zadania. Otóż jeśli pierwiastki są tylko z $x$ a nie z wyrażeń zawierających $x$ oraz jeśli w mianowniku jest tylko jedno wyrażenie (jakiś pierwiastek z $x$, jakaś jego potęga, czy ich iloczyn) ale nie ma tam sumy takich wyrażeń, to jest to niewątpliwie zadanie na całkowanie bezpośrednie i to przy wykorzystaniu wyłącznie „osławionego” wzoru (8) lub (9) w przypadku wystąpienia wykładnika $-1$.
W naszym przypadku niech będzie to taka funkcja:
$$f(x) = \frac {\sqrt x - 2 x \sqrt[3] {x^2} + 3 \sqrt[4] {5x^3}}{6 x \sqrt[3] x}$$
Z pozoru wygląda koszmarnie, ale wszystkie sumowane wyrażenia w liczniku są de facto potęgami $x$ a w mianowniku jest jedna tylko taka potęga. Oznacza to, że podstawowe wzory rachunku całkowego wystarczą nam w zupełności. Gdyby w mianowniku również pojawiła się jakaś suma (różnica), to poza trywialnymi przypadkami, gdzie dałoby się w liczniku wyłączyć taką samą sumę i skrócić, oznaczałoby to, że mamy do czynienia z zadaniem na całkowanie przez podstawienie, takim, jak w przykładzie 12.
Gdyby pierwiastki nie były z $x$, ale z jakichś wyrażeń, to by była już raczej wyższa – dużo wyższa – szkoła jazdy (całkowanie funkcji niewymiernych). A u nas sprawa jest prosta. należy rozbić wyrażenie podcałkowe na sumę pierwiastków o wspólnym mianowniku i dokonać uproszczeń, wykorzystując właściwości potęg.
$$ \int \frac {\sqrt x - 2 x \sqrt[3] {x^2} + 3 \sqrt[4] {5x^3}}{6 x \sqrt[3] x} \mathrm{dx} = $$
$$ \int \left( \frac {\sqrt x}{6 x \sqrt[3] x} - \frac {2 x \sqrt[3] {x^2}}{6 x \sqrt[3] x} + \frac {3 \sqrt[4] {5x^3}}{6 x \sqrt[3] x} \right) \mathrm{dx} = $$
$$ = \sqrt[6] x - \frac 1 4 x \sqrt[3] x - \frac {6 \sqrt[4] 5 } 5 \sqrt[12] {x^5} + C $$
Przykład nieco długi, ale, jeśli chodzi o wzory rachunku całkowego, rzeczywiście nie było potrzeby zastosowania innego wzoru niż (8). Powrót z potęg ułamkowych do pierwiastków nie jest bezwzględnie konieczny, choć matematyczny savoir vivre nakazuje, że jeśli dostajemy do scałkowania funkcję w postaci pierwiastków z potęg, to wypada dokonać pod koniec stosownej zamiany. Pamiętajmy, że gdyby wyszła potęga o wykładniku będącym ułamkiem niewłaściwym, to zrobilibyśmy tak: $x^{\frac 8 3} = x^2 \cdot \sqrt[3]{x^2}$.
Przykład 6
A teraz przykład, który według wcześniejszych wskazówek już nie wygląda na całkowanie bezpośrednie, ale jednak da się tam wykonac pewną prostą operację. Obliczmy całkę nieoznaczoną funkcji $f(x)=\frac {1-x}{1-\sqrt[3] x}$.
$$ = x + \frac 3 4 x \sqrt[3] x + \frac 3 5 x \sqrt[3] {x^2} + C$$
A zatem sytuację uratował tutaj wzór skróconego mnożenia. Po prostu „sztucznie” rozłożono licznik ze wzoru na różnicę sześcianów, co pozwoliło na skrócenie licznika z mianownikiem.
Całkowanie przez podstawienie
Całkowanie przez podstawienie wykonuje się, w zależności od potrzeb, w dwu wersjach. Pierwsza wersja polega na tym, że obieramy pomocniczą zmienną $t$, jako pewną funkcję zmiennej $x$, tj. podstawiamy $t=g(x)$. Należy pamiętać o dwóch żelaznych zasadach. Podstawić musimy tak, aby po podstawieniu nigdzie nie został x (ani $\mathrm{dx}$). Oprócz tego, koniecznie musimy mieć co podstawić za $\mathrm {dt}=g'(x) \mathrm{dx}$ i musi ono być w pierwszej potędze w liczniku.
Całkowanie przez podstawienie w tej wersji stosujemy wówczas, gdy jesteśmy w stanie w funkcji podcałkowej dopatrzyć się jakiejś funkcji zmiennej $x$ oraz pochodnej tej samej funkcji.
Przykład 7a
Z najbardziej banalnym przykładem zastosowania metody całkowania przez podstawienie mamy do czynienia wówczas, gdy całkujemy prostą funkcję, korzystając z podstawowych wzorów, ale argumentem nie jest $x$, ale pewne wyrażenie liniowe. Obliczmy całkę funkcji $f(x)=\sin {5x}$
zobaczmy, że nie wystarczy podstawić $t=5x$, ale trzeba mieć jeszcze co podstawić za $\mathrm{dt}$. Jako, że pochodna z $5x$ to po prostu 5, czyli różniczka $\mathrm{dt}=5\mathrm{dx}$, to sprawa jest prosta. Możemy zamiast $\mathrm{dx}$ podstawić najzwyczajniej w świecie $\mathrm{dt}$, ale trzeba jeszcze podzielić wszystko przez 5 – w praktyce, wyciągnąć $\frac 1 5$ przed całkę:
Wyrażenie liniowe może zawierać również stałą – i tak nie wystąpi ona w różniczce $\mathrm{dt}$, gdyż pochodna ze stałej wynosi zero. Policzmy całkę nieoznaczoną z takiej funkcji: $f(x) = \cos (2x - 5)$:
Bystry Czytelnik zauważy analogię z pochodną funkcji złożonej. Przykładowo $\left[\sin 3x \right]'= 3 \cos 3x$. Przy wyliczaniu pochodnej się po prostu mnożyło przez pochodną funkcji wewnętrznej, a tutaj się dzieli. Spostrzeżenie trafne, ale słuszne tylko dla argumentów będących wyrażeniami liniowymi. Rzeczywiście w przypadku, gdy argumentem funkcji nie jest $x$, ale wyrażenie typu $ax+b$, wystarczy policzyć całkę, dla tego samego argumentu i podzielić ją przez $a$. Jest to tak dalece powszechne, że na pewnym etapie nauki całkowania, wykonuje się to w pamięci, bez formalnego rozpisywania podstawień.
Niestety, ten prosty schemat nie działa, gdy argumentem jest coś bardziej skomplikowanego aniżeli wyrażenie liniowe. Na przykład całki $\int \sin {x^2} \mathrm{dx}$ nie da się wyliczyć, jako $-\cos {x^2}$ i podzielić przez $2x$. Nawiasem mówiąc, jak wspomniano na początku artykułu, na całkę $\int \sin {x^2} \mathrm{dx}$ nie działa żadna metoda. Nie da się jej wyrazić za pomocą funkcji elementarnych.
Przykład 8
Co innego jednak, jeśli funkcja podcałkowa będzie taka, że „na talerzu” dostaniemy coś, w czym będziemy w stanie „upchnąć” nasze $\mathrm {dt}$. Weźmy funkcję bardzo podobną, to wspomnianej wyżej funkcji mającej całkę nieoznaczoną niedającą się wyrazić poprzez funkcje elementarne. Obliczymy bowiem teraz całkę nieoznaczoną z funkcji $f(x) = x \sin {x^2}$. Mały szczegół, a zmienia wszystko:
$$\int x \sin x^2 \, \mathrm{dx} = ...$$
$$\left | \begin{array}{l} t = x^2 \\ \mathrm{dt}=2x \mathrm{dx} \\ x \mathrm{dx} = \frac {\mathrm{dt}} 2 \end{array} \right. $$
Widzimy co się stało. Niepozorny $x$ uratował nam… skórę. Oto bowiem mamy co podstawić za $\mathrm{dt}$. I teraz będzie już prosto:
Czasem trzeba spojrzeć nieco szerzej i, jak to z całkami bywa, nieco „przycwaniakować”. Obliczmy całkę z takiej funkcji: $f(x) = \frac x {x^4 + 1}$. Pierwsze, co byśmy chcieli zrobić, to podstawić za $t=x^4$ albo nawet cały mianownik: $t=x^4 + 1$. Jednak to nie wypali, gdyż w obu przypadkach różniczka: $\mathrm{dt}=4x^3 \mathrm{dx}$. Nie mamy co za to $\mathrm{dt}$ podstawić. Tutaj trzeba chytrzej:
$$\int \frac x {x^4+1} \mathrm{dx} = ...$$
$$\left | \begin{array}{l} t = x^2 \\ \mathrm{dt}=2x \mathrm{dx} \\ x \mathrm{dx} = \frac {\mathrm{dt}} 2 \end{array} \right. $$
Czasem więc funkcji podstawianej pod $t$ nie widać od razu. Trzeba ją sobie starannie „wyłuskać” z wyrażenia podcałkowego. Można też tu było pomyśleć od drugiej strony: mam $x$ w liczniku, a on jest pochodną (ok, połową pochodnej) z $x^2$, a zatem może z $x^2$ coś się da zawalczyć? I dokładnie tak trzeba myśleć. Wielomiany często pojawiają się w zadaniach na całki i trzeba pamiętać, że pochodną wielomianu stopnia $n$ jest wielomian stopnia $n-1$.
Przykład 10
To też szalenie prosty przykład i zastanawiałem się, czy nie nadać mu numeru 9b. Policzmy całkę nieoznaczoną funkcji: $f(x) = \frac {x^3} {x^4 + 1}$
Zapamiętania warte jest tutaj zastąpienie pod koniec obliczeń, znaku wartości bezwzględnej zwyczajnym nawiasem. Uczyniono tak dlatego, że wyrażenie $x^4+1$ jest zawsze dodatnie, toteż nie ma potrzeby ujmowania go w znak modułu. Gdybyśmy tego nie zrobili, rozwiązanie również byłoby poprawne, ale nieeleganckie. Akademiccy nauczyciele matematyki zwracają uwagę na elegancję. Zastąpienie modułu nawiasem, to takie „postawienie kropki nad i”, ostateczny szlif. A także dowód na to, że rozwiązujący zadanie student wie, co robi.
Przykład 11
Teraz policzmy całkę nieoznaczoną takiej funkcji: $f(x) = \frac {x^3}{x+1}$.
$$\int \frac {x^3}{x+1} \mathrm{dx} = ...$$
$$\left | \begin{array}{l} t = x + 1 \\ \mathrm{dt}= \mathrm{dx} \\ x = t - 1 \end{array} \right. $$
Zaczęło się zatem tak samo, ale tym razem w oparciu o podstawienie dla $t$, przeliczono wartość zmiennej $x$. Co to dało? Bardzo dużo! Otóż podstawienie takie, pozwala wyeliminować z mianownika kłopotliwą sumę:
Uważny Czytelnik może zadać w tym momencie pytanie, co się stało z liczbą $\frac {11} 6$, która jest widoczna w przedostatnim przekształceniu, a nie widać jej w końcowym wyniku? Otóż wartośc $\frac {11} 6$, jako stała, została pochłonięta przez stałą całkowania $C$. Skoro $C$ jest dowolną liczbą rzeczywistą, to zamiast pisać $\frac {11} 6 + C$ wystarczy zapisać3 $C$. Pochłanianie stałej liczbowej przez stałą całkowania, to normalna praktyka rachunku całkowego.
Przykład 11 pozwolił nam „gładko” przejść do drugiego typu całkowania przez podstawienie, a mianowicie do podstawień postaci $x = g(t)$, $\mathrm{dx}=g'(t) \mathrm{dt}$.
Przykład 12
Obliczmy całkę nieoznaczoną funkcji $f(x) = \frac 1{\sqrt x + \sqrt[3] x}$. Nie da się tutaj wykorzystać metod podstawowych, z uwagi na to, że pierwiastki są w mianowniku.
„Chwyt”, jaki w takim wypadku się stosuje, polega na podstawieniu za zmienną $x$, nowej zmiennej $t$ w potędze będącej najmniejszą wspólną wielokrotnością (czyli takim, jakby, wspólnym mianownikiem) występujących w wyrażeniu mianowników wykładników. U nas pojawiają się wykładniki $\frac 1 2$ oraz $\frac 1 3$, toteż wspólnym mianownikiem jest $6$.
$$\left | \begin{array}{l} x = t^6 \\ \mathrm{dx}= 6t^5 \mathrm{dt} \\ t = x^{\frac 1 6} = \sqrt[6] x \end{array} \right. $$
Zauważmy, że na ostatniej pozycji napisaliśmy „podstawienie zwrotne”, czyli ile równa się $t$ w funkcji $x$ po to, by pod koniec obliczania całki powrócić do oryginalnej zmiennej $x$. Zatem:
Jest to funkcja wymierna. Całkowaniem funkcji tego typu, „na poważnie”, zajmiemy się w osobnym artykule. tutaj spróbujemy te funkcję scałkować troszkę po partyzancku, ale skutecznie.
Spróbujmy po raz kolejny zastosowac podstawienie, w stylu podobnym co przykładu 11.
$$\left | \begin{array}{l} u = t + 1 \\ \mathrm{du}= \mathrm{dt} \\ t = u - 1 \end{array} \right. $$
$$... = 6 \int \frac{\left(u-1 \right)^3\,\mathrm{du}} u = 6 \int \frac{\left(u^3 - 3u^2 + 3u -1 \right)\,\mathrm{du}} u = $$
$$=2\sqrt x - 3\sqrt[3]x + 6\sqrt[6] x - 6\ln \left(\sqrt[6] x+1 \right) + C$$
Tutaj również stała $11$ została pochłonięta przez stałą całkowania. Wyrażenie $\sqrt[6]x + 1$ jest zawsze dodatnie (dziedziną wyjściowej całki jest oczywiście $\mathbb R_+$), więc można było zamienić znak modułu przy logarytmie naturalnym na zwykły nawias.
Jak widać, do rozwiązania doprowadziło nas aż dwukrotne zastosowanie całkowania przez podstawienie, przy czym pierwsze z tych podstawień było w stylu $x = g(t)$, a drugie w stylu $t=g(x)$ (w naszym przypadku $u=g(t)$).
Przedstawione przykłady nie wyczerpują wszystkich sztuczek, chwytów i pomysłów na podstawienia. W kolejnych artykułach, poświęconych całkowaniu szczególnych funkcji (wymiernych, niewymiernych, trygonometrycznych, itd), poznamy różne podstawienia niejako „dedykowane” do całkowania konkretnych funkcji. Niektóre z nich są owocem pracy najtęższych matematycznych umysłów drugiego tysiąclecia naszej ery, takich jak Euler czy Bernoulli.
Całkowanie analityczne to wciąż dziedzina, gdzie być może i Ty, drogi Czytelniku, pozostawisz swój wkład i swoje nazwisko. Dziś analityczne całkowanie nie jest może już tak ważne jak choćby sto lat temu – sporo całek można wyliczyć – i to również analitycznie – programami komputerowymi, jal np. Wolfram Mathematica, ale ciekawe podstawienie do scałkowania „ręcznego” jakiejś skomplikowanej funkcji, być może, czeka jeszcze na odkrycie. To tak jak z szachami. Niby wszystko o tej grze już napisano i opracowano, a wciąż odkrywane są nowe ruchy czy otwarcia.
Całkowanie przez części
O ile wskazaniem do zastosowania metody całkowania przez podstawienie jest „dopatrzenie się” w funkcji podcałkowej pewnej funkcji oraz jej pochodnej, o tyle metodę całkowania przez części można próbować zastosować, gdy w funkcji podcałkowej dopatrzymy się iloczynu dwu różnych funkcji.
Gdy już dopatrzymy się iloczynu tych funkcji, we wzorze oznaczonych literami $u$ i $\mathrm{dv}$, zauważamy, że z pierwszej z nich, czyli z $u$ w dalszym toku obliczeń obliczać będziemy pochodną (różniczkę), natomiast z drugiej $\mathrm{dv}$, samej będącej różniczką, obliczać będziemy (zazwyczaj w pamięci) funkcję pierwotną (czyli całkę nieoznaczoną).
Po prawej stronie wzoru występuje całka $\int v \mathrm{du}$. Chodzi o to, by całka ta była prostsza do obliczenia aniżeli całka wyjściowa. Zazwyczaj dzieje się tak w wyniku tego, że po obliczeniu całki bądź pochodnej, funkcje są prostsze, bądź też nastąpi jakieś uproszczenie wyrażenia. Czasem też sytuacja rozwinie się jeszcze inaczej, co prześledzimy na przykładach.
Mnożenie jest przemienne, więc to od nas zależy, którą z funkcji obierzemy, jako $u$, a którą, jako $\mathrm{dv}$. Jednak pomóc tutaj mogą pewne spostrzeżenia. Otóż niektóre funkcje, jak np. wielomiany, upraszczają się w wyniku różniczkowania oraz komplikują w wyniku całkowania. Zazwyczaj będa one idealnymi kandydatami na $u$, bowiem w całce po prawej stronie wystąpią już jako $\mathrm{du}$. Są też funkcje, które przeciwnie – komplikują się przy różniczkowaniu, a upraszczają przy całkowaniu. Np funkcja $\frac 1 x$. Tego typu funkcje mogą być ewentualnie rozważane, jako kandydatki na $\mathrm{dv}$.
Są wreszcie funkcje, którym niestraszne ani całkowanie, ani różniczkowanie i moga one być w ten sposób przekształcane nawet setki razy. Te funkcje to $\e^x$, $\sin x$ oraz $\cos x$. One z powodzeniem mogą „robić” z jednakowym skutkiem zarówno za $u$, jak i za $\mathrm{dv}$.
Przykład 13
Obliczmy całkę nieoznaczoną funkcji $f(x) = x \cdot \sin x$. Tutaj nie powinniśmy mieć wątpliwości, co jest naszym $u$, a co $\mathrm{dv}$. Sinusowi jest wszystko jedno, ale metoda całkowania przez części dobrze spełni swoją rolę, gdy $x$ podstawimy za $u$.
$$\int x \sin x \mathrm{dx} = ...$$
$$\left| \begin{array}{ll} u = x & \mathrm{du}=\mathrm{dx} \\ v = -\cos x & \mathrm{dv} = \sin x \, \mathrm{dx} \end{array} \right.$$
$$.. = -x \cos x - \int \left(-\cos x \right) \mathrm{dx} = $$
$$ = -x \cos x + \int \cos x \, \mathrm{dx} =- x \cos x + \sin x + C$$
Widzimy, o co chodzi? Dzięki metodzie całkowania przez części, nasz $x$ zniknął sprzed funkcji trygonometrycznej.
Czasem trzeba wykazać się cierpliwością i „zbijać” kolejno potęgi niechcianego „iksa”, stosując metodę całkowania przez części kilkakrotnie.
Przykład 14
Policzmy całkę funkcji $f(x) = x^3 \e^{2x}$. Oczywiście znów funkcji $\e^x$ jest wszystko jedno, jaką rolę obierze, ale $x^3$ upraszczać się będzie pod warunkiem, że podstawimy je za $u$. Tutaj należy zwrócić uwagę na jeszcze jedną rzecz. Naszym $\mathrm{dv}$ będzie $\e^{2x}$, a więc funkcja złożona. Wyliczając z niej $v$, całkujemy ją niejako w pamięci. Formalnie należałoby zrobić to „na boku”, wykorzystując całkowanie przez podstawienie, ale wspomnieliśmy w przykładzie 7b, że w przypadku, gdy funkcją wewnętrzną jest funkcja liniowa, to można scałkować w pamięci, dzieląc całkę przez współczynnik przy zmiennej.
Teraz pokażemy dwa przykłady z absolutnego kanonu całkowania przez części. Nie da się nauczyć kogoś tej metody, nie pokazując mu tych dwu nietypowych przypadków. Jeden lekko nietypowy, drugi bardziej.
Przykład 15
Obliczyć całkę nieoznaczoną z funkcji $f(x) = \ln x$. Uważny czytelnik pewnie zauważył, że nie ma całki z tej funkcji wśród wzorów rachunku całkowego. Ten sam Czytelnik pewnie też zdziwi się, dlaczego obliczanie tej całki ma być wykonane metodą całkowania przez części, skoro na wstępie napisaliśmy, że stosujemy je, gdy w funkcji podcałkowej dopatrzymy się dwu funkcji, a tutaj jest tylko jedna. Czy aby na pewno jedna? Wyrażenie za znakiem $\int$ jest rózniczką, a zatem iloczynem pochodnej funkcji pierwotnej oraz $\mathrm{dx}$.
I to jest właśnie punkt wyjścia, do obliczenia całki z logarytmu naturalnego. Traktujemy funkcję podcałkową, jako iloczyn $\ln x$ oraz $\mathrm{dx}$. Jeśli chodzi o wybór $u$ oraz $\mathrm{dv}$, to nie może być inaczej. Logarytm musi zostać $u$, gdyż jego pochodną jest zwyczajne $\frac 1 x$. Gdyby został $\mathrm{dv}$ mielibyśmy klasyczne „masło maślane” – aby wyznaczyć $v$ trzeba byłoby wszak scałkować ten logarytm, a przeciez właśnie po to całkujemy przez części. Ale do rzeczy:
$$\int \ln x \,\mathrm {dx} = ...$$
$$\left| \begin{array}{ll} u = \ln x & \mathrm{du}=\frac {\mathrm{dx}} x \\ v = x & \mathrm{dv} = \mathrm{dx} \end{array} \right.$$
$$ ... = x \ln x - \int {\cancel x} \cdot \frac {\mathrm {dx}} {\cancel x} = x \ln x - \int {\mathrm {dx}} =$$
$$ = x \ln x - x = x \left( \ln x - 1 \right) + C$$
Kto by pomyślał, że w taki sposób można scałkować logarytm naturalny? W analogiczny sposób całkuje się takie funkcje, jak $\arctg x$ czy $\arcsin x$.
Przykład 16
Obliczyć całkę funkcji $f(x) = \e^x \sin x$. Tutaj spotyka się dwoje „najtwardszych zawodników” rachunku różniczkowego i całkowego. Obie funkcje mogą w obie strony być przekształcane nieskończenie wiele razy. $\e^x$ pozostanie w swojej postaci, a $\sin x$ będzie zamieniał się cyklicznie w $\cos x$ i jeszcze dojdą zmiany znaku. Obie funkcje są doskonałymi kandydatami zarówno na $u$, jak i na $\mathrm{dv}$. Przyjmijmy, że jako $u$ obierzemy funkcję $\e^x$, a jako $\mathrm{dv}$ obierzemy $\sin x \mathrm{dx}$.
$$\int \e^x \sin x \mathrm{dx} = ...$$
$$\left| \begin{array}{ll} u = \e^x & \mathrm{du}=\e^x {\mathrm{dx}} \\ v = -\cos x & \mathrm{dv} = \sin x \,\mathrm{dx} \end{array} \right.$$
$$... = -\e^x \cos x -\int \left(-\e^x \cos x \right) \mathrm{dx} = -\e^x \cos x +\int \e^x \cos x \mathrm{dx} =...$$
Po raz kolejny stosujemy więc całkowanie przez częsci. Tutaj drobna podpowiedź: aby wyszedł nam sensowny wynik, musimy być konsekwentni. Skoro jako $u$ obraliśmy funkcję wykładniczą, to musimy tak zrobić i teraz:
$$\left|\left| \begin{array}{ll} u = \e^x & \mathrm{du}=\e^x {\mathrm{dx}} \\ v = \sin x & \mathrm{dv} = \cos x \,\mathrm{dx} \end{array} \right.\right.$$
$$... -\e^x \cos x +\e^x \sin x - \int \e^x \sin x \mathrm{dx} $$
Początkujący może w tym momencie się załamać. Zapytać, ile jeszcze razy trzeba powtórzyć operację i czy są szanse na koniec w tym stuleciu. Otóż to już jest (prawie) koniec. Zazwyczaj, gdy całkując kilkakrotnie przez części, otrzymamy ponownie wyjściową całkę, świadczy to o tym, że coś poszło nie tak. Ale nie tutaj. W tym przypadku „ratuje nas” znak minus.
Zreasumujmy, co właściwie otrzymaliśmy. Otrzymaliśmy mianowicie:
$$\int \e^x \sin x \mathrm{dx} = -\e^x \cos x +\e^x \sin x - \int \e^x \sin x \mathrm{dx}$$
Teraz tylko wystarczy przenieść całkę z prawej strony na lewą, podzielić stronami przez 2 i uprościć:
$$2\int \e^x \sin x \mathrm{dx} = \e^x \sin x -\e^x \cos x /:2 $$
$$\int \e^x \sin x \mathrm{dx} = \frac 1 2 \e^x \left(\sin x -\e^x \cos x \right) + C $$
Tak więc nie zawsze całkowanie przez częsci (i ogólnie całkowanie) musi wyglądać tak, że po iluś tam przekształceniach otrzymujemy wynik. Czasem wynik dostajemy, tak jak tutaj, w niestandardowy sposób.
Przykład 17
A teraz troszke „zabawy”. Policzmy, róznymi metodami, całkę nieoznaczoną z funkcji $f(x) = \sin x \cos x$.
Na wstępie zauwazmy, że cosinus jest pochodną sinusa i vice versa (pomijając kwestię minusa). Wobec tego już samą metodą całkowania przez podstawienie można zadanie wykonać na dwa sposoby.
Sposób 1
$$\int \sin x \cos x \, \mathrm{dx} = ...$$
$$\left | \begin{array}{l} t = \sin x \\ \mathrm{dt}= \cos x \, \mathrm{dx} \end{array} \right. $$
$$... = \int t \, \mathrm{dt} = \frac {t^2} 2 = \frac 1 2 \sin^2 x + C$$
Sposób 2
$$\int \sin x \cos x \, \mathrm{dx} = ...$$
$$\left | \begin{array}{l} t = \cos x \\ \mathrm{dt}= -\sin x \, \mathrm{dx} \\ \sin x \, \mathrm{dx} - -\mathrm{dt}\end{array} \right. $$
$$... = -\int t \, \mathrm{dt} = -\frac {t^2} 2 = -\frac 1 2 \cos^2 x + C$$
Ciekawe, że innym sposobem wyszedł inny wynik. Czy jednak na pewno jest on inny? Zajmiemy się tym później. Teraz policzymy całkę tę dwukrotnie za pomoca całkowania przez części.
Sposób 3
$$\int \sin x \cos x \, \mathrm{dx} = ...$$
$$\left| \begin{array}{ll} u = \sin x & \mathrm{du}=\cos x {\mathrm{dx}} \\ v = \sin x & \mathrm{dv} = \cos x \,\mathrm{dx} \end{array} \right.$$
$$... = \sin x \cdot \sin x -\int \sin x \cos x \mathrm{dt} = \sin^2 x -\int \sin x \cos x \mathrm{dt}$$
Otrzymaliśmy więc, na podobnej zasadzie, jak w przykładzie 16:
$$\int \sin x \cos x \, \mathrm{dx} = \sin^2 x -\int \sin x \cos x \mathrm{dt}$$
skąd:
$$2 \int \sin x \cos x \, \mathrm{dx} = \sin^2 x /:2$$
$$\int \sin x \cos x \, \mathrm{dx} =\frac 1 2 \sin^2 x + C$$
Sposób 4
Teraz $u$ oraz $\mathrm{dv}$ obierzemy na odwrót.
$$\int \sin x \cos x \, \mathrm{dx} = ...$$
$$\left| \begin{array}{ll} u = \cos x & \mathrm{du}= -\sin x {\mathrm{dx}} \\ v = -\cos x & \mathrm{dv} = \sin x \,\mathrm{dx} \end{array} \right.$$
$$... = -\cos x \cdot \cos x -\int \sin x \cos x \mathrm{dt} = -\cos^2 x -\int \sin x \cos x \mathrm{dt}$$
Czyli:
$$\int \sin x \cos x \, \mathrm{dx} = -\cos^2 x -\int \sin x \cos x \mathrm{dt}$$
skąd:
$$2\int \sin x \cos x \, \mathrm{dx} = -\cos^2 x /:2$$
$$\int \sin x \cos x \, \mathrm{dx} = -\frac 1 2 \cos^2 x +C $$
Sposób 5
Tutaj skorzystamy z całkowania bezpośredniego. Użyjemy bowiem wzoru na sinus podwojonego kąta: $\sin {2 \alpha} = 2 \sin \alpha \cdot \cos \alpha$. Ze wzoru tego wynika, że: $\sin x \cos x = \frac 1 2 \sin {2x}$.
$$= -\frac 1 4 \left( \cos^2 x - \sin^2 x \right) = \frac 1 4 \sin^2 x - \frac 1 4 \cos^2 x + C $$
Licząc pięcioma sposobami, otrzymaliśmy w sumie trzy różne wyniki:
$$\int \sin x \cos x \, \mathrm{dx} =\frac 1 2 \sin^2 x + C$$
$$\int \sin x \cos x \, \mathrm{dx} = -\frac 1 2 \cos^2 x +C $$
$$\int \sin x \cos x \, \mathrm{dx} = \frac 1 4 \sin^2 x - \frac 1 4 \cos^2 x + C $$
O co tutaj chodzi?
Policzmy różnicę pomiędzy pierwszym a drugim z otrzymanych wyników (pomijajac ctałą $C$):
$$\frac 1 2 \sin^2 x - \left(-\frac 1 2 \cos^2 x \right) = \frac 1 2 \sin^2 x + \frac 1 2 \cos^2 x = $$
$$\frac 1 2 \left(\sin^2 x + \cos^2 x \right) = \frac 1 2 \cdot 1 = \frac 1 2 $$
A zatem wynik otrzymany sposobami (1) oraz (3)różni się od wyniku otrzymanego sposobami (2) oraz (4)o stałą (w tym wypadku o $\frac 1 2$). Całki nieoznaczone różniące się o stałą wyrażają tę samą całkę! Policzmy jeszcze różnicę pomiędzy całką otrzymaną sposobami (1) oraz (3) a całką otrzymaną sposobem (5):
$$\frac 1 2 \sin^2 x -\left( \frac 1 4 \sin^2 x - \frac 1 4 \cos^2 x \right) =$$
$$\frac 1 2 \sin^2 x - \frac 1 4 \sin^2 x + \frac 1 4 \cos^2 x $$
$$= \frac 1 4 \sin^2 x + \frac 1 4 \cos^2 x =\frac 1 4 \left(\sin^2 x + \cos^2 x \right) = \frac 1 4 \cdot 1 = \frac 1 4$$
A zatem otrzymane trzy wyniki tylko pozornie, na pierwszy rzut oka, są inne. W rzeczywistości, jako że różnią się o stałą, wyrażają one tę samą funkcję pierwotną, a zatem tę całkę nieoznaczoną.
Warto podkreślić, że tylko w przypadku nielicznych całek, takich jak ta, będąca przedmiotem przykładu 17, można wybierać i przebierać w metodach całkowania. Na ogół do danej całki „pasuje” tylko jedna metoda i to my sami musimy wpaść na to, jaką metodę zastosować.
Do zobaczenia w kolejnej części
To pierwszy z artukułów o całkowaniu. Przedstawione zostały w nim podstawowe narzędzia, jakimi są wzory rachunku całkowego oraz dwie kluczowe metody całkowania: całkowanie przez podstawienie, zwane też całkowaniem przez zamianę zmiennej, oraz całkowanie przez części. W zasadzie nie istnieją inne metody, ale dla pewnych klas funkcji, w oparciu o te metody, zdefiniowano określone algorytmy postepowania, mówiące, jak użyć tych metod, aby wyznaczyć funkcję pierwotną (całkę nieoznaczoną).
Od studenta kierunków niematematycznych, czyli np. studiów politechnicznych, wymaga się najczęściej znajomości procedury całkowania funkcji wymiernych, niektórych funkcji niewymiernych (np. zawierających pierwiastek z trójmianu kwadratowego), całkowania niektórych funkcji przestępnych – np. całek funkcji będących złożeniami wielomianów bądź funkcji wymiernych z funkcjami trygonometrycznymi.
Aspirujacy do samodzielnego zaliczenia, na ocenę dostateczną, kursu matematyki wyższej student, powinien przynajmniej znać omówione w tym artykule metody i potrafić ich używać, a także potrafić całkować funkcje wymierne, co będzie tematem kolejnego artykułu z dziedziny rachunku całkowego.
Sebastian Dziarmaga-Działyński
O ile funkcję podcałkową można wyrazić za pomocą szeregu potęgowego, to szereg taki można scałkować stosunkowo łatwo (jak wielomian), ale efekt całkowania musiał będzie pozostać w takiej formie, czyli w formie nieskończonej sumy, więc w kontekście analitycznego (tj. przeprowadzanego na symbolach) całkowania funkcji się to „nie liczy”. ↩︎
To definicja książkowa. W praktyce, ciągłość w stosownym przedziale wymagana jest dla całki oznaczonej, natomiast dla całki nieoznaczonej najlepiej by było, gdyby funkcje te były ciągłe w swoich dziedzinach, ewentualnie w jakiejś dziedzinie danej stosownym założeniem (np. przez autora zadania). ↩︎
Niektórzy w takiej sytuacji, zamiast $C$ napisaliby $C_1$, definiując: $C_1 = \frac {11} 6 + C$. To oczywiście też poprawne i eleganckie. Moim zdaniem zbyt eleganckie. ↩︎
Pochodna funkcji
mgr inż
Sebastian Dziarmaga-Działyński
Wprowadzenie
Pochodna funkcji to bodaj najważniejsze pojęcie analizy matematycznej, nie licząc oczywiście samego pojęcia funkcji. Umiejętność obliczania pochodnych jest bardzo ważna i stosunkowo prosta do opanowania. Wprawne posługiwanie się rachunkiem różniczkowym, bo taką nazwę nosi obliczanie pochodnych, jest niezbędne, by opanować innego rodzaju działanie, jakim jest całkowanie nieoznaczone, czemu poświęcony zostanie inny artykuł.
Formalna definicja pochodnej
Pochodną definiuje się, jako granicę ilorazu różnicowego, przy przyroście argumentu funkcji dążącym do zera. Można to sformułować jeszcze prościej, jest to po prostu stosunek przyrostu wartości funkcji, do przyrostu argumentu, gdy przyrost tego argumentu jest nieskończenie mały.
Pod warunkiem, że granica ta istnieje (w szczególności ewentualne granice: lewostronna i prawostronna są jednakowe) i jest skończona. Jeśli tak jest, to funkcję $f(x)$ nazywamy funkcją różniczkowalną w punkcie $x_0$. Wyrażenie, z którego obliczana jest granica (1), to właśnie iloraz różnicowy funkcji $f(x)$.
Wartość pochodnej funkcji $f(x)$ w punkcie $x_0$, co oznaczamy, jako $f'(x_0)$, jest równa współczynnikowi kierunkowemu stycznej do wykresu funkcji w punkcie $x_0$. Tj. styczna ta jest prostą o równaniu: $y = ax + b$; wówczas $a = f'(x_0)$.
Rysunek 1. Pochodna, jako styczna do wykresu funkcji w punkcie $x_0$.
Na rysunku 1 widzimy sieczne do wykresu pewnej funkcji (jest to przykładowa funkcja rosnąca i wypukła). Jedna z siecznych przechodzi przez punkty o odciętych $x_0-h$ oraz $x_0$, a druga przez punkty o odciętych $x_0$ oraz $x_0 + h$. Sieczne te, odpowiadają wartości ilorazu różnicowego funkcji w punkcie $x_0$, dla przyrostu argumentu wynoszącego $h$.
Gdy $h$ dąży do zera, wówczas obie sieczne „schodzą” się, tworząc styczną. Rzędna tej stycznej, to wartość funkcji w tym punkcie. Jest ona przy tym równa współczynnikowi kierunkowemu stycznej, który z kolei równy jest tangensowi kąta nachylenia stycznej i równy pochodnej:
$$\tg \alpha = f'(x_0) $$
Innym sposobem oznaczania pochodnej jest operator różniczkowania: $\frac {df} {dx}$. W przypadku, gdy zmienną funkcji jest czas ($t$), zwłaszcza w fizyce, zamiast oznaczać pochodną znakiem „prim” $'$, zaznacza się ją symbolem kropki: $\dot x(t)$. Jeśli funkcja jest funkcją wielu zmiennych, to obliczana pochodna po wybranej zmiennej zwana jest pochodną cząstkową i wówczas operator różniczkowania wygląda w taki sposób: $\frac {\partial f} {\partial x}$.
Przykład 1
Korzystając z definicji pochodnej funkcji w punkcie, obliczyć wartość pochodnej funkcji $f(x) = x^2 + 2x - 5$ w punkcie $x_0 = 1$.
Zadanie rozwiążemy na dwa sposoby. W pierwszej kolejności skupimy się tylko na treści polecenia i obliczymy wartość pochodnej ww wskazanym punkcie , natomiast drugi sposób polegał będzie na tym, że wyznaczymy postać pochodnej $f'(x)$, jako funkcję i obliczymy wartość tej funkcji w punkcie $x=1$.
Skrócenie $h$ w mianowniku z licznikiem jest kluczowym momentem i powinien się zawsze pojawić. Dzięki temu możliwe staje się podstawienie w miejsce $h$ wartości zero, co było niemożliwe wówczas, gdy $h$ znajdowało się w mianowniku.
Pochodna, jako funkcja
Zamiast wyznaczać wartość pochodnej funkcji w punkcie, z wykorzystaniem wzoru (1), można za jego pomocą wyliczyć ogólną postać funkcji. Pochodna bowiem jest funkcjonałem, czyli odwzorowaniem, które jednej funkcji przyporządkowuje inną funkcję.
Rysunek 1. Pochodna, jako funkcjonał
Mówiąc prostym językiem, pochodna to taka operacja, która z jednej funkcji „robi” inną funkcję.
Wyłączenie $h$ przed nawias spowodowało, że możliwe stało się skrócenie $h$ w liczniku i mianowniku, co pozwoliło podstawić za $h$ zero. Otrzymaliśmy więc:
$$f'(x) = 2x + 2$$
Do kanonu „klasyki” zadań polegających na wyznaczaniu pochodnej z definicji, czyli według wzoru (2), należy jeszcze wyznaczanie pochodnej z pierwiastka kwadratowego, oraz prostej funkcji wymiernej.
Przykład 2
Wyznaczyć pochodną funkcji $f(x) = \sqrt x$ z definicji.
W przypadku zadania z pierwiastkiem, wykorzystujemy „sztuczkę” polegającą na rozszerzeniu ułamka przez „wyrażenie „sprzężenie”, czyli wyrażenie zawierające sumę pierwiastków, zamiast ich różnicy, dzięki czemu możliwe staje się skorzystanie ze „wzoru skróconego mnożenia”.
$$= \lim_{h \to 0} \frac { \left( \sqrt {x+h} - \sqrt x \right) \cdot \left(\sqrt {x+h} + \sqrt x \right)} {h \cdot \left(\sqrt {x+h} + \sqrt x \right)} = $$
$$= \lim_{h \to 0} \frac { x + h - x} {h \cdot \left(\sqrt {x+h} + \sqrt x \right)} = \lim_{h \to 0} \frac {\cancel h} {\cancel{h} \cdot \left(\sqrt {x+h} + \sqrt x \right)} = $$
Tym razem sprawa nie jest taka prosta. Nie jest możliwe wykonanie odejmowania w liczniku bez poczynienia pewnych założeń. Znak modułu $| |$ działa jak nawias, skutecznie „separując oba wyrażenia. Musimy sie go „pozbyć”. Wartość bezwzględna, jak wiadomo, to funkcja określona następująco:
$$f(x) = \left\{ \begin{array} {lcr} \ x & \text{dla} & x \geq 0 \\ -x & \text{dla} & x < 0 \end{array} \right.$$
Chcąc opuścić znak modułu, należy rozpatrzyć kilka przypadków. A dokładniej – trzy przypadki.
przypadek nr 1
$x < 0$
Gdy $x$ jest liczbą ujemną, wówczas również $x+h$ jest taką liczbą, gdyż $h$ dąży do zera. Zatem można opuszczając wartość bezwzględną, zmienić znak wyrażenia na przeciwny. Czyli potraktować wartość bezwzględną, jak zwyczajny nawias, ale zmieniając przed nim znak:
$$... = \lim_{h \to 0} \frac { -(x + h) + x} h = \lim_{h \to 0} \frac { \cancel{-x} - h + \cancel{x}} h = $$
Zatem, dla $x < 0$ mamy $f'(x) = -1$, co możemy też zapisać, jako $\left( |x| \right)' = -1$.
przypadek 2
$x > 0$
W zasadzie, trzymając się kolejności, przypadek 2 powinien zakładać $x=0$, jednak ten najciekawszy przypadek zostawimy na koniec. Gdy $x$ jest dodatnie, wówczas $x+h$ jest także dodatnie i opuszczamy wartość bezwzględną bez zmiany znaku:
$$... = \lim_{h \to 0} \frac { \cancel x + h - \cancel x} h = \lim_{h \to 0} \frac { \cancel h}{\cancel h} = 1$$
W tym wypadku mamy problem o ile z wyrażenia $|x|$ możemy śmiało „zdjąć” wartość bezwzględną, przy czym nie ma znaczenia, czy zmienimy znak na przeciwny, czy nie (wszak $-0 = 0$), to z wyrażeniem $x+h$ mamy problem. Liczymy granicę, dla $h \to 0$, ale $h$ może do zera dążyć z obu stron. Jeśli $x$ jest dokładnie zerem, to nawet dla „mikroskopijnie” małego, ujemnego $h$ wyrażenie $x+h$ też będzie ujemne.
Nie mamy wyjścia, musimy osobno policzyć granice jednostronne! Ponieważ założyliśmy, że $x=0$, to możemy od razu za $x$ tę wartość po prostu podstawić.
Teraz już widać, dlaczego tak się dzieje. W punkcie o odciętej $x=0$ nie da się przyłożyć stycznej do wykresu funkcji. Na lewo i na prawo od zera, styczna pokrywa się z wykresem. Na lewo od zera, kąt nachylenia stycznej wynosi $-45^{\circ}$, czyli $\alpha = -\frac \pi 4$, zatem $\tg \alpha = -1$, a na prawo oczywiście $\alpha = 45^{\circ} = \frac \pi 4$, zatem $\tg \alpha = 1$, ale w zerze stycznej brak!
Czasem pochodna nie istnieje z troszkę innego powodu. W przykładzie 2, wyznaczyliśmy pochodną z pierwiastka kwadratowego. Uzyskaliśmy tam wynik: $\left( \sqrt x \right)' = \frac 1 {2 \sqrt x}$. Zauważmy, że $x=0$ należy do dziedziny naszej funkcji, i mamy $\sqrt 0 = 0$, ale $f'(0)$ nie istnieje. Rzut oka na wykres funkcji pozwala stwierdzić, dlaczego tak się dzieje.
Rysunek 3. Wykres funkcji $f(x) = \sqrt x$
Tym razem, pomijając kwestię „urwania” się wykresu, spowodowanego ograniczoną dziedziną funkcji $\sqrt x$, to styczna do wykresu funkcji dla $x=0$ jest prostą pionową, czyli $\alpha = \pm 90^{\circ} = \pm \frac \pi 2$, czyli $\tg \alpha$ nie istnieje.
Obliczanie pochodnej ze wzoru
W rzeczywistości, obliczanie pochodnej z definicji traktuje się, jako „sztukę dla sztuki”. Poza zadaniami na kolokwium, czy egzaminie, w zasadzie się z tego nie korzysta. W praktyce korzysta się z „gotowców”, czyli ze wzorów rachunkuróżniczkowego. Wzory te podzielić można dwie grupy: wzorów wyrażających ogólne, „rachunkowe” własności1 pochodnych oraz wzorów na pochodne konkretnych funkcji.
Wzór (3) oznacza, że stałą można „wyłączyć” przed pochodną, czyli tak, jak była ona „domnożona” do funkcji, tak też pozostanie „domnożona” do jej pochodnej. Wzór (4) natomiast określa, że pochodna sumy bądź różnicy dwu funkcji równa jest odpowiednio sumie, bądź różnicy ich pochodnych. Można też spotkać się z zapisem:
$$\left[a \cdot f(x) + b \cdot g(x) \right]' = a \cdot f'(x) + b \cdot g'(x) \tag {4a} \label {eq:{4a}}$$
który wyraża te dwie własności niejako „naraz” (zamiast $\pm$ użyto $+$, gdyż współczynniki $a$, $b$ mogą być zarówno dodatnie, jak i ujemne.
Kolejne dwa, bardzo ważne wzory, pozwalają wyliczyć pochodną iloczynu oraz ilorazu dwu funkcji:
we wzorze (6) dodaje się, oczywiście, zastrzeżenie: $g(x) \neq 0$.
Wzór (5) często mnemotechnicznie określa się formułką: pochodna pierwszego razy drugie plus pierwsze razy pochodna drugiego. Ważne, by nauczyć się go w takiej właśnie kolejności, bo mnożenie jest przemienne i formułę można byłoby zapisać także w taki sposób: $f(x) \cdot g'(x) + f'(x) \cdot g(x)$ ale wówczas nie nauczylibyśmy się prawidłowo wzoru (6), w którym licznik jest niemalże taki sam, jak wyrażenie ze wzoru (5), ale pomiędzy iloczynami pojawia się znak minus.
Wzór (6) można też zapisać w nieco prostszy sposób:
Słownie opisuje się go zazwyczaj w następujący sposób: pochodna funkcji złożonej równa jest pochodnej funkcji wewnętrznej dla tego samego argumentu razy pochodna funkcji wewnętrznej. Sposób korzystania z tego wzoru wyjaśnimy później.
Wzory na pochodne konkretnych funkcji
Absolutne must know
Wzory na pochodne konkretnych funkcji podzieliłem na dwie grupy – absolutne minimum, które trzeba umieć, oraz uzupełniający zestaw, który w razie „zapomnienia”, któregoś z jego wzorów, można sobie łatwiej lub trudniej wyprowadzić ze wzorów must know.
$$ (a)' = 0 \tag 8 \label {eq:8}$$
$$ (x^a)' = a \cdot x^{a-1} \tag 9 \label {eq:9}$$
$$ (\e^x)' = \e^x \tag {10} \label {eq:{10}}$$
$$(\ln x)' = \frac 1 x \tag {11} \label {eq:{11}}$$
Wzór (11) występuje też w nieco „lepszej”, można powiedzieć „mocniejszej” postaci:
$$(\ln |x|)' = \frac 1 x \tag {11a} \label {eq:{11a}}$$
Oczywiście do niektórych wzorów należałoby poczynić pewne zastrzeżenia, czyli we wzorze(11): $x>0$, we wzorze (11a): $x \neq 0$ natomiast we wzorze (13): $-1 \leq x \leq 1$, stosownie do ograniczeń dziedziny funkcji.
Szczególnie ważny jest wzór (9). Jest to bodajże najczęściej stosowany wzór, spośród wszystkich wzorów rachunku różniczkowego. Często spotyka się go w postaci $\left( x^n \right)' = nx^{n-1}$ nie jest to jednak najbardziej elegancka jego postać, gdyż sugeruje, że wykładnik $n$ musi być liczbą naturalną, a tymczasem wzór ten działa dla dowolnego wykładnika rzeczywistego, toteż znacznie lepiej używać innej litery – np. właśnie $a$.
Równie ważny i wyjątkowo prosty jest wzór (10), określający pochodną funkcji wykładniczej o podstawie $e$. Funkcja taka ma wyjątkową własność, polegającą na tym, że równa jest ona swojej pochodnej. Istnieje jeszcze tylko jedna funkcja, posiadającą taką niezwykłą właściwość. Jest nią funkcja stała $f(x) = 0$.
Odnośnie funkcji stałej $f(x)=a$ należy w tym momencie zwrócić uwagę, że, zgodnie ze wzorem (3) jeśli stała jest pomnożona przez jakąś funkcję posiadającą pochodną, to stałą ta „zostaje” po policzeniu pochodnej, ale pochodna „samotnej” stałej równa jest zero.
Wzory dodatkowe
Poniżej wykaz wzorów dodatkowych, które również wypada znać, ale zapomniawszy je, można się „poratować” stosownym wyprowadzeniem, choć w niektórych przypadkach trzeba mieć podstawową orientację w zależnościach między funkcjami trygonometrycznymi oraz wiedzieć, czym są funkcje hiperboliczne.
$$\left( x \right)' = 1 \tag {15} \label {eq:{15}}$$
Oczywiście tam, gdzie to konieczne, należy uwzględnić stosowne zastrzeżenia, dotyczące wartości $x$, natomiast we wzorach (18) oraz (19) dodatkowo musi być $a>0$ i we wzorze (19) ponadto $a \neq 1$.
Wzorów jest oczywiście dużo. Zauważmy, że wzory (15), (16), (17) są szczególnymi przypadkami wzoru (9). Pokażemy to w dalszej części artykułu. Warto zwrócić uwagę na wzór (18) i porównać go ze wzorem (9), gdyż stawiający swe pierwsze kroki z rachunkiem różniczkowym studenci często te dwa wzory mylą.
Wzór (9) to wzór na pochodną funkcji potęgowej, czyli funkcji, w której zmienną jest podstawa potęgi, a wykładnik potęgi jest stały. Natomiast wzór (18) określa pochodną funkcji wykładniczej, czyli funkcji, w której podstawa jest stała (musi być liczbą dodatnią), a zmienna jest w wykładniku.
Uważny Czytelnik zapyta, co z funkcją typu $x^x$, gdzie i podstawa i wykładnik są zmienne? Otóż wzór na pochodną takiej funkcji, zwanej czasem funkcją potęgowo-wykładniczą, nie zalicza się do „kanonu” podstawowych wzorów rachunku różniczkowego, tylko pochodną tę wylicza się za pomocą sprytnej sztuczki, o której wspomnimy w dalszej części.
Wykorzystanie wzorów na pochodną
W pierwszej kolejności pokażemy, w jaki sposób ze wzorów, które określone zostały, jako must know wyprowadzić pozostałe wzory – przynajmniej niektóre, resztę Czytelnik sprawdzi we własnym zakresie.
Przykład 5
Wyprowadźmy wzór (15), czyli wzór na pochodną funkcji tożsamościowej, albo bardziej swojsko, na pochodną z iksa:
$$(x)' = \left( x^1 \right)' = 1 \cdot x^0 = 1$$
To, że pochodna z $x$ równa się 1, to bardzo cenna i przydatna informacja.
Przykład 6
Wyprowadźmy wzór (16) i to na dwa sposoby! Korzystając ze wzoru (9), a także inaczej, korzystając ze wzoru (6). Pamiętajmy, że w przykładzie 3 obliczyliśmy już tę pochodną, korzystając z definicji.
Prawda, że proste? A teraz, skorzystajmy ze wzoru (6) traktując wyrażenie $\frac 1 x$, jako iloraz dwu funkcji. Ponadto wykorzystamy wzór (15), poparty przykładem 5:
Korzystając ze wzoru (9) obliczymy pochodną z pierwiastka kwadratowego. Pochodną tę obliczaliśmy już z definicji w ramach przykładu 2. Zobaczymy, jak wzór (9) sprawdza się „w akcji” dla wykładnika niebędącego liczbą całkowitą – wszak $\sqrt x = x^{\frac 1 2}$.
Oczywiście pod koniec skorzystaliśmy z tego, że potęga ujemna, to odwrotność potęgi dodatniej, a więc $x^{-\frac 1 2} = \frac 1 {x^{\frac 1 2}} = \frac 1 {\sqrt x}$. Przykład ten pokazuje prawdziwą potęgę wzoru na pochodną funkcji potęgowej! Za pomocą wzoru (9) obliczymy pochodną z każdego pierwiastka!
Pochodna funkcji złożonej
Aby sprawdzić kolejne wzory, należy oswoić się ze wzorem (7), gdyż pełni on bardzo ważną rolę i bez niego bylibyśmy w stanie policzyć tylko pochodne najprostszych funkcji. Wzór (7), jak wspomnieliśmy, służy do obliczenia pochodnej funkcji złożonej. A co to jest funkcja złożona? Mówiąc najprościej, jest to funkcja, z innej funkcji. Czyli funkcja, w której argumentem nie jest po prostu $x$, ale pewne wyrażenie, zawierające $x$, które samo może być traktowane, jako funkcja posiadająca pochodną.
Przykład 8
Policzmy pochodną funkcji $f(x) = (x + 5)^3$. Jest to funkcja złożona, albowiem test to jakby funkcja $x^3$, a której w miejscu $x$ występuje wyrażenie $x+5$, które samo może być traktowane, jako funkcja. W takim kontekście, funkcję $x^3$ nazywamy funkcją zewnętrzną, a funkcję $x + 5$ nazywamy funkcją wewnętrzną.
Jeśli wprowadzimy oznaczenia $g(x) = x^3$ oraz $h(x) = x+5$, to naszą funkcję $f(x) = (x+5)^3$ można zapisać, „fachowo” jako złożenie $\left( g \circ h \right) (x)$, bądź mniej „fachowo” jako $g\left[ h(x) \right]$. Zauważmy przy tym, że składanie funkcji nie jest operacją przemienną, bo te same funkcje złożyć można także „w drugą stronę”, otrzymując: $\left( h \circ g\right)(x) = h\left[ g(x) \right] = x^3 + 5$, a zatem zupełnie inną funkcję.
Zaraz zaraz, ale czy musimy traktować to, jako funkcję złożoną. Przecież możemy użyć wzoru skróconego mnożenia: $(x+5)^3 = x^3 + 15x^2 + 75x + 125$. W porządku, można i tak. Policzmy zatem najpierw pochodną w ten sposób:
można jeszcze wykazać się spostrzegawczością i troszkę uprościć:
$$... = 3 \cdot (x^2 + 10x + 25) = 3 (x+5)^2$$
No tak, ale co by było, gdyby zamiast $(x+5)^3$ było np. $(x+5)^{20}$? Sama „rozpiska” z trójkąta Pascala albo z wykorzystaniem symbolu Newtona $\left( \begin{array}{c}n\\k \end{array} \right)$ byłaby nie lada wyzwaniem.
Przyjrzyjmy się wzorowi (7): $\left\{ f \left[ g(x) \right] \right \}' = f'\left[g(x) \right] \cdot g'(x) $. Ogólna jego filozofia jest taka. Mamy dwie funkcje. Zewnętrzna, to $x^3$, jej pochodna, to, zgodnie ze wzorem (9), $3x^2$. Tutaj mamy do potęgi trzeciej podniesione coś innego. Mamy jakby $\square^3$.
Wzór (7) „mówi” tak: dokładnie tak samo, jak $\left( x^3 \right)' = 3x^2$, to $\left( {\square}^3 \right)' = 3\cdot{\square}^2$, ale musisz jeszcze pomnożyć to przez $\square'$, czyli przez pochodną tego $\square$.
Zobaczmy, że praktycznie w każdym ze wzorów (8)–(32) moglibyśmy zastąpić $x$ „kwadracikiem” $\square$ i pomnożyć przez pochodną tego kwadracika! W naszych wzorach po prostu „kwadracikiem” jest $x$, a że $(x)' = 1$, toteż wszystko się zgadza!
Przykład 9
Obliczmy więc pochodną funkcji $f(x) = \left( 4x^2 + 3x -9 \right)^{10}$. Tutaj już pochodna funkcji złożonej jest prawie niezastąpiona:
Teraz obliczmy pochodną funkcji $f(x) = \sqrt {x^2 + x + 5}$. Tutaj już żadne inne metody nie wchodzą w rachubę. Schemat obliczania pochodnej funkcji złożonej jest koniecznością.
$$f'(x) = \left( \sqrt {x^2 + x + 5}\right)' = \frac 1 {2 \sqrt {x^2 + x + 5}} \cdot (x^2 + x + 5)' = $$
Wyznaczmy teraz pochodną wartości bezwzględnej. W przykładzie 4 dokonaliśmy tego, wykorzystując bezpośrednio definicję pochodnej, natomiast teraz wykorzystamy tożsamość: $|x| = \sqrt {x^2}$. Zatem niech $f(x)=|x|$.
A teraz czas na istną „rosyjską babuszkę”. Obliczmy pochodną funkcji $f(x)=\e^{\sqrt{x^2+7}}$. Czemu „rosyjską babuszkę”? Rosyjskie babuszki, to takie drewniane figurki, przedstawiające kobietę w stroju ludowym, że wewnątrz większej figurki jest mniejsza, wewnątrz tej mniejszej – jeszcze mniejsza i tak dalej. Tutaj też. Mamy funkcję wykłądniczą $\e^x$, która tutaj jest tą największą „babuszką”, wewnątrz niej, zamiast $x$ mamy schowaną kolejną „babuszkę” w postaci pierwiastka $\sqrt x$ i najmniejszą „babuszką” jest wielomian $x^2+7$.
Co robimy z taką „babuszką” – po kolei, systematycznie, „oskubujemy” ją. Dla przypomnienia: $\left( \e^{\square} \right)' = \e^{\square} \cdot \square'$ (wzór 10), $\left( \sqrt \square \right)' = \frac {\square'} {2 \sqrt \square} $ (wzór 17) oraz $\left( x^2 + 7 \right)' = 2x$
Pozwoliliśmy sobie tutaj już, jak na średniozaawansowanych przystało, na nieco skrótu w zapisie.
Przykład 13
Spróbujmy wyprowadzić wzór na pochodną funkcji wykładniczej $f(x) = a^x$, czyli wzór (18), wykorzystując wzór „must know” (10). Skorzystamy z tego, że $a = \e^{\ln a}$, w takim razie nasza funkcja:
W zestawie „must know” mamy tylko wzór (12) na pochodną funkcji sinus. Wyznaczmy wzory na pochodne pozostałych trzech2 funkcji trygonometrycznych.
Cosinus wyrazić można za pomocą sinusa. Pierwsze, co przychodzi do głowy, to jedynka trygonometryczna, z której mamy: $\cos x = \sqrt {1 - \sin^2 x}$. Nie jest to dobry trop, gdyż takie przekształcenie jest prawidłowe tylko dla kątów, dla których $\cos x \geq 0$. Lepiej użyć znacznie prostszego i zawsze działającego wzoru: $\cos x = \sin \left( \frac \pi 2 - x \right)$.
Wówczas:
$$\left( \cos x \right)' = \left[ \sin \left( \frac \pi 2 - x \right) \right]' = \cos \left( \frac \pi 2 - x \right) \cdot (0 - 1) = $$
Warto w tym momencie zwrócić uwagę na pewne podobieństwo do pochodnej funkcji wykładniczej $\e^x$. Jak wiemy, $\left( \e^x \right)' = \e^x$ i oprócz niej tylko jeszcze jedna, trywialna, funkcja równa jest swej pochodnej: $(0)' = 0$. Jeśli funkcję wykładniczą $\e^x$ różniczkowali będziemy wielokrotnie – czyli z pochodnej liczyli znów pochodną (czyli wyznaczali pochodne wyższych rzędów), to oczywiście cały czas otrzymywac będziemy $\e^x$.
Nic w tym odkrywczego. Jednak bardzo podobnie zachowywać się będa funkcje sinus i cosinus. Bowiem $\left( \sin x \right)' = \cos x$ następnie $\left( \cos x \right)' = -\sin x$, później $\left( -\sin x \right)' = -\cos x$ i w końcu: $\left( -\cos x \right)' = \sin x$ i cykl się zamyka. Kolejne pochodne to po prostu naprzemian sinus z cosinusem i zmieniają się znaki.
Tak więc sinus i cosinus, to funkcje bardzo przypominające pod tym względem $\e^x$. I nie jest to przypadek, ale omówienie tego wymaga poruszenia tematu liczb zespolonych i wykracza poza ramy tego artykułu. Ta ciekawa własność funkcji $\e^x$ oraz sinusa i cosinusa, wykorzystywana jest w równaniach różniczkowych.
Otrzymaliśmy zatem wzór (20). Z kolei oczywiście $\tg x = \frac {\sin x} {\cos x}$ i wówczas, wykorzystując dopiero co wyprowadzony wzór, wzór (6) na pochodną ilorazu oraz (tym razem się przyda) jedynke trygonometryczną dostajemy:
$$\left( \tg x \right)' =\left( \frac {\sin x}{\cos x} \right)' = \frac {(\sin x)' \cdot \cos x - \sin x \cdot (\cos x)'}{\cos^2 x} =$$
$$ = \frac {\cos x \cdot \cos x - \sin x \cdot (-\sin x)}{\cos^2 x} =\frac {\cos^2 x + \sin^2}{\cos^2 x} = \frac 1 {\cos^2 x}$$
Dostaliśmy więc wzór (21). Wyprowadzenie wzoru (22) pozostawiam Czytelnikom.
Przykład 15
W zestawie „must know” zamieściliśmy pochodne tylko dwu funkcji cyklometrycznych: arcusa sinusa i arcusa tangensa. Gdy jednak przypomnimy sobie czym są funkcje cyklometryczne, bardzo łatwo wyznaczymy pozostałe. Otóż wykres funkcji arcus cosinus otrzymamy z wykresu funkcji arcus sinus, poprzez odbicie symetryczne względem osi $Ox$ oraz przesuniecie w górę o $\frac \pi 2$, stąd: $\arccos x = \frac \pi 2 - \arcsin x$. W takiej sytuacji, wykorzystując wzór (13), wzór (23) wyprowadzimy z łatwością:
Wyprowadźmy wzory dla funkcji hiperbolicznych $\sinh x$, $\cosh x$, $\tgh x$, $\ctgh x$. W ogóle nie zamieściliśmy ich wsród wzorów „must know”. Stało się tak dlatego, że funkcje te wylicza się z prostych wzorów, opartych o funkcję wykładniczą $\e^x$.
Otrzymaliśmy wzór (25). Zwróćmy uwagę, że nie wykorzystywaliśmy wzoru (6) na pochodną ilorazu, gdyż wyrażenie (33) nie musi być traktowane, jak iloraz dwu funkcji. Mianownik jest bowiem stałą i można wyrażenie (33) potraktować, jako iloczyn licznika i stałej $\frac 1 2$.
Otrzymaliśmy wzór (27). Wyprowadzenie wzoru na cotangens hiperboliczny, to zadanie dla Czytelników.
Przykład 17
Teraz wyprowadzimy wzór na pochodne funkcji odwrotnych do funkcji hiperbolicznych. Należy w tym momencie zwrócić uwagę, że nagminne jest błędne nazywanie tych funkcji przez studentów. Otóż nie ma czegoś takiego jak „arcus sinus hiperboliczny”, jest – tylko i wyłącznie – area sinus hiperboliczny, area cosinus hiperboliczny, itd. I „wymawia się, jak się pisze” area, nie żadne „erja”, to nie jest słowo angielskie, lecz łacińskie!
Podobnie w symbolach area sinusa hiperbolicznego oraz area tangensa hiperbolicznego nie uświadczymy litery „c”: ma być $\arsinh x$ oraz $\artgh x$. W area cosinusie i area cotangensie hiperbolicznym oczywiście „c” jest, ale tylko jedno! $\arcosh x$ oraz $\arctgh x$.
Wzory na funkcje area można otrzymac wyliczając $x$ ze wzorów na funkcje hiperboliczne. Jest to temat na inny artykuł, dlatego tutaj od razu zamieścimy te wzory:
Otrzymano wzór (29). Obliczenie pochodnej funkcji $\arcosh$, danej wzorem (38) zostawmy Cztytelnikom. Teraz policzymy pochodną funkcji (39), czyli area tangensa hiperbolicznego:
Otrzymano wzór (31). Obliczenie pochodnej area cotangensa hiperbolicznego pozostawiam Czytelnikom.
Pochodna funkcji potęgowo-wykładniczej
Funkcją potęgowo-wykładniczą, jak już wspomniano, nazywa się funkcję $f(x) = x^x$. Jest to dość ciekawa funkcja o dziedzinie $x \in \mathbb R^+$. Jej pochodną oblicza się w specyficzny sposób, gdyż nie można zastosować bezpośrednio ani wzoru (9), gdyż wykładnik jest zmienny, ani wzoru (18), gdyż podstawa jest zmienna.
Przykład 18
Aby wyliczyć pochodną funkcji $f(x) = x^x$, wykorzystujemy to samo przekształcenie, które wykorztystaliśmy do wyliczenia wzoru (18) ze wzoru (10). Czyli przekształcenie $a^b = \e^{b \cdot \ln a}$. Po dokonaniu takiego przekształcenia, korzystamy ze wzorów na pochodną funkcji wykładniczej $\e^x$, czyli wzoru (10), oraz wzorów (5) oraz (7) na obliczenie pochodnej iloczynu oraz pochodnej funkcji złożonej :
$$ = x^x \cdot \left( 1 \cdot \ln x + \cancel x \cdot \frac 1 {\cancel x} \right) = x^x \cdot \left( \ln x + 1 \right) $$
Z tego schematu możemy skorzystać zawsze, gdy trzeba będzie obliczyć pochodną $\left[ f (x)^{g(x)} \right]'$.
Różniczka funkcji
Jak już wielokrotnie wspomnieliśmy, obliczanie pochodnej funkcji nosi nazwę jej różniczkowania. Skoro obliczanie całek, to całkowanie, to czy różniczka, to nie powinno być obliczanie różniczek? Co to w ogóle jest różniczka? Czy to synonim pochodnej?
Otóż odpowiedź brzmi – niezupełnie. Najkrócej mówiąc, różniczką funkcji nazywamy iloczyn jej pochodnej, przez elementarny (tj. nieskończenie mały, dążący do zera) przyrost zmiennej tej funkcji. W zasadzie ten elementarny przyrost, to jest to nasze $h$, występujące we wzorach (1) oraz (2), tyle tylko, że utarł się zwyczaj oznaczania go nie literą $h$, a jako $\mathrm{dx}$.
Wartość różniczki oznacza przyrost wartości funkcji w danym punkcie, dla elementarnego przyrostu argumentu. Po prostu traktujemy nieskończenie mały kawałek wykresu funkcji, jako odcinek prostej stycznej do wykresu funkcji.
Rysunek 4. Ilustracja różniczki funkcji w punkcie $x_0$.
Tworzy się jakby trójkąt prostokątny, który ma szerokość $\mathrm{dx}$, wysokość $\mathrm d f$, a jego przeciwprostokątną jest odcinej stycznej do wykresu funkcji. Z różniczkami będziemy mieli bardzo często do czynienia, podczas obliczania całki nieoznaczonej.
Co dalej?
Nasz artykuł przedstawia podstawy rachunku różniczkowego. Ma za zadanie pokazać, w jaki sposób należy liczyć pochodne – zarówno z definicji, jak i ze wzoru. Obliczanie pochodnych, w przeciwieństwie do całkowania, wyznaczania granic czy badania zbieżnosci szeregów, to takie zagadnienie, którego nauczyć się stosunkowo łatwo. Jedynie wyznaczanie pochodnej z definicji wymaga nauczenia się pewnych „sztuczek” i „chwytów”, natomiast korzystanie ze wzorów można porównać do jazdy na rowerze. Jeśli raz utrzymamy równowagę, dalej pójdzie łatwo na każdej trasie.
Rachunek różniczkowy to wszechstronne narzędzie, wykorzystywane przede wszystkim w analizie przebiegu zmienności funkcji, w zagadnieniach z zakresu mechaniki, ekonomii i wielu innych dziedzinach nauki. Nie da się samodzielnie zaliczyć nawet pierwszgo semestru na studiach politechnicznych, bez opanowania rachunku różniczkowego. Opanowanie rachunku różniczkowego, to z kolei warunek konieczny opanowania, przynajmniej w podstawowym zakresie, rachunku całkowego – niezbędnego do samodzielnego zaliczenia kolejnego semestru.
Sebastian Dziarmaga-Działyński
Jeden z moich wykładowców na Politechnice Częstochowskiej, prof. dr hab. inż. Józef Koszkul, miał „alergię” na używanie słowa „własności” odnośnie cech szczególnych czegoś. Koniecznie domagał się używania słowa „właściwości”, argumentując, że „własność” to słowo określające stosunek posiadania (np. „ten samochód jest moją własnością”). Nie zgadzam się z Panem profesorem. Obydwa słowa „własność” i „właściwość” mogą być używane zamiennie w kontekście cech szczególnych jakiegoś obiektu. Wszak słowo „właściwość” również posiada swe drugie znaczenie, określające „poprawność”, „prawidłowość” (np. „właściwość sądu”). Taki już jest urok, taka własność, taka właściwość języka, że słowa posiadają kilka znaczeń. ↩︎
Ostatnio daje się zaobserwować wycofywanie funkcji cotangens z programu nauczania szkół średnich. Matematyka wyższa raczej nie zamierza z niej rezygnować, choć pamiętajmy, że są jeszcze dwie funkcje trygonometryczne, z których dawno już zrezygnowała: secans i cosecans. ↩︎
Średnia niejedno ma imię
mgr inż.
Sebastian Dziarmaga-Działyński
Wprowadzenie
Średnia arytmetyczna, to najpowszechniej znana miara statystyki opisowej. Znana i w miarę dobrze rozumiana także i przez najbardziej odżegnujące się od matematycznych sympatii osoby. Stosowana bardzo szeroko zarówno, jako miara zbiorowości, jak i estymator wartości oczekiwanej w populacji generalnej. Jednak statystyka zna nie tylko średnią arytmetyczną. Znane i używane są również inne rodzaje średniej, jak średnia harmoniczna, średnia geometryczna. Wybór konkretnej średniej zależy od specyfiki zbiorowości i cechy, dla której średnia jest obliczana, natomiast sposób obliczania tej miary zależy od rodzaju szeregu statystycznego.
Co to w ogóle jest średnia
Najkrócej mówiąc, średnia to pewna charakterystyka, jest to każda funkcja określona na zbiorze danych $x_1, x_2, ..., x_n$ spełniająca warunek:
Oprócz tego względem każdej ze zmiennych $x_i$ średnia musi być funkcją niemalejącą. Jak więc widać, wiele nie potrzeba, aby dany parametr mógł być nazywany średnią. W tym kontekście, średnią jest zarówno wartość najmniejsza, jak i największa spośród danych, gdyż spełniają one warunek (1). Średnią jest także dominanta, czy mediana a nawet każdy kwantyl1.
Średnia arytmetyczna
Średnia arytmetyczna, jako klasyczna miara tendencji centralnej
Średnia arytmetyczna jest najbardziej znanym przykładem klasycznej miary tendencji centralnej. Miary klasyczne, to takie miary statystyczne, na wartość których wpływają wszystkie dane w szeregu. Zmiana pojedynczej danej zawsze wpływa na wartość miary.
Miara tendencji centralnej oznacza, że wskazuje na przeciętność. Oprócz określenia miara tendencji centralnej, stosuje się także często określenie miara położenia, co jest również trafnym określeniem w stosunku do średniej i nieco szerszym, gdyż w zakres miar położenia wchodzą także kwartyle i kwantyle innych rzędów. W najszerszym ujęciu można powiedzieć, że praktycznie każda miara położenia jest średnią w rozumieniu warunku (1).
Obliczanie średniej w szczegółowym szeregu statystycznym
Średnia arytmetyczna w szczegółowym szeregu statystycznym, to właśnie ta średnia, najszerzej i najlepiej rozumiana w języku potocznym. Sposób jej obliczania można najkrócej streścić, jako dodaj wszystkie wartości i podziel przez ich ilość. Sposób ten zapisuje się najczęściej za pomocą formuły:
Operator sumowania oznacza, że podstawiamy za indeks przy zmiennej $x$ kolejne wartości $i$ od 1 aż do $n$ i wszystkie kolejno otrzymywane wartości $x_1$, $x_2$, …, $x_n$ sumujemy. Z kolei oznaczenie $\bar x$ to powszechnie przyjęte w statystyce opisowej oznaczenie średniej arytmetycznej, za pomocą poziomej kreski nad nazwą zmiennej.
Przykład 1
Akwizytor w kolejnych miesiącach, od stycznia do grudnia zarobił następujące kwoty prowizji: 2480; 6731; 1128; 5355; 7846; 972; 1571; 9903; 7525; 5644; 2781; 6702. Obliczyć średnią wysokość prowizji akwizytora w miesiącu.
Tak więc średnia, miesięczna kwota uzyskiwanej przez akwizytora prowizji, wyniosła 5636,50 zł.
Co to oznacza w praktyce? Gdyby nasz akwizytor osiągał regularne miesięczne prowizje, to, gdyby w każdym miesiącu jego prowizja wyniosła 5636,50 zł, można by powiedzieć, że „wyszłoby na to samo”. Taka jest właśnie idea średniej arytmetycznej.
Niektórzy nauczyciele akademiccy tłumaczą studentom, że średnia nie nadaje się dobrze do wielkości silnie zróżnicowanych. Tam, gdzie pojawiają się wartości odstające – tak, jak u nas w jednym miesiącu prowizja wyniosła aż 18903 zł. Nie jest to jednak do końca prawda. Bez względu na to, jak zróżnicowane są wartości i jak bardzo niektóre z nich odstają od reszty, średnia jest zawsze właściwą miarą, dla wielkości, które podlegają sumowaniu, czyli wielkości (zmiennych statystycznych), których suma ma sens praktyczny.
W naszym przypadku, niezależnie od tego, czy nasz akwizytor w danym miesiącu zarobi sto, czy milion złotych, to wszystko wpada do jego i kieszeni i wpływa na średni roczny dochód. Tak więc średnia w tym przypadku zawsze będzie odpowiednią miarą przeciętności.
Przykład 2
Jeśli jednak np. będziemy chcieli ustalić przeciętną cenę zagranicznej wycieczki spośród następujących ofert (ceny za uczestnika, dane uszeregowano od najmniejszej do największej ceny za osobę): 2500; 2850; 2900; 3200; 3350; 3600; 3700; 3800; 25700; 31000, to wówczas średnia wyniesie:
Otrzymamy przeciętną cenę wycieczki 8260. Czy jednak w takim wypadku będzie to dobra ocena przeciętności? Otóż – zależy. Jeśli będą to np. kwoty wycieczek sprzedanych przez biuro podróży w danym tygodniu, to można powiedzieć, że średnio biuro uzyskało 8260 zł za jedną wycieczkę. Jeśli jednak jest to 10 ofert i chcemy podać przeciętną cenę – np. dla zorientowania się w sytuacji rynkowej, to średnia nie będzie dobrą miarą.
Wynikająca z niej przeciętna cena wycieczki da całkowicie fałszywy obraz sytuacji. Dla przeciętnego konsumenta wycieczka za ponad 8 tys. zł od osoby jest zbyt droga. I w rzeczywistości, wśród przedstawionych dziesięciu ofert nawet nie ma ani jednej wycieczki z takiej półki cenowej. Dla bogatego miłośnika luksusu z kolei, taka cena może sugerować, że oferowane wycieczki są poniżej jego subiektywnej granicy ekskluzywności.
W tej sytuacji istotnie, pojawienie się odstających danych sprawia, że lepszą miarą przeciętności od średniej okazuje się mediana. W tym wypadku mediana wyniesie 3475 zł i wartość ta dość trafnie obrazuje sytuację. Dzieje się tak dlatego, że dane nie podlegają tutaj sumowaniu. To, że ktoś kupił sobie wycieczkę za ponad 30 tys. zł w żaden sposób nie wpływa na cenę wycieczki dla innych konsumentów. To bardzo istotna kwestia, często poruszana na zajęciach ze statystyki.
Obliczanie średniej arytmetycznej w szeregu rozdzielczym punktowym
Szereg rozdzielczy punktowy, to efekt „kompresji bezstratnej” szeregu szczegółowego. Jeśli dane się powtarzają, zamiast enumeratywnie wypisywać wszystkie takie dane wielokrotnie, można zamiast tego zapisać wartość oraz ilość powtórzeń. Zamiast wielokrotnie dodawać tę samą wartość, można mnożyć wartość przez liczebność.
Schemat szeregu rozdzielczego punktowego jest następujący:
$x_i$
$n_i$
$w_i$
$x_1$
$n_1$
$w_1$
$x_2$
$n_2$
$w_2$
…
…
…
$x_k$
$n_k$
$w_k$
$\Sigma$
$N$
$1$
$x_i$ to wartości cechy (zmiennej), $n_i$ to liczebności (częstości) wystąpienia poszczególnej wartości, natomiast $w_i$ to częstości względne: $w_i = {n_i \over N}$.
Wzór na obliczenie średniej arytmetycznej w takim szeregu to:
Należy zwrócić uwagę, że w przeciwieństwie do wzoru (2b), we wzorach (3a) oraz (3b) sumowanie odbywa się do $k$ a nie do $n$. $k$ jest tutaj oczywiście ilością różnych wartości występujących w szeregu.
Średnia arytmetyczna, obliczana dla szeregu rozdzielczego punktowego, to szczególny przypadek średniej arytmetycznej ważonej, o której mowa będzie w dalszej części artykułu.
Przykład 3
Poniżej zebrano dane o ilości wypadków, jakie wydarzyły się w pewnej miejscowości w 100 kolejnych dniach.
$x_i$
$n_i$
$w_i$
0
45
$0,45$
1
22
$0,22$
2
12
$0,12$
3
8
$0,08$
4
7
$0,07$
5
6
$0,06$
$\Sigma$
100
$\textbf 1$
Średnia arytmetyczna, obliczona wg wzoru (3a) wynosi:
Jak widać, wzór (3b) pozwala na wyliczenie średniej arytmetycznej niejako „bezpośrednio”. Od razu uzyskujemy wynik. Obliczona wartość średniej arytmetycznej oznacza, że w objętej analizą miejscowości w badanym okresie wydarzyło się średnio 1,28 operacji dziennie.
Obliczenie średniej arytmetycznej w szeregu rozdzielczym przedziałowym
W odróżnieniu od szeregu rozdzielczego punktowego, szereg rozdzielczy przedziałowy (zwany czasem także szeregiem rozdzielczym z przedziałami klasowymi) stanowi „kompresję stratną” danych. Szereg zawiera informację o krańcach przedziałów oraz ilości danych, które do należą do poszczególnych przedziałów. Nie wiemy natomiast, jakie dokładnie do tego przedziału trafiły liczby.
Przy obliczaniu miar statystycznych na podstawie szeregów rozdzielczych przedziałowych przyjęto następujące zasady:
dla potrzeb obliczania miar pozycyjnych (np. mediany) przyjmuje się, że poszczególne elementy zbioru danych w każdym z przedziałów rozłożone są równomiernie;
dla potrzeb obliczenia miar klasycznych przyjmuje się, że w każdym przedziale, wszystkie elementy do niego należące mają jednakowe wartości, równe wartości środkowej, tj. średniej arytmetycznej początku i końca przedziału.
Wartość środkową przedziału (klasy) oznacza się zazwyczaj symbolem: $\dot x$. Wzory do obliczenia średniej arytmetycznej są w zasadzie identyczne z wzorami (3a), (3b), tyle, że zamiast wartości zmiennej są środki przedziałów. Wzór wykorzystujący liczebności absolutne:
Średnia wartość zawartych kontraktów wyniosła 20,5 tys. zł.
Średnia arytmetyczna ważona
Ze średnią ważoną mamy do czynienia wówczas, gdy obliczamy średnią w sytuacji, gdy wszystkie dane w szeregu statystycznym są dla nas niejednakowo ważne. Z tym mieliśmy do czynienia właśnie w szeregach rozdzielczych, gdzie średnia nie była obliczana przez zwykłe dodanie wartości zmiennej, ale wartości te były mnożone przez liczebności. Liczebności te pełniły rolę wag. We wzorach (3a) oraz (4a) wagami były liczebności (częstości) absolutne, natomiast we wzorach (3b) oraz (4b) były to częstości względne (wskaźniki struktury).
W ogólności bowiem, formuła na średnią arytmetyczną ważoną w szeregu szczegółowym, złożonym z $n$ wartości $x_i$, z których każda posiada swoją wagę $w_i$, wyraża się wzorem:
Jeśli wagi są unormowane, czyli sumują się do jedności (np. są to wagi określone procentowo), to wówczas $\sum_{i=1}^n w_i = 1$ i we wzorze (5) „znika” mianownik (jest równy jedności).
Wagi mogą być określone arbitralnie. Np. wysokość stypendium naukowego może być określona, jako średnia ważona z odpowiednich przedmiotów.
Przykład 5
Załóżmy, że na pewnej uczelni określono minimalną średnią do ubiegania się o stypendium naukowe w wysokości 4,2. Określono, że do średniej tej wliczają się uzyskane w poprzednim semestrze oceny z analizy matematycznej oraz statystyki opisowej. Wagi przypisane poszczególnym ocenom oraz uzyskane przez pewnego studenta oceny, przedstawia poniższa tabela:
Przedmiot
Waga oceny
Ocena studenta
Analiza matematyczna- ćwiczenia
10%
4,5
Analiza matematyczna – egzamin
30%
4,0
Statystyka opisowa – ćwiczenia
20%
4,0
Statystyka opisowa – laboratorium
15%
3,5
Statystyka opisowa – egzamin
25%
5,0
SUMA
100%
Czy student uzyska stypendium?
Obliczamy średnią ważoną. Wagi są unormowane. Średnia wynosi:
A zatem nasz student załapał się na stypendium naukowe przysłowiowym „rzutem na taśmę”.
Co jeszcze powinniśmy wiedzieć o średniej arytmetycznej?
Średnia arytmetyczna to najlepszy możliwy estymator wartości oczekiwanej w populacji generalnej. Jeśli mamy populację i chcemy oszacować wartość oczekiwaną jakiejś zmiennej w tej populacji, czyli właśnie taką średnią dla całej populacji, dysponując losowa próbką danych, wówczas nie ma lepszego oszacowania aniżeli średnia arytmetyczna. Będzie to poruszone w artykule o estymatorach.
Średnia harmoniczna
Średnia harmoniczna, jako średnia do zadań specjalnych
Skoro średnia arytmetyczna jest taka dobra, to po co korzystać z jakichś innych średnich? Otóż są sytuacje, gdzie średnia arytmetyczna nie spełnia dobrze swojej roli miary przeciętności. Wcale nie chodzi tutaj o pojawianie się danych odstających, itp. ale o specyfikę zmiennej, dla której liczymy średnią.
Średnią harmoniczną, dla szeregu szczegółowego scharakteryzować można najkrócej w taki sposób, że odwrotność średniej harmonicznej jest średnią arytmetyczną z odwrotności danych. Literalnie zatem wykorzystując tę niby-definicję mamy:
Pierwsze co się powinno „rzucić w oczy” to to, że nie można średniej tej policzyć, gdy wśród danych znajduje się zero. W ogóle najlepiej przyjąć, że średnią harmoniczną liczymy dla danych dodatnich. Oprócz tego, że wśród danych nie może być zera, specyfika wzoru (6) jest taka, że w szczególny sposób traktuje ona liczby. W przeciwieństwie do średniej arytmetycznej, która wszystkie liczy traktuje po równo, średnia harmoniczna faworyzuje wartości niskie, co skutkuje następująca relacją pomiędzy średnią arytmetyczną, a harmoniczną:
$$\bar x_h \leq \bar x \tag 7 \label {eq:7}$$
Czyli średnia harmoniczna zawsze jest nie większa od średniej arytmetycznej, a równość zachodzi tylko wówczas, gdy wszystkie dane w zbiorze są jednakowe.
Kiedy średnia harmoniczna jest lepsza miarą przeciętności od średniej arytmetycznej? Weźmy następujący przykład.
Przykład 6
Adam jechał do swojej babci na rowerze. Do babci, jechał trochę pod górkę, średnio z prędkością $10 \,\frac{\mathrm{km}}{\mathrm{h}}$. Natomiast z powrotem jechał z górki (i cieszył się z prezentu od babci), jechał zatem z prędkością $20 \,\frac{\mathrm{km}}{\mathrm{h}}$. Z jaką średnią prędkością jechał Adam?
Sprawa wydaje się prosta: $\frac {10 + 20} 2 = 15$. Czy jednak $15 \,\frac{\mathrm{km}}{\mathrm{h}}$ to prawidłowa odpowiedź? Okazuje się, że nie.
Załóżmy, że od Adama do Babci jest 10 $\mathrm{km}$. Odległość, jak się zaraz okaże, może być dowolna. Przy prędkości 10 $\mathrm{km}$ droga do babci zajęła Adamowi równą godzinę. Droga powrotna, gdzie ostro pocisnął $20 \,\frac{\mathrm{km}}{\mathrm{h}}$, wymagała tylko pół godziny. W sumie więc, Adam przejechał 20 $\mathrm{km}$, co zajęło mu 1,5 $\mathrm{h}$. Ile zatem wynosiła średnia prędkość? Trzeba podzielić drogę przez czas:
Ciekawe prawda? Zgodnie z ideą średniej harmonicznej, wynik rzeczywiście znajduje się bliżej niższej wartości. Jeśli do kogoś taki przykład słabo przemawia, to weźmy jaskrawszy przykład. Załóżmy, że w drodze powrotnej, Adam został teleportowany z prędkością światła:
$$ c = 299792458 \,\frac{\mathrm m}{\mathrm s} = 1079252849\,\frac{\mathrm{km}}{\mathrm h}$$
Przebycie dystansu 10 $\mathrm{km}$ z taką prędkością, zajmuje niewiele ponad 33 $\mathrm{\mu s}$ (mikrosekund), zatem śmiało można przyjąć zero i w takiej sytuacji podróż w obie strony zajęła mu tyle samo, co w jedną stronę, czyli 1 $\mathrm{h}$ a pokonał w sumie 20 $\mathrm{km}$, czyli średnia prędkość wyniosła $20 \,\frac{\mathrm{km}}{\mathrm{h}}$. Gdybyśmy liczyli według średniej arytmetycznej, wówczas otrzymalibyśmy $539626429,4 \,\frac{\mathrm{km}}{\mathrm{h}}$. Przecież z taką prędkością, zarówno podróż tam, jak i z powrotem zająć powinna mikrosekundy, a zajęła godzinę, prawda?
Przykład 7
Rozważmy problem ogólniej. Jeśli dystans $s$ pokonujemy w jedną stronę z prędkością $v_1$ w drugą zaś – z prędkością $v_2$. Ile wynosi prędkość średnia?
Prędkość średnią wyliczamy jako stosunek (iloraz) łącznego dystansu ($2s$) do łącznego czasu. Ile wynosi łączny czas? Czas jazdy w jedną stronę wynosi: $t_1 = \frac s {v_1}$ a w drugą $t_2 = \frac s {v_2}$. A zatem:
Co otrzymaliśmy? Otrzymaliśmy ni mniej ni więcej, tylko wzór (6) dla $n=2$. Mamy więc pełne uzasadnienie dla stosowania średniej harmonicznej przy obliczaniu średniej prędkości.
Czy jednak zawsze średnią prędkość obliczamy za pomocą średniej harmonicznej?
Przykład 8
Bartek lubi jeździć wyczynowo na rowerze. Pewnego dnia wybrał się w dłuższa, dwugodzinną podróż. Przez pierwszą godzinę jednał w trudnym terenie, pod górkę, z prędkością $10 \,\frac{\mathrm{km}}{\mathrm{h}}$. Później jednak droga stała się prostsza, było z górki. Drugą godzinę jechał z prędkością $20 \,\frac{\mathrm{km}}{\mathrm{h}}$. Jaka była jego średnia prędkość?
Policzmy najpierw, jaki dystans przejechał. Przez pierwszą godzinę jechał z prędkością 10 $\,\frac{\mathrm{km}}{\mathrm{h}}$, przejechał zatem równe 10 $\mathrm{km}$. Drugą godzinę jechał z prędkością 20 $\,\frac{\mathrm{km}}{\mathrm{h}}$, przejechał zatem 20 $\mathrm{km}$. Łącznie przebył więc dystans 30 $\mathrm{km}$ w ciągu dwóch godzin. Średnia prędkość wyniosła więc $15 \,\frac{\mathrm{km}}{\mathrm{h}}$. Tyle, ile wynosi średnia arytmetyczna tych dwu wartości. Zatem:
$$\bar v = \frac {v_1 + v_2} 2$$
O co tutaj chodzi? Dlaczego tym razem to średnia arytmetyczna jest tą właściwą. Zauważmy, że potraktowaliśmy dane, jako dwuelementowy szereg szczegółowy. Elementy szeregu szczegółowego traktujemy, jako jednorodne. W przeciwnym razie należałoby użyć szeregu rozdzielczego lub nadać zmiennym jakieś wagi.
Zmienna, dla której w przykładach nr 7 oraz nr 8 obliczaliśmy średnią, jest wyrażona w jednostce względnej (ilorazowej), $\left[ \frac{\mathrm{km}}{\mathrm h} \right]$. W przykładzie nr 7, gdzie obliczaliśmy średnią prędkość z dwu prędkości „tam” i „z powrotem”, obydwie wartości są jednorodne ze względu na pokonywaną odległość, czyli są jednorodne ze względu na jednostkę z licznika. W takim przypadku właściwą średnią jest średnia harmoniczna.
Z kolei w przykładzie nr 8, gdzie obliczaliśmy średnią prędkość z dwu prędkości w ciągu dwu różnych godzin, obydwie wartości są jednorodne ze względu na jednostkę z mianownika. W takim przypadku właściwą średnia jest „poczciwa” średnia arytmetyczna.
Chcąc zrozumieć logikę tej reguły, pojąć ją „na chłopski rozum” można sobie to wytłumaczyć tak: średnia arytmetyczna ma sens, gdy dane podlegają sumowaniu (patrz przykład 2). Sumować można natomiast liczby o wspólnym mianowniku. Dlatego tez jednorodność pod względem mianownika uzasadnia użycie średniej arytmetycznej. Wspólny licznik nie jest wystarczającym uzasadnieniem dla sumowania, więc używamy średniej harmonicznej, w której wylicza się odwrotności, a wtedy licznik staje się mianownikiem.
W swej już prawie trzydziestoletniej (włączając czasy sprzed założenia Wszechwiedzy) praktyce korepetytorskiej spotkałem się z jeszcze jednym bardzo ciekawym wykorzystaniem średniej harmonicznej. Czy słusznym? Wymaga to głębszej analizy. Jednak innego rodzaju średniej klasycznej w przykładzie, który za chwilę przedstawię, wyliczyć się nie da.
Przykład 9
Składający się z dziecięciu żołnierzy oddział, poszedł na wojnę. Trzech żołnierzy zginęło po pięciu dniach, dwóch po dziesięciu dniach, dwóch po dwudziestu dniach. Pozostali trzej żołnierze przeżyli całą wojnę. Jaki był średni czas życia żołnierza z tego oddziału (licząc od momentu rozpoczęcia wojny)?
Gdybyśmy chcieli tutaj policzyć średnią arytmetyczną, która na pierwszy rzut oka wydaje się być właściwą miarą, to nie jest to możliwe, gdyż nie mamy informacji, ile trwała wojna. Z treści zadania wynika, że na pewno nie była to wojna siedmiodniowa, ale nie wiadomo też, czy była to Druga Wojna Światowa, czy może jednak Wojna Trzydziestoletnia. Nie da się więc policzyć średniej arytmetycznej. W zasadzie wydawałoby się, że nie da się policzyć żadnej miary klasycznej – wszak w wyliczeniu takiej miary udział muszą wziąć wszystkie wartości cechy.
Medianę (jako miarę pozycyjną) można policzyć bez problemu – szereg jest dziesięcioelementowy, medianą jest więc średnia arytmetyczna elementu piątego i szóstego. Czasy życia żołnierzy na wojnie, uporządkowane od najkrótszego do najdłuższego wynoszą:
$$5;\,5;\,5;\,10;\,10;\,20;\,20;\,?;\,?;\,?$$
Trzy nieznane czasy życia żołnierzy, którzy dotrwali do końca wojny, oznaczone są znakami zapytania. Są one z pewnością dłuższe od 20 dni, toteż kolejność elementów nie budzi wątpliwości. Czyli mediana życia żołnierzy wynosi: $Me = \frac {10+20} 2 = 15$ dni. Jest to już coś, ale czy da się policzyć coś jeszcze?
Tak! Rozważając sensowność obliczania średniej harmonicznej w przykładzie nr 6 rozważalibyśmy, co by było, gdyby Adam w drodze powrotnej podróżował z prędkością światła. Przyjęliśmy, że czas trwania takiej podróży byłby praktycznie zerowy. We wzorze (6) mamy odwrotności zmiennej, dla której liczymy średnią harmoniczną. Zakładając, że wojna trwała znacznie dłużej, aniżeli czas przeżycia na niej najpóźniej poległego żołnierza, możemy przyjąć, że czas życia tych, którzy dotrwali do końca wojny dąży do nieskończoności $x_i \rightarrow \infty$, a wówczas odwrotność takiego czasu dąży do zera: $\frac 1 {\infty} \rightarrow 0$. Zatem możemy policzyć średnią harmoniczną w następujący sposób:
A zatem średni czas przeżycia żołnierza ze wspomnianego oddziału, to 11,11 dnia. Z ciekawości możemy zobaczyć, jaki wyszedłby ten średni czas liczony średnią harmoniczną, gdyby przyjąć czas trwania Drugiej Wojny Światowej. Trwała ona równo sześc lat i dwa dni: zaczęła się ona 1.09.1939 atakiem Trzeciej Rzeszy na Polskę a skończyła kapitulacją Japonii 2.09.1945. Przyjmijmy jednak, jako datę końcową, koniec Drugiej Wojny Światowej w Europie, tj. 8.05.1945. Dostajemy wówczas 2076 dni.
Według średniej arytmetycznej, średni czas przeżycia żołnierza na wojnie – zakładając, że chodzi o Drugą Wojnę Światową w Europie, wyniesie 630,3 dnia. Wcale nie jest trywialnym pytanie, która z tych średnich daje lepszy obraz szans na przeżycie i bardziej realistycznie ocenia te szanse.
„Filozofię” użycia średniej harmonicznej do wyliczenia średniego czasu przeżycia wojny najprościej zrozumieć i wyczuć, biorąc pod uwagę tylko dwóch żołnierzy. Jeden przeżył 10 dni, a drugi doczekał końca wojny. Ich średni czas przeżycia na wojnie, liczony średnią harmoniczną wynosi:
Zatem w takim przypadku, gdy jeden zginął po 10 dniach a drugi dożył końca wojny, średni czas przeżycia wynosi 20 dni.
Tak, czy inaczej, użycie średniej harmonicznej w tym wypadku, choć ciekawe i dające do myślenia, uważam, za wielce dyskusyjne i nie przytoczyłbym tego przykładu, gdyby nie to, że zetknąłem się z nim w mojej praktyce korepetytorskiej, jako z autentycznym przykładem z zajęć na uczelni mojej Klientki.
Czy braki w danych (brak informacji o czasie trwania wojny) bądź tez ich skrajna asymetria – w przykładzie nakładają się oba te czynniki – jest wystarczającym usprawiedliwieniem dla liczenia średniej harmonicznej dla zmiennej niewyrażonej jednostką względną? Może jednak lepiej zostać przy medianie, która też w tym przypadku jest niezła i w większości przypadków da się ją policzyć?
Średnia harmoniczna dla szeregu rozdzielczego
W przypadku szeregu rozdzielczego, gdzie badana zmienna mianowana jest w jednostce, będącej ilorazem innych jednostek, właściwy wybór średniej zależy od tego, w jakiej jednostce wyrażone są liczebności. W przypadku, gdy liczebności wyrażone są w jednostce:
z licznika jednostki analizowanej zmiennej, właściwą średnią jest średnia harmoniczna;
z mianownika jednostki analizowanej zmiennej, właściwą średnią jest średnia arytmetyczna.
Średnią harmoniczną z danych przedstawionych w postaci szeregu rozdzielczego punktowego, oblicza się według wzoru:
Dla szeregu rozdzielczego przedziałowego będzie podobnie – w roli pojedynczych wartości $x_i$ wystąpią środki $\dot x_i$ przedziałów klasowych, choć jest nieco dyskusyjne, czy w sytuacji konieczności użycia średniej harmonicznej,właściwym jest użycie szeregu rozdzielczego przedziałowego, który – jak wspomnieliśmy – na potrzeby liczenia miar klasycznych zakłada, że wszystkie wartości w przedziale są równe, skoro przyjmuje się, że są one równe środkowi przedziału, a zatem średniej arytmetycznej jego krańców. Występuje tu swego rodzaju pomieszanie obu rodzajów średnich.
Przykład 10
Powiat radomszczański składa się z 14 gmin. Poniższa tabela przedstawia dane o gęstości zaludnienia (zmienna $x_i$) oraz ludności tych gmin (liczebność-waga $n_i$) według stanu na 31.12.2024. Należy policzyć średnią gęstość zaludnienia w powiecie radomszczańskim.
Należy bardzo dokładnie podkreślić, że gdyby polecenie brzmiało obliczyć średnią gęstość zaludnienia gminy w powiecie radomszczańskim wówczas można by było policzyć zwyczajną nieważoną średnią arytmetyczną, traktując gminy powiatu radomszczańskiego, jako zbiorowość a powierzchnię, jako cechę. Skoro jednak chodzi o średnią gęstość zaludnienia w powiecie radomszczańskim, czyli niejako średnią gęstość zaludnienia na całej połaci ziemi, zajmowanej przez ten powiat, konieczne jest uwzględnienie liczebności.
Powierzchnia mierzona jest w jednostce względnej $\left[\frac{\mathrm{os}}{\mathrm{km}^2} \right]$, a liczebności podane są w osobach, tj. w jednostce z licznika, konieczne jest użycie średniej harmonicznej, czyli użyjemy wzoru (8). Wartości ilorazów $\frac {n_i} {x_i}$ z mianownika tegoż wzoru, wyliczone zostały w tabeli (zaznaczone na niebiesko).
Średnia harmoniczna gęstości zaludnienia, równa średniej gęstości w powiecie radomszczańskim wynosi zatem:
Średnia gęstość zaludnienia w powiecie radomszczańskim wynosi zatem 73,20 $\frac{\mathrm{os}}{\mathrm{km}^2} $
Zastanówmy się teraz, co tak naprawdę liczyliśmy w naszej tabeli. Czym są obliczone w ostatniej kolumnie wartości ilorazów $\frac {n_i} {x_i}$ ? Otóż dzieląc ludność, mierzoną w osobach przez gęstość zaludnienia wyrażoną w osobach na kilometr kwadratowy, otrzymujemy:
Czyli ostatnia kolumna tabeli, zawierająca wyliczone ilorazy, zawiera de facto powierzchnię każdej z gmin, których suma składa się na całkowitą powierzchnię powiatu radomszczańskiego. Teraz już logicznym jest, że dzieląc ludność powiatu (suma ludności poszczególnych gmin, czyli wartości z przedostatniej kolumny) przez łączną powierzchnię, otrzymujemy ni mniej, ni więcej, tylko średnią gęstość zaludnienia powiatu radomszczańskiego.
Teraz pomyślmy, co by było, gdybyśmy chcieli obliczyć średnią gęstość zaludnienia w powiecie radomszczańskim, mając daną nie ludność każdej gminy, ale jej powierzchnię. Wówczas to niebieskie liczby pełniłyby rolę liczności $n_i$. Jest to jednostka z mianownika, zatem należałoby użyć średniej arytmetycznej i obliczyć ją, ze wzoru (3a).
Wzór ten wymaga wyliczenia iloczynów wartości cechy (czyli gęstości zaludnienia $x_i$ przez liczność. Gdyby licznościami były niebieskie liczby, iloczyny równe byłyby ludności powiatu (obecnym liczebnościom). W takim układzie średnią (ale teraz – arytmetyczną) byłby iloraz tych samych liczb: $\frac {105623}{1443,19}$. Oba sposoby są zatem w 100% ze sobą „kompatybilne”.
Średnia geometryczna
Obliczanie średniej geometrycznej z szeregu szczegółowego
Średnią geometryczną obliczamy analogicznie do średniej harmonicznej, ale zamiast dodawania mamy mnożenie, a zamiast dzielenia – pierwiastkowanie. Wzór na średnią geometryczną w szeregu szczegółowym, to:
Podobnie, jak średnia harmoniczna, tak i średnia geometryczna, obliczone mogą być wyłącznie dla liczb dodatnich. W ostateczności nieujemnych, choć jest oczywistym, że jeśli wśród danych pojawi się choćby jedno zero, to średnia wyliczona ze wzorów (9a) oraz (9b) wyniesie zero.
Warto tutaj poruszyć kwestię nazewnictwa. Jest kilka powodów, dla których nosi ona taką nazwę. Jednym z nich jest to, że może być ona użyta do wyliczenia tzw. kwadratury prostokąta. Jeśli mamy prostokąt o bokach $a = x_1$ oraz $b = x_2$, to średnią geometryczną tych dwu liczb:
można zinterpretować, jako długość boku kwadratu o polu równym polu wspomnianego prostokąta.
Nie tylko to jednak. Jest też sposób na geometryczną konstrukcję odcinka o długości równej średniej geometrycznej długości dwóch danych odcinków – czyli konstrukcyjna kwadratura prostokąta.
Rysunek 1. Ilustracja konstrukcji średniej geometrycznej długości odcinka
Zasada konstrukcji jest prosta. Trójkąt $\triangle {ACD}$ jest prostokątny, jako oparty na półokręgu. Trójkąty $\triangle ABD$ oraz $\triangle DBC$ również są trójkątami prostokątnymi. Są to też trójkąty podobne. $\triangle{ACD} \sim \triangle{ABD}$ na zasadzie kkk (kąt-kąt-kąt)gdyż jest wspólny kąt $\angle{BAD}$. Podobnie $\triangle{ACD} \sim \triangle{BCD}$ z uwagi na wspólny kąt $\angle{BCD}$. Podobieństwo $\triangle{ABD}$ oraz $\triangle{DBC}$ wynika po pierwsze z jednoczesnego ich podobieństwa do $\triangle{ABD}$ a także z równości kątów np. $\angle{BAD} = \angle{BDC}$, co wynika stąd, że miara zarówno kąta $\angle{BAD}$, jak i $\angle{BDC}$ wynosi $90^{\circ} - \angle {ACD}$. Analogicznie też miary kątów $\angle {ADB}$ oraz $\angle {ACD}$ wynoszą $90^{\circ} - \angle {DAC}$
Wobec tego podobieństwa, można dla trójkątów $\triangle{ABD}$ oraz $\triangle{DBC}$zapisać proporcję wynikającą z równości stosunków: dłuższa przyprostokątna do krótszej przyprostokątnej:
$$ \frac {|BD|}{|AB|} = \frac {|BC|}{|BD|}$$
Korzystając z zasady „mnożenia na krzyż”, dostajemy:
$$|BD|^2 = |AB| \cdot |BC|$$
i stąd:
$$|BD| =\sqrt{ |AB| \cdot |BC|}$$
Mamy to. Długość odcinka $BD$ jest średnią geometryczną odcinków $AB$ oraz $BC$. Oczywiście na rysunku widać także średnią arytmetyczną długości tych odcinków. Jest nią jednakowa długość odcinków $AO$ oraz $OB$, bo przecież:
$$|AO| = |OB| = \frac {|AB| + |BC|} 2$$
Kolejnym i chyba najważniejszym powodem, dla którego średnia obliczana wzorem (9a), (9b), nazywa się średnią geometryczną, jest jej związek z ciągiem geometrycznym. Dwa najważniejsze typy ciągów, poznane w szkole średniej, to ciąg:
arytmetyczny, w którym różnica kolejnych wyrazów jest stała (np. 2; 4; 6; 8; …);
geometryczny, w którym iloraz kolejnych wyrazów jest stały (np. 2; 4; 8; 16; …).
W ciągu arytmetycznym, każdy wyraz (oprócz pierwszego i ostatniego) jest średnią arytmetycznąswoich „sąsiadów” z lewej i prawej strony:
$$a_k = \frac {a_{k-1} + a_{k+1}} 2$$
W ciągu geometrycznym, dla każdego z wyrazów (oprócz pierwszego i ostatniego) , spełniony jest warunek:
$$a_k^2 = a_{k-1} \cdot a_{k+1}$$
co dla ciągu o dodatnich wyrazach można utożsamić z zasadą, że każdy wyraz (oprócz pierwszego i ostatniego) jest średnią geometryczną swoich obydwu „sąsiadów”:
$$a_k = \sqrt {a_{k-1} \cdot a_{k+1}}$$
Tyle a propos nazewnictwa.
Średnie tempo zmian
Podręcznikowym, modelowym przykładem sytuacji wymagającej użycia średniej geometrycznej, jest wyliczanie średniego tempa zmian. Otóż jeżeli w kolejnych okresach, tempo zmian wartości zmiennej $y$, wyrażone indeksami łańcuchowymi (tj. stosunkami wartości w okresie bieżącym do wartości w okresie poprzednim:
Jacek co roku dostaje podwyżkę. Od 2020 roku dostał następujące podwyżki: o 20% (w stosunku do 2019) i potem kolejno o 5%, o 25%, 10%, 3%, 5%. Podwyżki te są nieregularne. Jaka jest średnia roczna procentowa wysokość podwyżki, jaką daje Jackowi szef? Innymi słowy, jaką regularną podwyżkę co roku musiałby dawać Jackowi szef, aby w 2025 „wyszło na to samo”?
Najpierw wyznaczmy wartości tempa zmian (czyli indeksów łańcuchowych) wysokości wynagrodzenia w kolejnych latach. Obliczamy to tempo, dodając podane wielkości procentowe do 100%, czyli do jedności. Zatem indeksy te wynoszą: 1,2; 1,05; 1,25; 1,1; 1,03; 1,05. Wartości te posiadają czytelną, praktyczną interpretację: pensja w 2020 roku stanowiła 120% pensji z 2019 roku, pensja w roku 2021 stanowiła 105% pensji z roku 2020 i tak dalej. Innymi słowy, wysokość pensji z roku 2020 otrzymamy mnożąc wysokość pensji z roku 2019 przez 1,2 i kolejne lata analogicznie.
Mnożąc poszczególne wartości tych indeksów, obliczamy łączną podwyżkę, aż do 2025 roku:
Łącznie pensja Jacka w roku 2025 jest wyższa od pensji z roku 2019 o 87,37%. Średnie tempo zmian to taki „procent” podwyżki, który wykonany sześciokrotnie da taka samą, finalną podwyżkę. Jeśli tempo to oznaczymy przez $\bar i_g$, to powyższy warunek oznacza, że musi zachodzić:
Zatem średnie tempo zmian wynosi 1,1103, co oznacza, że gdyby zamiast stóp podwyżek jak w treści zadania, od 2020 szef podnosił Jackowi wypłatę o 11,03% w stosunku do roku poprzedniego, to finalnie w roku 2025 Jacek zarabiałby tyle samo, co teraz.
Jak wynika z obliczeń (12a), (12b), (12c), średnie tempo zmian jest średnią geometryczną indeksów łańcuchowych. Warto tutaj podkreślić, że średnie tempo zmian z indeksów łańcuchowych liczymy tylko wówczas, gdy dysponujemy tylko takimi indeksami. Tak, jak w przykładzie 10. Nie wiemy, ile Jacek zarabiał, znamy tylko stopy procentowe podwyżek.
Kiedy dysponujemy oryginalnymi wielkościami w poszczególnych okresach, nie musimy obliczać indeksów.
Przykład 11
Poniższa tabela przedstawia wartość sprzedaży pewnego przedsiębiorstwa w latach 2019-2024. Obliczyć średnie tempo zmian wartości sprzedaży. Zakładając utrzymanie się takiego tempa, obliczyć prognozę sprzedaży w roku 2025.
Rok
Sprzedaż [tys. zł]
2019
275
2020
280
2021
254
2022
291
2023
305
2024
310
Jak wspomniano, średnie tempo zmian należałoby obliczyć, jako średnią geometryczną indeksów łańcuchowych:
Jak widać, „środkowe” lata się skracają i średnie tempo zmian jest pierwiastkiem odpowiedniego stopnia przez stosunek wartości zmiennej dla ostatniego roku do wartości tej zmiennej dla pierwszego roku, tj.:
Warto zwrócić uwagę, że stopień pierwiastka jest o 1 mniejszy aniżeli ilość lat. Bierze się to stąd, że indeksów łańcuchowych jest zawsze o jeden mniej aniżeli danych, gdyż wyliczenie ewentualnego indeksu łańcuchowego dla roku 2019 wymagałoby znajomości wartości sprzedaży dla roku 2018, a danych takich nie posiadamy.
W latach 2019 – 2024, z roku na rok, sprzedaż wzrastała średnio o 3,04%. Chcąc wyznaczyć prognozę na rok 2025, zakładamy, że tempo to się utrzyma, a zatem sprzedaż będzie wyższa także o 3,04%. Wobec tego:
W przykładzie 11, średnie tempo zmian zostało wykorzystane, jak widać, do prostego prognozowania. Jako metoda prognozowania metoda ta nie jest raczej stosowana – lepsze od niej są metody oparte na trendzie – ale często zadania na średnie tempo zmian są rozszerzone o takie właśnie polecenie.
Oczywiście średnie tempo zmian, obliczone jako średnia geometryczna, może przyjąć wartość mniejszą od jedności. Wówczas interpretuje się ją, jako spadek wartości. Przykładowo $\bar i_g = 0,9745$ oznacza spadek, z roku na rok, średnio o 2,55%. Aby wyliczyć wartość spadku wystarczy bowiem odjąć takie tempo zmian od jedności: $1 - 0,9745 = 0,0255$.
Uwaga praktyczna. Wprawdzie na studiach wypadałoby mieć kalkulator naukowy, jednak wielu studentów takowego sprzętu nie posiada. Barierą jest tu przede wszystkim stosunkowo skomplikowana, zdaniem studentów, obsługa takiego sprzętu. O ile w zamierzchłych, „słusznie minionych” czasach, barierą była cena – markowy zachodni sprzęt nie był dostępny, polskie kalkulatory naukowe były rzadkością (choć istniały) a sprzęt zza Buga kupić można było jedynie „tam”, o tyle dziś w „chińskich” marketach, działający i funkcjonalny kalkulator naukowy kupić można już za 40 zł. Sprzęt porządnej firmy dostać można też za dwucyfrową kwotę.
Dostępne są także aplikacje na smartfony emulujące kalkulator naukowy, ale takie rozwiązanie może nie być akceptowane na kolokwium, czy egzaminie, z uwagi na podejrzenia o korzystanie ze zdalnej pomocy. Do czego jednak zmierzam? Gros studentów posiada tylko podstawowe kalkulatory, ja używam dla nich określenia „sklepowe”. Na kalkulatorach takich nie policzymy pierwiastków dowolnego stopnia i prowadzący zajęcia o tym wiedzą.
Zwyczajny „sklepowy” kalkulator oblicza tylko pierwiastek kwadratowy, zrealizowany jako funkcja jednoargumentowa – wciśnięcie przycisku z symbolem √ powoduje natychmiastowe obliczenie pierwiastka kwadratowego z liczby widocznej na wyświetlaczu. Ponowne wciśnięcie przycisku √ spowoduje obliczenie pierwiastka z tego pierwiastka, czyli pierwiastka czwartego stopnia. Kolejne, trzecie wciśnięcie, wyliczy pierwiastek ósmego stopnia i tak dalej.
Zazwyczaj więc na kolokwiach i egzaminach studenci dostają do wyliczenia takie dane, średnie tempo z tylu lat, że stopień pierwiastka potrzebnego do wyliczenia średniego tempa zmian ze średniej geometrycznej, wynosi 2, 4 (najczęściej) lub 8.
Chcąc kwestię różnic pomiędzy średnią arytmetyczną a geometryczną ogarnąć „na chłopski rozum”, najlepiej przypomnieć sobie zasadę, że średnią arytmetyczną liczymy wówczas, gdy dane podlegają sumowaniu, gdy suma wartości ma sens. No to średnią geometryczną liczymy wówczas, gdy średnia nie ma sensu, natomiast sens ma iloczyn. I tak właśnie jest w przypadku tempa zmian. Gdy w grę wchodzą zmiany procentowe, sens ma mnożenie a nie dodawanie. Stąd właśnie celowość użycia średniej geometrycznej.
Średnia geometryczna na straży uczciwego handlu
Bardzo ciekawe zastosowanie średniej geometrycznej opublikowano w popularnonaukowej książce przeznaczonej dla dzieci: Kowal S. Przez rozrywkę do wiedzy. Rozmaitości matematyczne. WNT, Warszawa 1985. Dotyczy ono pewnego problemu z ważeniem na wadze szalkowej.
Dziś mamy wagi elektroniczne, jednak w pewnych obszarach zastosowań, wciąż stosowane są wagi szalkowe. Wagi szalkowe i inne służą do mierzenia masy różnych obiektów, ale robią to poprzez pomiar jego ciężaru, czyli siły, z jaką masa przyciągana jest przez Ziemię. Pomiar samej masy jest również możliwy, ale wymaga specjalistycznych przyrządów, stosowanych np. na Międzynarodowej Stacji Kosmicznej, gdzie nie można mierzyć masy poprzez ciężar, gdyż nie działa ciążenie.
Otóż waga szalkowa działa na zasadzie porównywania masy ważonego obiektu z masą odważnika. Prawidłowa waga szalkowa jest symetryczna. Wagę taką przedstawiono na rysunku 2.
Rysunek 2. Waga szalkowa o równych ramionach
Waga działa w taki sposób, że umieszczone na szalkach: ważony przedmiot oraz odważnik, chcą obrócić ramię wagi, poprzez działanie momentów, którymi są iloczyny ciężarów (odważnika i ważonego przedmiotu) przez ramię, czyli odległość punktu zawieszenia szalki od osi wagi. Waga jest w równowadze, gdy momenty te są jednakowe.
Niech $m$ oznacza masę ważonego przedmiotu, a $w$ wskazania wagi (tj. masę odważników). Gdy waga jest w równowadze:
$$m \cdot l \cdot g = w \cdot l \cdot g /:lg$$
stąd
$$m = w$$
Waga „pokazuje” wówczas prawdziwą masę ważonego przedmiotu. Jednak w pewnych sytuacjach, np. dla nieuczciwego sprzedawcy, taka rzetelność wagi może nie być korzystna. Jednym ze sposobów „oszukania” wagi szalkowej, jest zastosowanie nierównych ramion wagi. Wagę taką pokazano na rysunku 3.
Rysunek 3. Waga szalkowa o nierównych ramionach
Nierówne ramiona w wadze powodują, że pozostawanie wagi w równowadze nie świadczy o tym, że masa ważonego obiektu jest równa masie położonych na drugiej szalce odważników. Jeśli ważony produkt położony zostanie na lewej szalce, tej z krótszym ramieniem, to zostanie on zrównoważony przez lżejszy odważnik. Waga produktu zostanie zaniżona. Taka sytuacja oczywiście jest niekorzystna dla sprzedającego, gdyż wówczas sprzeda on np. 1,5 kg towaru, licząc kupującemu według wskazań wagi za mniejsza ilość.
Dla sprzedającego korzystna jest sytuacja odwrotna, gdy towar kładziony będzie na prawej szalce, połączonej z dłuższym ramieniem, a odważniki na lewej. Wówczas do zrównoważenia wagi potrzebny będzie odważnik o masie wyższej aniżeli masa ważonego towaru. Masa towaru zostanie więc zawyżona. I o to nieuczciwemu sprzedającemu chodzi.
Jeśli kupujący będzie chciał wykryć taką sytuację, ma kilka możliwości. Może zmierzyć ramiona wagi. Może nakazać sprzedawcy położyć na obu szalkach jednakowe odważniki. Jeśli waga będzie w równowadze – znaczy to, że ma równe ramiona.
Innym sposobem jest dokonanie dwu ważeń: jedno – umieszczając towar na jednej z szalek, odważniki na drugiej a drugie, po zamianie miejscami towaru i odważników. Jeśli oba wskazania będą się różnić, oznacza to, że ramiona wagi nie są równe. Ustalone masy towaru w jednym i drugim ważeniu, różnić się będą od siebie i ani jedna z nich nie będzie prawdziwa. Niższy wynik będzie zaniżony a wyższy – zawyżony. Ile więc towar waży naprawdę?
Niech $m$ oznacza nieznaną masę towaru, $w_1$ oznacza masę odważników w jednym z ważeń (czyli „pierwszy odczyt wagi”) a $w_2$ masę odważników w drugim ważeniu.
Podczas pierwszego ważenia (towar po lewej, odważniki po prawej), warunek równowagi momentów obracających ramiona wagi ma postać:
$$m \cdot g \cdot a = w_1 \cdot g \cdot b\, /:g $$
$$m \cdot a = w_1 \cdot b $$
stąd:
$$m = w_1 \cdot \frac b a \tag {13a} \label {eq:{14a}}$$
podczas drugiego ważenia (odważniki po lewej, towar po prawej):
$$m \cdot g \cdot b = w_2 \cdot g \cdot a\, /:g $$
$$m \cdot b = w_2 \cdot a $$
stąd:
$$m = w_2 \cdot \frac a b \tag {13b} \label {eq:{14b}}$$
Obliczamy wartość $m^2 = m \cdot m$ korzystając ze wzorów (13a) oraz (13b):
A zatem prawdziwa masa przedmiotu ważonego na wadze o nierównych ramionach, jest średnią geometryczną wyników obu ważeń: przed i po zamianie towaru i odważników miejscami! To ciekawe a jednocześnie bardzo praktyczne i „życiowe” zastosowanie średniej geometrycznej.
Średnia geometryczna dla szeregu rozdzielczego
Rzadkością jest obliczanie średniej geometrycznej dla danych uszeregowanych w postaci szeregu rozdzielczego, a zwłaszcza szeregu rozdzielczego przedziałowego – choćby z uwagi na wspomniane wcześniej „pomieszanie średnich” – środki przedziałów klasowych wylicza się, jako średnie arytmetyczne ich krańców, toteż średnia geometryczna tutaj raczej nie pasuje.
Częściej, choć i tak sporadycznie, może się zdarzyć, że danych (np. indeksów łańcuchowych) będzie na tyle dużo, że zostaną one pogrupowane w szereg rozdzielczy punktowy. Wówczas, poprzez analogię do średniej arytmetycznej z takiego szeregu, stosowny wzór na wyliczenie tej miary zapiszemy w postaci:
Kończąc omawiać średnią geometryczną, należy jeszcze rozszerzyć zasadę opisaną nierównością (7), o wzajemne relacje pomiędzy średnią geometryczną, a obiema omówionymi wcześniej średnimi. Otóż prawdziwa jest nierówność:
Zatem średnia geometryczna plasuje się pomiędzy średnią harmoniczną, która jest spośród omawianych średnich najniższą a średnią arytmetyczną, która jest najwyższa. Równość pomiędzy wszystkimi tymi średnimi możliwa jest tylko wówczas, gdy są one obliczane dla zestawu tych samych wartości. Wówczas wszystkie średnie równe są tej wartości (np. dla danych złożonych z samych dwójek: 2; 2; 2; …) wszystkie średnie wynoszą 2.
Średnia kwadratowa
Czym jest średnia kwadratowa?
Średnia kwadratowa, to średnia, która dla danych podanych w postaci szeregu szczegółowego, wyliczana jest według wzoru:
Średnia ta jest pierwiastkiem ze średniej arytmetycznej kwadratów wartości danych.
Gdzie pojawia się średnia kwadratowa
Średnia ta w swojej czystej postaci jest dość rzadko używana w statystyce. Sam schemat obliczania pierwiastków ze średniej obliczonej dla kwadratów jest jednak w statystyce bardzo dobrze znany, gdyż np. odchylenie standardowe jest właśnie obliczane, jako średnia kwadratowa odchyłek danych od średniej:
$$s = \sqrt {\frac 1 n \cdot \left(x_i - \bar x \right)^2} \tag {18} \label {eq:{18}}$$
Widać tutaj najważniejszą cechę średniej kwadratowej – dzięki podnoszeniu uśrednianych wartości do kwadratu, traktuje ona w jednakowy sposób wartości dodatnie i ujemne – co pozwala na obliczenie średniej odchyłki od ustalonej wartości (w przypadku odchylenia standardowego jest to odchylenie od średniej arytmetycznej), bez względu na kierunek tego odchylenia.
Taki sam jest schemat obliczania średniokwadratowego błędu prognozy ex-post. W tym przypadku obliczane są odchyłki nie od średniej, a od empirycznych wartości zmiennej prognozowanej. Na podobnej zasadzie powyższy schemat obliczenia stosowany jest w rachunku błędów.
Oprócz tego w literaturze spotkać można kilka innych zastosowań średniej kwadratowej, które mają charakter „ciekawostek”:
średnia kwadratowa długości podstaw trapezu wyznacza długość linii równoległej do podstaw trapezu, która dzieli trapez na dwa trapezy o jednakowych polach powierzchni;
w termodynamice średnią kwadratową stosuje się do policzenia tzw. średniej kwadratowej prędkości cząsteczek gazu;
w elektrotechnice i teorii sygnałów, schemat obliczania średniej kwadratowej stosuje się do obliczania wartości skutecznej impulsów prądowych (zazwyczaj stosuje się tam całkę zamiast sumy).
Średnia potęgowa
Uogólnienie omówionych średnich
Średnią potęgową dla danych w postaci szeregu szczegółówego, nazywamy parametr statystyczny, obliczany według wzoru, z zastrzeżeniem $p\neq0$:
Średnia ta jest uogólnieniem dotychczas omówionych, średnich:
dla $\boldsymbol p \textbf {=1}$, średnia potęgowa staje się średnią arytmetyczną;
dla $\boldsymbol p \textbf{= -1}$, średnia potęgowa staje się średnią harmoniczną;
dla $\boldsymbol p \textbf{= 2}$, średnia potęgowa staje się średnią kwadratową.
Dodatkowo, definicję średniej potęgowej, określonej wzorem (19) uogólnia się na trzy przypadki szczególne:
dla $\boldsymbol p \textbf{=0}$ przyjmuje się, że średnią oblicza się wg wzorów (9a),(9b), czyli staje się ona średnią geometryczną;
dla $\boldsymbol p \rightarrow \boldsymbol{-\infty}$ średnia potęgowa równa jest $\min \left(x_1,x_2,...,x_n \right)$, a zatem utożsamia się ją z wartością minimalną z szeregu danych;
dla $\boldsymbol p \rightarrow \boldsymbol{+\infty}$ średnia potęgowa równa jest $\max \left(x_1,x_2,...,x_n \right)$, a zatem utożsamia się ją z wartością maksymalną z szeregu danych;
Nierówność średnich
Dzięki uogólnieniu wszystkich uprzednio omówionych średnich na średnią potęgową, możliwe staje się wyrażenie relacji pomiędzy wartościami średnich, wyrażonych wzorami (7) oraz (16) na jedną, prostą regułę. Niech $-\infty \leq p < q +\leq \infty$, wówczas:
przy czym równość zachodzi tylko wtedy, gdy $x_1 = x_2 = ... = x_n$. Aby możliwe było wyliczenie uogólnionej średniej potęgowej, dla każdej wartości $p$ konieczne będzie także założenie: $x_i > 0$ dla $1 \leq i \leq n$.
Ma to sens. Przy okazji omawiania średniej harmonicznej wspominaliśmy, że „ciąży” ona ku wartościom niskim a wartości wysokie – nawet nieskończone – nie robią na niej większego wrażenia. Średnia kwadratowa z kolei, przeciwnie. Wartości wysokie mają jeszcze wyższe kwadraty, toteż wartość średniej jest ku nim bardziej przesuwana, aniżeli ma to miejsce w przypadku średniej arytmetycznej. Zasada, wyrażona wzorem (20), to piękne i kompleksowe podsumowanie tych prawidłowości.
Podsumowanie
W powyższym artykule nie przedstawiliśmy najważniejsze charakterystyki średnich klasycznych, stosowanych w statystyce opisowej. Warto tutaj zaznaczyć, że nie ma lepszych i gorszych średnich, są tylko średnie źle i dobrze dobrane. Z omówionych średnich, na pierwszy rzut oka, najlepsza i wręcz idealna wydaje się średnia arytmetyczna. Wszak „leży ona dokładnie pośrodku”. Np. dla liczb 6 oraz 8 idealną średnią wydaje się 7. Takie jednak myślenie to pułapka!
Idealizując średnią arytmetyczną tylko dlatego, że „lezy pośrodku”, myślimy właśnie kategoriami średniej arytmetycznej. A nic dziwnego, że myśląc kategoriami tej miary, to właśnie ją uznajemy za najlepszą. Jednak średnia nie musi leżeć pośrodku, aby być odpowiednią miarą. Wyobraźmy sobie dwie sytuacje:
przeprowadziliśmy dwie transakcje – na jednej zarobiliśmy 200 zł a na drugiej straciliśmy 200 zł; ile zarobiliśmy w sumie i średnio na transakcji? Odpowiedź brzmi, oczywiście, zero! Tak, tutaj myślenie kategoriami średniej arytmetycznej jest OK, ale:
przeprowadziliśmy dwie transakcje – na jednej zarobiliśmy 20% a na drugiej straciliśmy 20%; ile zarobiliśmy w sumie i średnio na transakcji? Bynajmniej nie zero! Na jednej transakcji nasz majątek pomnożył się przez 1,2 a na drugiej przez 0,8; per saldo więc przemnożył się on przez 0,96 i w sumie straciliśmy 4%! Tu myślenie kategoriami średniej arytmetycznej zawodzi. Już lepszą odpowiedzią będzie, że średnio na transakcji straciliśmy po 2%, choć najlepiej policzyć $\sqrt{0,96} = 0,9798$ i prawidłowa odpowiedź brzmi: średnio na każdej z transakcji straciliśmy po 2,02%. W przypadku zmian procentowych należy myśleć kategoriami średniej geometrycznej!
A wszystko dlatego, że … średnia niejedno ma imię.
W tym artykule zajmiemy się wyznacznikiem macierzy kwadratowej, który stanowi bardzo ważną charakterystykę macierzy kwadratowej i jest niezbędny do wyliczenia macierzy odwrotnej, a także stanowi podstawę obliczenia takich charakterystyk, jak rząd macierzy, czy wartości własne macierzy. Pełni także bardzo ważną rolę w rozwiązywaniu układów równań liniowych.
Ważna informacja
Niektóre przeglądarki nie renderują we właściwy sposób pionowych linii, w które ujęta jest macierz przy obliczaniu wyznacznika. W takiej sytuacji prosimy zaktualizowac przeglądarkę lub zobaczyć wygląd strony w innej przeglądarce.
Czym jest wyznacznik?
Najkrócej rzecz ujmując, wyznacznik jest liczbą charakteryzująca każdą macierz kwadratową. Formalna definicja wyznacznika macierzy kwadratowej jest dość skomplikowana i odwołuje się do pojęcia permutacji. Dla przypomnienia – permutację w skrócie można określić jako każde z możliwych ułożeń elementów danego zbioru. Np. dla zbioru ${A, B, C}$ możliwe permutacje, to $ABC$, $ACB$, $BAC$, $BCA$, $CAB$, $CBA$. Ilość wszystkich permutacji $n$-elementowego zbioru, to $n!$.
i sumowanie rozciąga się na wszystkie $n!$ permutacji $j_1, j_2, ..., j_n$ liczb $1, 2, ..., n$. Wartość odwzorowania $\det(\mathbf{A})$, $\mathbf{A} \in G_n$ nazywamy wyznacznikiem stopnia $n$macierzy $\mathbf{A}$, lub krótko wyznacznikiem i piszemy:1
Wyznacznik macierzy kwadratowej $\mathbf{A}$ oznacza się, jak wspomniano wyżej, przez $\det \mathbf{A}$, $|\mathbf{A}|$, bądź też w postaci (1), czyli umieszczając elementy macierzy pomiędzy pionowymi liniami, zamiast między nawiasami kwadratowymi.
Należy pamiętać, że w zapisie (1) tak naprawdę wyznacznikiem jest jedna liczba, obliczona jednym z opisanych dalej sposobów, a nie te umieszczone pomiędzy liniami liczby! Ponadto, w przypadku macierzy jednoelementowej, zapis $|a_{11}|$ może być mylący, gdyż wygląda identycznie, jak wartość bezwzględna, a jak się dalej okaże, taki wyznacznik równy jest elementowi $a_{11}$ także wówczas, gdy jest on ujemny. W takiej sytuacji, jeśli chcemy stosować zapis z liniami, najlepiej zapisywać wyznacznik w taki sposób: $\left| [a_{11}] \right|$.
Obliczanie wyznacznika w praktyce
W praktyce, obliczanie wyznacznika jest znacznie prostsze. Uniwersalny algorytm obliczania wyznacznika można przedstawić w dwu krokach:
Dla macierzy kwadratowej $1 \times 1$, tj. dla $n=1$ wyznacznik macierzy równy jest jedynemu elementowi macierzy: $\det [a_{11}] = a_{11}$.
Dla macierzy kwadratowej o większym wymiarze niż 1 (dla $n>1$) stosujemy rozwinięcie Laplace’a.
Rozwinięcie Laplace’a (rozwinięcie wyznacznika na podwyznaczniki)
Rozwinięcie Laplace’a polega na wyborze dowolnego wiersza lub kolumny (tylko jednego/jednej!) oraz obliczenie wyznacznika, jako sumy iloczynów elementów tego wiersza przez podwyznaczniki, czyli wyznaczniki macierzy uzyskanej poprzez skreślenie (wyeliminowanie) wiersza oraz kolumny danego elementu oraz przez wyrażenie $(-1)^{i+j}$, gdzie $i$, $j$ są odpowiednio numerami wiersza oraz kolumny tego elementu.
Można to zapisać w następujący sposób. Jeśli wybierzemy $i$-ty wiersz:
$M_{ij}$ oznacza właśnie podwyznacznik (minor) macierzy $\mathbf{A}$, czyli wyznacznik macierzy uzyskanej poprzez wyeliminowanie z macierzy $\mathbf{A}$ $i$-tego wiersza oraz $j$-tej kolumny.
Przykład 1
Obliczmy tym sposobem wyznacznik macierzy $\mathbf{A}=\begin{bmatrix} 1 & 2 \\ 2 & 5 \end{bmatrix} $. Wybierzmy pierwszy wiersz:
Jak widać, obliczamy dwa iloczyny „po przekątnej”, przy czym od iloczynu elementów leżących na diagonali odejmujemy iloczyn elementów leżących na drugiej przekątnej.
Sposób ten omawiany jest w szkole średniej, gdzie wyznaczników używa się do badania rozwiązywalności układów dwóch równań liniowych z dwiema niewiadomymi. W szkole średniej pojęcie wyznacznika wprowadza się w oderwaniu od pojęcia macierzy.
Schemat Sarrusa
Do wyznaczników $3 \times 3$, jako alternatywę dla rozwinięcia Laplace’a, stosuje się specjalny, skrócony schemat obliczania wyznacznika, nieco przypominający omówiony wyżej schemat obliczania wyznacznika $2 \times 2$.
Schemat Sarrusa polega na powtórzeniu dwu pierwszych wierszy macierzy i przepisania ich pod trzecim wierszem, albo powtórzenia dwu pierwszych kolumn i przepisania ich z prawej strony trzeciej kolumny. Dopisane wiersze (kolumny) pozwalają na utworzenie w sumie sześciu „przekątnych”.
Schemat powtórzenia dwu pierwszych kolumny przedstawia poniższy rysunek. Przekątne biegnące w tym samym kierunku, co diagonala $a_{11} a_{22} a_{33}$ traktujemy, jako „dodatnie”, natomiast przekątne biegnące w drugim, prostopadłym kierunku, traktujemy, jako ujemne.
Porównując dwa powyższe sposoby obliczania wyznaczników $3 \times 3$ może się wydawać, że schemat Sarrusa jest nieco szybszy od rozwinięcia Laplace’a. Są jednak sytuacje, że rozwinięcie Laplace’a jest bardziej efektywne. Jednym z przykładów może być tutaj obliczanie iloczynu wektorowego dwóch wektorów w $\mathbb{R}^3$. Wektorom oraz działaniom na nich poświęcony będzie osobny artykuł. Tutaj przedstawimy tylko pokrótce schemat obliczania takiego iloczynu:
$$\vec a \times \vec b =\begin{bmatrix}a_x & a_y & a_z \end{bmatrix} \times \begin{bmatrix}b_x & b_y & b_z \end{bmatrix} = \begin{vmatrix} \vec i & \vec j & \vec k \\a_x & a_y &a_z \\ b_x & b_y &b_z \end{vmatrix} $$
Obliczając wartość wyznacznika z rozwinięcia Laplace’a względem pierwszego wiersza uzyskujemy od razu wyrażenie pogrupowane według współczynników przy wersorach $\vec i$, $\vec j$, $\vec k$.
$$ 5 \vec i + 2 \vec j - 3 \vec k = \begin{bmatrix} 5&2&-3 \end{bmatrix}$$
Zauważmy, że obliczanie wyznacznika za pomocą rozwinięcia Laplace’a, może być znacznie łatwiejsze, jeśli w macierzy pojawią się zera. Wybór wiersza lub kolumny, zawierających zera znacząco zmniejsza ilość składników wyrażenia (2a) lub (2b). Oczywiście można mieć szczęście i dostać do obliczenia wyznacznik macierzy zawierającej sporo zer, ale okazuje się, że szczęściu temu można znacząco pomóc, wykorzystując pewne własności wyznacznika.
Własności wyznacznika – część 1
Bardzo użytecznymi własnościami wyznacznika są przekształcenia macierzy, niezmieniające jego wartości.
Wyznacznik zawierający wiersz lub kolumnę składającą się z samych zer równy jest zero.
Wyznacznik zawierający dwa proporcjonalne wiersze (lub dwie proporcjonalne kolumny) równy jest zero. Szczególnym przypadkiem proporcjonalności jest identyczność – równy zero jest także wyznacznik zawierający dwa identyczne wiersze (lub dwie identyczne kolumny).
Zamiana dwóch wierszy (lub kolumn) w wyznaczniku powoduje zmianą znaku wyznacznika na przeciwny.
Pomnożenie dowolnego wiersza (lub kolumny) wyznacznika przez tę samą liczbę $k$ skutkuje pomnożeniem wartości wyznacznika przez liczbę $k$.
Wartość wyznacznika nie ulegnie zmienia, jeśli do dowolnego wiersza (albo kolumny) doda się elementy innego wiersza (albo odpowiednio kolumny), pomnożone przez tę samą, dowolną liczbę.
Własność nr 2 wynika z własności nr 3. Skoro bowiem zamiana miejscami dwu wierszy, bądź kolumn zmienia znak na przeciwny, to przy identycznych dwu wierszach albo kolumnach, macierz przed i po zamianie wygląda tak samo, a skoro zamiana zmienia znak wyznacznika na przeciwny, to oznacza, że wyznacznik ten musi być równy zero.
Z kolei biorąc pod uwagę własność nr 5, to przy wystąpieniu dwóch identycznych bądź proporcjonalnych wierszy, zawsze można jeden wiersz pomnożyć przez liczbę przeciwną do współczynnika owej proporcjonalności zerując cały wiersz (kolumnę) i wtedy, na mocy własności nr 1, wyznacznik równa się zero. A skoro własność nr 5 nie zmienia wartości, to wyznacznik niejako „od początku” musiał być równy zero.
Własność nr 5 jest bardzo ważna, gdyż umożliwia ona „generowanie” zer tam, gdzie pierwotnie ich nie było. Korzystanie z tej własności należy rozumieć w sposób właściwy. Po pierwsze: do elementów wiersza możemy dodać tylko elementy innego wiersza a do elementów kolumny – elementy innej kolumny (tj. nie wolno dodawać elementów wiersza do elementów kolumny). Po drugie, wspomniane mnożenie wykonujemy „w pamięci”. Dodawane – źródłowy wiersz, bądź kolumna – nie zmieniają się, zmianie ulega tylko wiersz (kolumna) docelowy.
Bardzo często, dla oznaczenia powyższych operacji, stosuje się zapis:
dla operacji na wierszach: $w_s \cdot a + w_d \rightarrow w_d$,
dla operacji na kolumnach: $k_s \cdot a + k_d \rightarrow w_k$.
gdzie: $w_s$, $k_s$ oznaczają, odpowiednio: wiersz oraz kolumnę źródłową, $w_d$, $k_d$ – wiersz oraz kolumnę docelową, $a$ – użytą liczbę.
Jeśli elementy jednego wiersza (bądź kolumny), pomnożone przez wybrane liczby, chcemy dodać do elementów kilku innych wierszy (kolumn), można taką operacje przeprowadzić niejako „w jednym kroku”
Na pierwszy rzut oka obliczenie z wykorzystaniem rozwinięcia Laplace’a wygląda na bardzo pracochłonne. Wybierając dowolny wiersz, albo kolumnę, wyznacznik rozwinąć można na pięć wyznaczników $4 \times 4$, z których z kolei każdy musi być rozwinięty na cztery wyznaczniki $3 \times 3$, co daje aż dwadzieścia takich wyznaczników do obliczenia schematem Sarrusa. Jeśli i te wyznaczniki zechcemy rozwinąć za pomocą rozwinięcia Lapalce’a, to łącznie otrzymamy aż sześćdziesiąt wyznaczników $2 \times 2$.
Obliczenia ułatwiłoby wystąpienie jakichś zer. Skoro zer tych nie ma, można je „wygenerować” za pomoca opisanego przekształcenia. Najlepszym punktem wyjścia do wykonania przekształceń, jest wybór jakiegoś elementu równego 1. Jeśli takiego elementu by nie było, można go oczywiście wygenerować. Przykładowo na pozycji $(1; 3)$ znajduje się liczba 4, zaś na pozycji $(1; 4)$ jest liczba 3. Można by więc dodać do elementów trzeciej kolumny, elementy czwartej kolumny pomnożone przez -1.
W naszym jednak przypadku nie ma takiej potrzeby, gdyż mamy kilka elementów równych 1. Załóżmy, że wybierzemy element $a_{41}$. Dzięki temu elementowi można sprawić, że wszystkie pozostałe elementy w pierwszej kolumnie staną się zerami. Dokonamy tego w następujący sposób:
do elementów pierwszego wiersza dodajemy elementy czwartego wiersza pomnożone przez -2;
do elementów drugiego wiersza dodajemy elementy czwartego wiersza pomnożone przez -2;
do elementów trzeciego wiersza dodajemy elementy czwartego wiersza pomnożone przez -3;
do elementów piątego wiersza dodajemy elementy czwartego wiersza pomnożone przez 2.
Przekształcenia te można zapisać symbolicznie:
$w_4 \cdot (-2) + w_1 \rightarrow w_1$,
$w_4 \cdot (-2) + w_2 \rightarrow w_2$,
$w_4 \cdot (-3) + w_3 \rightarrow w_3$,
$w_4 \cdot 2 + w_5 \rightarrow w_5$.
Uwzględniając powyższe przekształcenia, można zapisać:
Sytuacja znacząco się poprawiła. Nie dość, że – zgodnie zresztą z celem dokonanych przekształceń – w pierwszej kolumnie wszystkie elementy poza „naszą” jedynką są zerami, to jeszcze dodatkowo pojawiły się zera w ostatnim wierszu. Wyznacznik można teraz policzyć rozwijając go względem pierwszej kolumny. Wówczas kontynuacja naszych obliczeń wygląda następująco:
W zasadzie już teraz można rozwinąć wyznacznik względem czwartego wiersza. Zawiera on tylko dwa elementy niezerowe, toteż można go rozwinąć tylko na dwa wyznaczniki $3 \times 3$, zamiast czterech. Jednak zauważyć można, że mnożąc elementy trzeciej kolumny przez -2 i dodając je do elementów czwartej kolumny uzyskamy dwa zera (-5 oraz -4 wyzerują elementy -10 oraz -8) a dodatkowo na pierwszej pozycji pojawi się liczba 1.
Symbolicznie operację tę zapisać można jako: $k_3 \cdot (-2) + k_4 \rightarrow k_4$. Kontynuacja obliczeń wygląda tak:
Teraz można dodać elementy pierwszego wiersza do elementów czwartego wiersza. Dwa zera, niestety, „popsują” się, ale w czwartej kolumnie pojawi się tylko jeden element niezerowy i będzie to jedność. Przekształcenie to można zapisać symbolicznie: $w_1 \cdot 4 + w_4 \rightarrow w_4$.
Na uwagę zasługują także inne własności wyznacznika.
Transpozycja nie zmienia wartości wyznacznika: $\det \mathbf{A}^{\top} = \det \mathbf{A}$,
Wyznacznik iloczynu macierzy równy jest iloczynowi wyznaczników tych macierzy: $\det \left(\mathbf{A} \cdot \mathbf{B} \right) = \det \mathbf{A} \cdot \det \mathbf{B}$
Wyznacznik macierzy odwrotnej równy jest odwrotności wyznacznika danej macierzy: $\det \mathbf{A}^{-1} = {1 \over {\det \mathbf{A}}}$
Wyznacznik iloczynu macierzy
Bardzo ciekawa jest własność oznaczona na mojej liście numerem 7. Jej prawdziwość dla wybranych macierzy kwadratowych czytelnik może sprawdzić. Dla dowolnych macierzy kwadratowych co ambitniejsi czytelnicy również mogą przeprowadzić stosowny dowód. Można go znaleźć też w Internecie. Ale…
Ich iloczyn wynosi $\mathbf{A} \cdot \mathbf{B} = \begin{bmatrix} 8 & 13 \\ 6 & 11 \end{bmatrix}$ a wyznacznik tego iloczynu: $\det \left( \mathbf{A} \cdot \mathbf{B} \right) = \begin{vmatrix} 8 & 13 \\ 6 & 11 \end{vmatrix} = 10$
A co, jeśli wzór $\det \left(\mathbf{A} \cdot \mathbf{B} \right) = \det \mathbf{A} \cdot \det \mathbf{B}$ jest prawdziwy nie tylko dla macierzy prostokątnych, ale dla dowolnych macierzy? Być może da się odkryć, jakieś ciało (zbiór liczb i działań), w którym macierze prostokątne również posiadają wyznaczniki? Wówczas wyznacznik macierzy prostokątnej $\det \mathbf{A}$ oraz wyznacznik macierzy prostokątnej $\det \mathbf{B}$ byłyby jakimiś liczbami spoza zbioru liczb rzeczywistych, których iloczyn wynosiłby 10?
Absurdalne? Niezupełnie. Pod koniec XVI wieku, francuski matematyk François Viète podał wzór pozwalający wyliczać iloczyn pierwiastków trójmianu kwadratowego $ax^2 + bx + c$, czyli rozwiązań równania $ax^2 + bx + c=0$ bez wyliczania tych rozwiązań.
Wzór był tak „dobry”, że wyliczał sumę oraz iloczyn pierwiastków trójmianu także i wtedy, gdy trójmian ten ich nie posiadał. Przykładowo dla trójmianu $x^2+2x+2$ wyliczał sumę jego pierwiastków:$x_1 + x_2 = -2$ oraz iloczyn $x_1 \cdot x_2 = 2$ A trójmian taki nie posiada pierwiastków, gdyż jego wyróżnik $\Delta=-4$. Takie było przynajmniej oficjalne stanowisko matematyki za czasów pana Viète’a. Tak więc oficjalnie, jego wzór był prawdziwy tylko pod warunkiem, że $\Delta \geq 0$.
Minęło jednak pół wieku i odkryto liczby urojone oraz zespolone i okazało się, że wzory Viète’a działają zawsze! A trójmian $x^2+2x+2$ ma pierwiastki zespolone $x_1 = -1-i$ oraz $x_2=-1+i$ i rzeczywiście ich suma wynosi -2 a iloczyn wynosi 2.
Być może algebra macierzy również czeka na swego Kartezjusza i Eulera? Oczywiście sprawa nie jest taka prosta, gdyż iloczyn naszych macierzy „w drugą stronę” wynosi: $\mathbf{B} \cdot \mathbf{A} = \begin{bmatrix} 5 & 4 & 7 \\ 4 & 5 & 8 \\ 7 & 5 & 9 \end{bmatrix} $ a wyznacznik uzyskanego iloczynu:
Jeśli więc komuś uda się odkryć ciało algebraiczne, którego elementami będą wyznaczniki macierzy prostokątnych, to z pewnością mnożenie w tym ciele nie będzie przemienne. Poza tym odkryć strukturę algebraiczną i ją opisać, to jedno, a znaleźć dla niej jakieś praktyczne zastosowanie, by uzasadnić jej włączenie do kanonu matematyki wyższej, to inna sprawa. Liczby zespolone na swoje miejsce w realnym świecie czekać musiały ponad 200 lat, gdyż dopiero wynalezione u schyłku XVIII wieku: prąd przemienny oraz fale radiowe znalazły dla nich praktyczne zastosowanie.
Macierze osobliwe
W rachunku macierzy bardzo często ważne jest, czy wyznacznik macierzy kwadratowej jest równy zero. Macierze, których wyznacznik równy jest zero, noszą nazwę macierzy osobliwych i najważniejszą ich cechą jest to, iż macierz osobliwa nie posiada macierzy odwrotnej. Koresponduje to z własnością nr 8 na powyższej liście. Skoro wyznacznik macierzy odwrotnej jest odwrotnością wyznacznika danej macierzy, to macierz odwrotna do macierzy o wyznaczniku równym zero, czyli macierzy osobliwej, nie istnieje.
Zastosowanie wyznacznika
Wyznaczniki macierzy kwadratowej znajdują bardzo szerokie zastosowanie w algebrze, a także w analizie matematycznej oraz innych działach matematyki. Przede wszystkim służy do wyznaczania różnego rodzaju wartości i charakterystyk związanych bezpośrednio z macierzami, takich jak macierz odwrotna, rząd macierzy czy wartości własne macierzy.
Wykorzystanie wyznacznika do obliczania macierzy odwrotnej oraz rzędu macierzy oznacza, że wyznacznik macierzy służyć może również do badania rozwiązywalności układów równań liniowych i do wyznaczania samych rozwiązań.
Z wyznaczników korzysta się w algebrze i geometrii analitycznej – do badania współliniowości wektorów, obliczanie iloczynu wektorowego wektorów, jak pokazano to w przykładzie nr 3, do badania określoności form kwadratowych. W analizie matematycznej, wyznaczników używa się do wyznaczania ekstremów funkcji wielu zmiennych, czy też do rozwiązywania równań różniczkowych .
Metoda Cramera
Metoda Cramera, zwana niekiedy metodą wyznacznikową, to oparta na wyznacznikach metoda rozwiązywania układu równań liniowych, w których ilość równań równa jest ilości niewiadomych. Tego typu układ równań:
Czyli wyznacznik macierzy otrzymanej z macierzy współczynników układu równań (4) poprzez zastąpienie $k$-tej kolumny, kolumną wyrazów wolnych. Po obliczeniu wartości wyznaczników określonych wzorem (6), wartości niewiadomych w rozwiązaniu układu wyliczamy ze wzorów:
W sytuacji, gdy wyznacznik główny układu $W$, obliczony ze wzoru (5) równy jest zero: $W = 0$, może zachodzić jeden z dwu przypadków:
gdy ponadto wszystkie wyznaczniki $W_k$ równe są zero, tj. $W_1 = W_2 = ... = W_n = 0$, wówczas układ (4) posiada nieskończenie wiele rozwiązań, przy czym dla $n > 2$ dokładniejsze wyznaczenie tych rozwiązań, czyli np. ustalenie ilości parametrów, od których one zależą, wymaga dokładniejszego zbadania tego układu, w oparciu o twierdzenie Kroneckera-Capellego;
gdy którykolwiek (choćby jeden) z wyznaczników $W_k$ jest różny od zera, układ równań (4) jest układem sprzecznym, czyli nie posiada rozwiązań.
Metodę Cramera można potraktować jako alternatywę dla „klasycznych” metod rozwiązywania układów równań, jak np. metoda podstawiania, czy metoda przeciwnych współczynników. Jest to metoda często zapomniana i niedoceniana, gdyż bywają przypadki, że to właśnie ona jest najszybsza i najwygodniejsza.
Jest to układ równań dość kłopotliwy, zarówno jeśli chodzi o metodę podstawiania, jak i przeciwnych współczynników. Tymczasem w metodzie wyznacznikowej (Cramera) wyliczamy wartości trzech wyznaczników. Wyznacznik główny układu jest równy:
Wyznacznik ten jest różny od zera, zatem układ (8) posiada dokładnie jedno rozwiązanie. Obliczamy wartości wyznaczników dla poszczególnych niewiadomych, zastępując poszczególne kolumny niewiadomych, kolumną wyrazów wolnych:
Stankiewicz W. Zadania z matematyki dla wyższych uczelni technicznych, część I.A, PWN, Warszawa 1998, s. 71. ↩︎
Sebastian Dziarmaga-Działyński
Macierze – część 1.
mgr inż.
Sebastian Dziarmaga-Działyński
Wprowadzenie
Artykuł o macierzach zdecydowałem się podzielić na dwie części. Część pierwsza obejmuje zakres materiału przed wprowadzeniem pojęcia wyznacznika, któremu poświęcony będzie osobny artykuł, a część druga – materiał po wprowadzeniu wyznacznika. Z macierzami generalnie stykamy się dopiero na studiach, choć pojęcie wyznacznika (jako tworu samoistnego) pojawia się w programie nauczania szkoły średniej (zakres rozszerzony) przy okazji dyskusji rozwiązywalności układów równań.
Co to jest macierz?
Formalna definicja macierzy może nieco przerażać. Według niej bowiem macierzą nad ciałem $K$ nazywamy następujące odwzorowanie:
Jeśli za ciało $K$ przyjmiemy zbiór liczb rzeczywistych $=\mathbb{R}$, wówczas macierz możemy potraktować jako funkcję:
$$f: \mathbb{N}^2 \rightarrow \mathbb{R}$$
Czyli funkcję przyporządkowująca parze liczb naturalnych $(i, j)$ pewną liczbę rzeczywistą. Jeśli teraz tę parę liczb potraktujemy jako, odpowiednio: numer wiersza i numer kolumny, to dostaniemy to, z czym się macierz najczęściej kojarzy, czyli po prostu liczby uporządkowane w formie dwuwymiarowej tablicy.
Macierze oznaczamy najczęściej wielkimi literami alfabetu (używamy czcionki pogrubionej) a wspomnianą tablicę liczb ujmujemy w prostokątne nawiasy.
Jest to macierz o $m$ wierszach oraz $n$ kolumnach. Oznaczamy to zwykle $m \times n$ określamy mianem wymiaru macierzy. Ważne jest, by określając wymiar macierzy podawać najpierw ilość wierszy, a potem ilość kolumn.
Rodzaje macierzy
Macierze kwadratowe oraz wektory
Ze względu na wymiar macierzy, wyróżniamy pewne szczególne ich rodzaje:
macierzami kwadratowymi nazywamy macierze, dla których $m = n$,
wektorami, nazywamy macierze, dla których $m=1$ (jednowierszowe) lub $n=1$ (jednokolumnowe).
Szczególnym rodzajem macierzy jest macierz kwadratowa $1 \times 1$, którą utożsamia się z jedynym jej elementem $a_{11}$ – tj. traktuje się ją, jako skalar.
Wyróżnienie macierzy kwadratowych jest bardzo ważne, gdyż pewne operacje i charakterystyki obliczane mogą być wyłącznie dla macierzy kwadratowych.
Macierz zerowa
Macierz (dowolnego wymiaru), której wszystkie elementy są zerami, określana jest mianem macierzy zerowej.
Macierz zerowa stanowi macierzowy odpowiednik liczby zero.
Rodzaje macierzy kwadratowych
Macierzami kwadratowymi, jak wspomniano, są macierze $m \times n$, dla których $m=n$. W macierzy takiej szczególną rolę odgrywają liczby $a_{11}, a_{22}, ..., a_{nn}$, tworzące tzw. główną przekątną macierzy kwadratowej, zwanej inaczej diagonalą tej macierzy. Główna przekątna ma duże znaczenie, zwłaszcza w kontekście obliczeń numerycznych przeprowadzanych na macierzach. Niektóre z tych metod „nie działają”, gdy na przekątnej tej znajduje się liczba zero.
Macierz diagonalna
Macierz diagonalna to macierz kwadratowa, której wszystkie elementy nieleżące na głównej przekątnej równe są zero: $a_{ij} = 0$, dla $i \neq j$.
Nie oznacza to oczywiście, że w macierzy diagonalnej wszystkie elementy leżące na głównej przekątnej muszą być różne od zera – kwadratowa macierz zerowa (2) również może być traktowana, jako szczególny rodzaj macierzy diagonalnej.
Macierz jednostkowa
Macierzą jednostkową nazywamy taką macierz diagonalną, której wszystkie elementy leżące na głównej przekątnej są jednościami: $a_{11} = a_{22} = ... = a_{nn} = 1$:
Macierz jednostkowa odgrywa istotną rolę w rachunku macierzowym i w pewnym sensie stanowi macierzowy odpowiednik jedności. Będzie to omówione przy okazji omawiania działań na macierzach.
Macierz skalarna
Macierzą skalarną nazywamy taką macierz diagonalną, której wszystkie elementy są równe.
Oczywiście w macierzy trójkątnej górnej nie wszystkie elementy powyżej diagonali muszą być niezerowe i podobnie w macierzy trójkątnej dolnej nie wszystkie elementy poniżej diagonali muszą być niezerowe. W tym kontekście, macierz diagonalna jest jednocześnie macierzą trójkątną górną oraz dolną.
Macierze trójkątne są istotne w kontekście rozwiązywania układów równań liniowych oraz podczas dekompozycji macierzy. Wykorzystuje się je także w algorytmach takich jak eliminacja Gaussa. W praktyce, macierze trójkątne mogą znacznie uprościć obliczenia, zwłaszcza podczas mnożenia macierzy.
Macierz symetryczna
Macierzą symetryczną nazywamy macierz kwadratową, dla której zachodzi równość: $a_{ij} = a_{ji}$.
Jeśli uwzględnimy operację transpozycji macierzy, macierz symetryczną można zdefiniować, jako macierz, dla której zachodzi $\mathbf{A}=\mathbf{A}^{\top}$.
Macierz skośnie symetryczna
Macierzą symetryczną nazywamy macierz kwadratową, dla której zachodzi równość: $a_{ij} = -a_{ji}$. Z warunku tego wynika, że w macierzy skośnie symetrycznej, wszystkie elementy leżące na głównej przekątnej są zerami: $a_{11} = a_{22} = ... = a_{nn} = 0$.
Jeśli uwzględnimy operację transpozycji macierzy, macierz symetryczną można zdefiniować, jako macierz, dla której zachodzi $\mathbf{A}=-\mathbf{A}^{\top}$.
Równość macierzy
Dwie macierze są równe, wtedy i tylko wtedy, gdy mają identyczne wymiary oraz odpowiadające sobie elementy są równe. Oznacza to, że dla macierzy $\mathbf{A}$ o wymiarze $m \times n$ i macierzy $\mathbf{B}$ o takim samym wymiarze, musi zachodzić warunek: \( a_{ij} = b_{ij} \) dla każdego $i$, $j$. Tj. w zapisie formalnym:
W praktyce, porównywanie macierzy polega na sprawdzeniu wszystkich ich elementów. Równość macierzy ma istotne znaczenie np. przy rozwiązywaniu układów równań liniowych metodą macierzową.
W algebrze macierzy nie ma zdefiniowanych takich relacji, jak większa, czy mniejsza. Równość macierzy albo zachodzi, albo nie zachodzi.
Działania na macierzach
Działania jednoargumentowe – cz. 1
Transpozycja macierzy
Transpozycją (transponowaniem) macierzy nazywamy działanie, która polega na „zamianie wierszy na kolumny”. Dla macierzy $\mathbf{A}$ o wymiarze $m \times n$, macierz transponowana oznaczana jako $\mathbf{A}^{\top}$ i ma ona wymiar $n \times m$. Oznacza to, że elementy macierzy transponowanej są definiowane jako $a_{ji} = a_{ij}$. Transpozycja jest użyteczna w wielu dziedzinach matematyki, w tym w analizie danych oraz w teorii grafów. W kontekście układów równań liniowych, transpozycja pozwala na przekształcanie równań do innej formy, co może ułatwić ich rozwiązanie.
Ślad macierzy
Śladem macierzy kwadratowej $\mathbf{A}$, co oznaczamy $\mathrm{tr}{\mathbf{A}}$ nazywamy sumę elementów leżących na głównej przekątnej: $\mathrm{tr}{\mathbf{A}} = a_{11} + a_{22} + ... +a_{nn}$.
Kolejną jednoargumentową operacją, która należałoby omówić, jest odwracanie macierzy. Operacja ta zostanie omówiona w innym artykule, gdyż do wyznaczenia macierzy odwrotnej należy, między innymi, obliczyć wartość wyznacznika macierzy.
Działania dwuargumentowe
Mnożenie macierzy przez skalar (liczbę)
Iloczyn macierzy $\mathbf{A}$ (wzór (1)) przez liczbę $c$ obliczamy ze wzoru:
rozdzielność względem dodawania macierzy: $b \cdot (\mathbf{A} + \mathbf{B}) = b \cdot \mathbf{A} + c \cdot \mathbf{B}$,
rozdzielność względem dodawania skalarów: $(b + c) \cdot (\mathbf{A} = b \cdot \mathbf{A}) + c \cdot \mathbf{A}$,
transpozycja iloczynu macierzy przez skalar: $(c \cdot \mathbf{A})^{\top} = c \cdot \mathbf{A}^{\top}$.
Można by twierdzić, że mnożenie macierzy przez skalar jest przemienne: $c \cdot \mathbf{A} = \mathbf{A} \cdot c$, ale nie jest to poprawne stwierdzenie, gdyż zapis $\mathbf{A} \cdot c$ jest nieprawidłowy. Według przyjętej konwencji zapisuje się najpierw skalar, potem macierz, a mówienie o przemienności nie ma sensu, gdyż obydwa czynniki mają całkowicie inną „naturę”, natomiast o przemienności mówimy wyłącznie w kontekście działań o argumentach tego samego typu, czyli należących do tego samego zbioru. Tutaj nie może być mowy o przemienności, gdyż ani liczba nie może zająć miejsca macierzy ani macierz nie może zając miejsca liczby.
Dodawanie macierzy
Dodawanie macierzy jest operacją, która możliwa jest tylko dla macierzy o jednakowych wymiarach. Sumą macierzy $\mathbf{A}$ oraz $\mathbf{B}$, o wymiarze $m \times n$ nazywamy macierz $\mathbf{C}$, której elementy są sumą elementów o takim samym numerze wiersza i kolumny, tj. dla:
posiada element neutralny, którym jest macierz zerowa: $\mathbf {A}_{[m \times n]} + \mathbf {0}_{[m \times n]} = \mathbf {0}_{[m \times n]} + \mathbf {A}_{[m \times n]} = \mathbf {A}_{[m \times n]} \tag {9c} \label {eq:{9c}}$,
rozdzielność względem mnożenia przez skalar: $b \cdot (\mathbf{A} + \mathbf{B}) = b \cdot \mathbf{A} + c \cdot \mathbf{B}$.
Z istnienia elementu neutralnego dodawania macierzy wynika, że dla każdej macierzy $\mathbf{A}$, dowolnego wymiaru, istnieje macierz $-\mathbf{A} = -1 \cdot \mathbf{A}$, taka, że $\mathbf{A} + (-\mathbf{A}) = \mathbf{0}$, gdzie $\mathbf{0}$ jest macierzą zerową takiego samego wymiaru. Oczywiście, wobec przemienności mnożenia macierzy zachodzi również: $-\mathbf{A} + \mathbf{A} = \mathbf{0}$. Taką macierz $-\mathbf{A}$ nazywa się czasem macierzą przeciwną (nie wszystkie podręczniki używają tej terminologii) do macierzy $\mathbf{A}$.
Zauważmy ponadto, że rozdzielność dodawania macierzy względem mnożenia przez skalar jest tożsama z rozdzielnością mnożenia przez skalar względem dodawania macierzy („względność” działa tutaj symetrycznie).
Odejmowanie macierzy
Odejmowanie macierzy można zdefiniować, jako dodawanie macierzy przeciwnej:
Bardzo ciekawą operacją jest mnożenie macierzy. Podobnie, jak dodawanie, czy odejmowanie, mnożenie macierzy, aby było wykonalne, wymaga spełnienia określonych warunków dotyczących wymiarów mnożonych macierzy, jednak warunek ten jest nieco inny i bardziej skomplikowany aniżeli – obowiązujący przy dodawaniu i odejmowaniu – warunek identyczności rozmiarów.
Macierz $\mathbf {A}$ o wymiarach $m \times n$ może być pomnożona przez macierz $\mathbf {B}$ wtedy i tylko wtedy, jeśli ilość kolumn pierwszej macierzy (pierwszego czynnika) będzie taka, jak ilość wierszy drugiej macierzy. Druga macierz musi zatem mieć wymiar $n \times p$. Wynik operacji mnożenia macierzy jest macierzą o ilości wierszy takiej, jak w pierwszej macierzy oraz o ilości kolumn takiej, jak w drugiej macierzy (drugim czynniku). Czyli jest macierzą o wymiarze $m \times p$.
Bardzo często podczas korepetycji uczę moich klientów mnemotechniki: tyle wierszy, ile pierwszy.
Już sam warunek istnienia iloczynu macierzy oraz zasada ustalania jego wymiaru (10) powinny nam zasugerować, że mnożenie macierzy nie jest przemienne.
Jeśli w iloczynie (10) $m \neq p$, to iloczyn „w drugą stronę” nie istnieje. Przykładowo dla macierzy $\mathbf {A}_{[2 \times 3]}$ oraz $\mathbf {B}_{[3 \times 4]}$ iloczyn $\mathbf {A}_{[2 \times 3]} \cdot \mathbf {B}_{[3 \times 4]} = \mathbf {C}_{[2 \times 4]}$ istnieje, natomiast iloczyn iloczyn $\mathbf {B}_{[3 \times 4]} \cdot \mathbf {A}_{[2 \times 3]}$ nie istnieje, gdyż nie zachodzi równość ilości kolumn pierwszym czynniku z ilościami wierszy w drugim czynniku.
Elementy macierzy $\mathbf {C}_{[m \times p]} = \mathbf {A}_{[m \times n]} \cdot \mathbf {B}_{[n \times p]} $ obliczamy ze wzoru:
Wzór (11) bardzo często określa się mianem „mnożenia wiersza przez kolumnę”. W praktyce polega to na mnożeniu przez siebie odpowiadających kolejnych sobie elementów $i$-tego wiersza lewego czynnika przez kolejne elementy $j$-tej kolumny prawego czynnika. Ponieważ warunkiem istnienia iloczynu macierzy jest równość ilości kolumn pierwszego czynnika i ilości wierszy drugiego czynnika, toteż ilość elementów poszczególnych wierszy lewego czynnika jest taka sama, jak ilość elementów w każdej z kolumn drugiego czynnika, toteż zawsze ilość tych elementów będzie taka sama i wyniesie $n$.
Przykład 1
Pokażemy obliczanie iloczynu macierzy na przykładzie macierzy:
Wspólna ilość kolumn macierzy $\mathbf{A}$ oraz wierszy macierzy $\mathbf{B}$ , symbolizowana we wzorze (10) symbolem $n$ wynosi tutaj 3. Macierz wynikowa $\mathbf{C}$ jest macierzą $2 \times 4$:
Każdy z elementów macierzy wynikowej $\mathbf{C}$ obliczamy w taki sposób, że element leżący w $i$-tym wierszu oraz $j$-tej kolumnie tej macierzy, obliczamy mnożąc i-ty wiersz macierzy $\mathbf{A}$ przez j-tą kolumnę macierzy $\mathbf{B}$. Liczymy po kolei:
Obliczenie iloczynu „w drugą stronę” było zatem możliwe, ale wynik jest zupełnie inny – tak dalece inny, że jest macierzą innego wymiaru!
W przypadku macierzy kwadratowych obliczenie obydwu iloczynów będzie możliwe i obydwa będą macierzą tego samego wymiaru i może się zdarzyć, że obydwa iloczyny będa takie same. Najprostszym takim przypadkiem jest sytuacja, że jeden z czynników jest macierzą zerową. Wówczas iloczyn obliczany w „obie strony” będzie macierzą zerową:
Dla macierzy innych niż kwadratowe, również iloczyn dowolnej macierzy $\mathbf{A}_{[m \times n]}$ i macierzy zerowej (odpowiednio dobranej, pod względem wymiaru), będzie macierzą zerową, ale oczywiście w przypadku mnożenia w jedną i drugą stronę, wynikowe macierze zerowe będą miały inne wymiary.
Inny, szczególny przypadek, gdy mnożenie macierzy w jedną i drugą stronę daje taki sam iloczyn, związany jest z istnieniem macierzy odwrotnej. Najpierw jednak przedstawić należy własności mnożenia macierzy. Te własności to:
istnienie elementu neutralnego, którym jest odpowiednio dobrana (pod względem wymiaru) macierz jednostkowa: $\mathbf{A} \cdot \mathbf{I} = \mathbf{A}$ oraz $\mathbf{I} \cdot \mathbf{A} = \mathbf{A}$,
Między innymi z uwagi na tę własność macierzy jednostkowej (czyli bycie elementem neutralnym mnożenia), traktujemy ją, jako macierzowy odpowiednik jedności.
Oprócz tego, dla każdej macierzy kwadratowej $\mathbf{A}$, z wyjątkiem tzw. macierzy osobliwych (zostanie to omówione w artykule poświęconym wyznacznikowi macierzy kwadratowej), można wyznaczyć macierz odwrotną $\mathbf{A}^{-1}$, dla której:
Wyznaczanie macierzy odwrotnej wymaga wyliczenia wyznacznika macierzy, zatem zostanie omówione to w innym artykule.
Sebastian Dziarmaga-Działyński
Funkcje wymierne i ułamki proste
mgr inż.
Sebastian Dziarmaga-Działyński
Wprowadzenie
Funkcja wymierna jest jednym z najważniejszych przykładów funkcji elementarnych, które pojawiają się niemal w każdej dziedzinie matematyki. Stanowi uogólnienie prostych zależności wielomianowych, a jej analiza – zarówno algebraiczna, jak i graficzna – pozwala zrozumieć zachowanie wielu bardziej złożonych modeli.
W praktyce funkcje wymierne opisują zależności, w których wartość zmiennej zależy od stosunku dwóch wielomianów. Ich własności – takie jak dziedzina, miejsca zerowe, asymptoty czy granice funkcji wymiernej – stanowią podstawę do dalszego badania przebiegu zmienności.
Szczególne znaczenie ma również rozkład funkcji wymiernej na ułamki proste, który odgrywa kluczową rolę w rachunku całkowym. Dzięki niemu można łatwo całkować nawet bardzo złożone funkcje wymierne, rozbijając je na prostsze składniki (również będące funkcjami wymiernymi).
W niniejszym artykule przedstawiamy ogólną postać funkcji wymiernej, jej najważniejsze własności oraz zastosowanie rozkładu na ułamki proste — będące wstępem do zagadnień związanych z całkowaniem funkcji wymiernych.
Co to jest funkcja wymierna?
Mianem funkcji wymiernej określamy iloraz dwóch wielomianów:
Licznik jest wielomianem stopnia trzeciego, a mianownik – wielomianem stopnia drugiego. W takiej sytuacji jest możliwość rozłożenia tej funkcji wymiernej na sumę wielomianu stopnia pierwszego oraz funkcji wymiernej właściwej. Spróbujmy dokonać stosownych przekształceń, aby przeprowadzić takie przekształcenie:
Funkcja wymierna może posiadać miejsca zerowe. Miejscami zerowymi funkcji wymiernej (1) są miejsca zerowe wielomianu $P(x)$, o ile oczywiście należą one do dziedziny funkcji wymiernej (tj. nie są one jednocześnie miejscami zerowymi wielomianu $Q(x)$.
W zależności od stopni wielomianów w liczniku i mianowniku, różne są wartości granic $ \lim\limits_{x \to -\infty} W(x)$ oraz $\lim\limits_{x \to \infty} W(x)$.
W przypadku, gdy $m > n$ granice te są granicami niewłaściwymi ($-\infty$ lub $\infty$); znak granicy $ \lim\limits_{x \to \infty} W(x)$ zależy od znaku współczynnika $a_m$, natomiast granicy $ \lim\limits_{x \to -\infty} W(x)$ dodatkowo od tego, czy różnica stopni wielomianów $m - n$ jest liczbą parzystą.
Gdy $m = n$, wówczas $ \lim\limits_{x \to -\infty} W(x) = \lim\limits_{x \to \infty} W(x) = {{a_m} \over {a_n}}$
Gdy $m < n$, wówczas $ \lim\limits_{x \to -\infty} W(x) = \lim\limits_{x \to \infty} W(x) = 0$
Granice w miejscach zerowych mianownika zależą od tego, czy są one również miejscami zerowymi licznika (wówczas granicą może być liczba, w przeciwnym wypadku $-\infty$ lub $\infty$) oraz od znaków wyrażeń licznika i mianownika dla otoczenia liczby, w której liczymy granicę.
Funkcje wymierne mogą posiadać asymptoty:
pionowe $x=a$, jeśli $a$ jest punktem spoza dziedziny funkcji i funkcja posiada w tym punkcie granice niewłaściwą (lewostronna granica niewłaściwa może być różna od prawostronnej),
ukośną, jeśli $0 \leq m - n \leq $, przy czym dla $m=n$ asymptota ukośna jest asymptotą poziomą; funkcja wymierna posiadać może tylko jedną asymptotę ukośną (w $-\infty$ oraz $\infty$).
Ułamki proste
Każdą funkcję wymierną właściwą można przedstawić, jako sumę ułamków prostych. Ułamkami prostymi nazywamy funkcje wymierne właściwe typu:
Przy czym, aby wyrażenie (6) mogło zostać uznane za ułamek prosty, trójmian kwadratowy w jego mianowniku nie może mieć miejsc zerowych, tj.: $\Delta = b^2 - 4c < 0$. W przeciwnym razie wyrażenie to można byłoby rozłożyć na ułamki proste typu (5).
Aby rozłożyć funkcję wymierną właściwą na ułamki proste, należy rozłożyć jej mianownik na czynniki. Każdemu czynnikowi liniowemu jednokrotnemu $(x - a)$ odpowiada ułamek prosty typu:
$$A \over {x - a} \tag 8 \label {eq:8}$$
Każdemu czynnikowi wielokrotnemu $(x - a)^k$ odpowiada suma $k$ ułamków prostych typu (6), dla $1 \leq p \leq k$.
Każdemu czynnikowi jednokrotnemu $(x^2 +bx + c)$, dla którego $\Delta = b^2 - 4c < 0$, odpowiada jeden ułamek prosty, typu
Natomiast każdemu czynnikowi wielokrotnemu $(x^2 + bx + c )^k$ dla którego $\Delta = b^2 - 4c < 0$ odpowiada suma $k$ ułamków prostych typu (7), dla $1 \leq p \leq k$.
Przykład 2
Rozłóżmy na ułamki proste poniższą funkcję – dla ułatwienia, mianownik jest już rozłożony na czynniki:
należy tylko obliczyć wartości współczynników $A$, $B$, $C$.
W tym celu mnożymy obie strony wyrażenia (11) przez mianownik funkcji (10) po lewej stronie.
$$x^2 - 3x + 5 \equiv A \cdot (x + 1) + B \cdot (x + 1)(x - 2) + C \cdot (x - 2)^2 \tag {12} \label {eq:{12}}$$
Znak $\equiv$ oznacza tożsamość wyrażeń po lewej i prawej stronie, która zachodzi dla każdej wartości $x$ – w tym nawet takiej, dla której funkcja (10) nie istnieje (tj. $x=-1$, $x = 2$). Aby obliczyć wartości współczynników $A$, $B$, $C$ należy podstawić do wyrażenia (12) trzy różne wartości $x$. Mogą to być całkiem dowolne wartości, ale obliczeniowo najkorzystniej jest w pierwszej kolejności użyć wartości, dla których mianownik funkcji (10) równy jest zero.
Weźmy $x = -1$. Zeruje się wówczas wyrażenie $x + 1$. Równość (12) przybiera postać:
$$(-1)^2 - 3 \cdot (-1) + 5 = C \cdot (-1 -2)^2$$
$9 = 9C$ stąd $C = 1$
Następnie bierzemy $x = 2$, Zeruje się wówczas wyrażenie $x - 2$:
$$2^2 - 3 \cdot 2 + 5 = A \cdot (2 + 1)$$
$3 = 3A$ stąd $A = 1$
Mając wartości $A$ oraz $B$ za $x$ możemy podstawić dowolną wartość. Najlepiej podstawić $x = 0$:
$$0^2 - 3 \cdot 0 + 5 = A \cdot (0 + 1) + B \cdot (0 + 1)(0 - 2) + C \cdot (0 - 2)^2$$
$5 = A - 2B + 4C$ stąd $5 = 1 - 2B + 4$ stąd $B=0$
Wobec tego rozkład funkcji (10) na ułamki proste jest następujący:
W pierwszej kolejności powinniśmy zauważyć pewien „haczyk”. Licznik funkcji wymiernej (14) jest wielomianem trzeciego stopnia, a mianownik tej funkcji również jest wielomianem stopnia trzeciego, gdyż jest on iloczynem wielomianu stopnia drugiego oraz pierwszego. Wynika stąd, że funkcja (14) jest funkcją wymierną niewłaściwą, tymczasem rozkład na ułamki zwykłe dotyczy tylko funkcji wymiernych właściwych. W pierwszej kolejności zatem, musimy rozłożyć tę funkcję na sumę wielomianu i funkcji wymiernej właściwej. Ponieważ licznik i mianownik są tego samego stopnia, rozkład ten można wykonać nieco szybciej i prościej, aniżeli w przykładzie nr 1.
W tym celu przedstawmy „na siłę” licznik wyrażenia (14), jako identyczny z mianownikiem, a następnie, poprzez odejmowanie stosownych składników, przywróćmy go do pierwotnej postaci. Najpierw wymnóżmy mianownik:
Funkcję wymierną niewłaściwą (14) przedstawiliśmy w postaci (15), tj. sumy jedności (czyli wielomianu stopnia zerowego) oraz funkcji wymiernej właściwej . Teraz funkcję tę możemy już, bez problemu, rozłożyć na ułamki proste.
Sprawdźmy – na wszelki wypadek – czy trójmian kwadratowy $x^2 - 2x + 4$ rzeczywiście jest nierozkładalny na czynniki – czyli, czy nie posiada on pierwiastków rzeczywistych. Obliczamy $\Delta = (-2)^2 - 4 \cdot 4 = -12<0$ Wszystko się zgadza, zatem rozkład na ułamki proste będzie następujący:
Tutaj również mamy do wyliczenia trzy wartości: $A$, $B$, $C$. Można tego dokonać poprzez podstawienie trzech różnych wartości $x$. Tutaj będzie nieco trudniej, gdyż mianownik funkcji (15) miał tylko jedno rzeczywiste miejsce zerowe. Zatem nie uda się, tak jak to się udało w poprzednim przykładzie, podstawić dwu wartości „zerujących” wszystkie czynniki oprócz jednego.
Oczywiście, jeśli ktoś lubi wyzwania, to mógłby rozłożyć nierozkładalny trójmian kwadratowy w mianowniku, wyliczając pierwiastki zespolone, jednakże sposób taki – pomimo możliwości podstawienia za $x$ zespolonych miejsc zerowych mianownika – niekoniecznie byłby obliczeniowo łatwiejszy.
Cel rozkładu na ułamki proste
W wielu zastosowaniach, łatwiej używać zwyczajnej, ilorazowej postaci funkcji wymiernej (2), co najwyżej warto rozłożyć mianownik a czasem także i licznik na czynniki. Jednak jest kilka zagadnień, gdzie rozłożenie na ułamki proste jest konieczne. Jednym z nich jest rachunek całkowy. Otóż dla każdej funkcji wymiernej da się wyznaczyć funkcję pierwotną (czyli obliczyć całkę nieoznaczoną, bądź oznaczoną metodą Newtona-Leibnitza), jednak obliczenie całki nieoznaczonej wymaga rozkładu na ułamki proste. Każdy typ ułamka prostego ma swój algorytm postępowania, pozwalający na wyznaczenie całki nieoznaczonej, a całka funkcji wymiernej jest sumą tych całek.
Innymi obszarami, gdzie rozkład na ułamki proste znajduje zastosowanie, są: transformacja Laplace’a oraz odwrotna transformacja Laplace’a.
Całkowaniu funkcji wymiernych oraz transformacji Laplace’a poświęcone będą odrębne artykuły.
Sebastian Dziarmaga-Działyński
Aproksymacja i interpolacja
mgr inż.
Sebastian Dziarmaga-Działyński
Wprowadzenie
Aproksymacja oraz interpolacja, to dwa bardzo ważne zagadnienia przerabiane w ramach kursu metod numerycznych. Nazwy wzbudzają u niektórych strach i niezrozumienie, a także są często mylone. Czy słusznie? W tym artykule postaram się przybliżyć te dwa zagadnienia.
Interpolacja
Interpolacja liniowa i przykład „życiowy”
Zaczniemy od interpolacji, jako od zagadnienia prostszego, a nawet bliższego codziennemu życiu. Czym zajmuje się interpolacja? Do czego służy?
Zacznijmy może od problemu życiowego. Załóżmy, że chcemy naszemu kotu, czy psu zaaplikować środek na pchły, czy kleszcze. Na ulotce mamy tabelkę z ilością preparatu, jaka powinna zostać zaaplikowana w zależności od wagi zwierzęcia. Załóżmy, że tabelka ta wygląda tak:
Waga zwierzęcia [kg] $$x_i$$
Ilość preparatu [ml] $$y_i$$
3
11
5
16
7
21
10
25
Oczywiście dane są całkowicie zmyślone. Ważymy naszego pupila – waga pokazuje 5,8 kg. Ile mililitrów preparatu zaaplikować? Czy potraktować to, jako 5 kg i zaaplikować 16 ml, a może już jako 7 kg i zaaplikować 21 ml? Co, jeśli 16 ml okaże się za mało i nie pokonamy robactwa a 21 ml to za dużo i zaszkodzimy pupilowi?
Co w takiej sytuacji zazwyczaj robimy? Waga 5,8 kg to waga pośrednia pomiędzy zawartymi w tabeli wartościami 5 kg i 7 kg, więc poszukujemy jakiejś pośredniej wartości mililitrów. Staramy się to robić zgodnie z jakąś logiką i kombinujemy tak:
Przy 5 kg dawka to 16 ml, przy wadze o 2 kg większej, dawka to 21 ml. A zatem tak, jakby w zakresie między 5 a 7 kg masy zwierzęcia, na 2 kg wagi przypadało 5 ml. Nasz pupil waży o 0,8 kg więcej, czyli jakby powinien dostać dawkę 16 ml powiększoną o część z tych 5 ml i to proporcjonalnie taką część, z tych 5ml, jaką częścią 2 kg jest nasze 0,8 kg.
Innymi słowy powinien dostać 16 ml + 0,8/2*5 ml, co daje nam 2 ml. Czyli optymalna dawka leku dla naszego zwierzaka, to 18 ml.
Brawo! Dokonaliśmy właśnie najprostszej interpolacji – interpolacji liniowej. Założyliśmy sobie, że pomiędzy sąsiednimi wartościami masy ciała w tabeli (5 kg oraz 7 kg), dawka leku od 16 ml do 21 ml zmienia się liniowo. To, co zrobiliśmy, na rysunku można przedstawić następująco.
Interpolacja liniowa
Interpolacja liniowa pomiędzy dwoma punktami
Interpolacja wielomianowa
W przytoczonym przypadku, interpolację dokonaliśmy de facto na dwu punktach (5; 16) oraz (7; 21). Pozostałe punkty z tabeli w ogóle nas nie interesowały. Zrobiliśmy to po to, by poznać wartość zmiennej $y$ (dawki lekarstwa dla zwierzaka), dla wartości $x$ (masy jego ciała), która nie została wymieniona w tabeli.
Na zajęciach z metod numerycznych najczęściej interpolacji dokonuje się na większej ilości punktów. Mamy kilka punktów $(x_i; y_i)$ i chcemy poznać wartości $y$ dla $x$ niewymienionego w tabeli. W tym celu szukamy takiej funkcji która – to bardzo ważne, kluczowe dla interpolacji i odróżniające ją od aproksymacji – dla danych wartości $x_i$ da dokładnie takie same wartości $y_i$ i, niejako przy okazji, pozwoli na wspomniane wyliczenie $y$ dla wartości pośrednich.
Funkcją, która pod względem matematycznym dobrze nadaje się do spełnienia warunku idealnego dopasowania swych wartości do danych punktów, jest funkcja wielomianowa. Dla przypomnienia, wielomianem (stopnia $n$) nazywamy taką funkcję:
$a_0, a_1, ..., a_n$ są to współczynniki wielomianu. Interpolacja liniowa, o której mówiliśmy na początku, polegała na znalezieniu prostej przechodzącej przez dwa punkty. Matematycznie prostą, reprezentuje równanie prostej:
$$y = ax + b$$
poznane bodajże jeszcze w szkole podstawowej, które jest niczym innym, jak właśnie wielomianem. Wielomianem pierwszego stopnia, gdyż zmienna $x$ występuje tam w potędze pierwszej. W naszym przypadku nie wyznaczaliśmy tego równania prostej w sposób jawny, ale gdybyśmy chcieli, to jest to jak najbardziej możliwe. Póki co nie angażujmy do tego sposobów przerabianych na studiach, ale użyjmy wiedzy z poziomu szkoły średniej. Mamy dane dwa punkty (5; 16) oraz (7; 21). Korzystamy ze wzoru (zawartego w każdych tablicach „maturalnych”):
Oczywiście nasz wielomian nie da wartości $y$ z tabelki dla innych $x$ z tej tabelki, bo oczywiście uwzględniliśmy tylko te dwa punkty.
Co by było, gdybyśmy chcieli, aby nasz wielomian „zgadzał się” dla wszystkich punktów z tabelki – a są one cztery? Zastanówmy się przede wszystkim, wielomianu jakiego stopnia poszukujemy. Zachodzi tutaj prosta zależność – jeśli mamy $n$ punktów, to potrzebujemy wielomianu stopnia $n-1$. No bo tak, jeśli są dwa punkty, to jak wiemy, można przez nie poprowadzić prostą (czyli wielomian stopnia 1). Jeśli mielibyśmy trzy punkty, to przez trzy punkty można jednoznacznie poprowadzić parabolę (wielomian stopnia drugiego). Z kolei wielomian stopnia zerowego, czyli funkcję stałą (jej wykres to prosta pozioma) można poprowadzić przez jeden punkt. I tak dalej.
Uwaga – w tym momencie trzeba zwrócić uwagę na bardzo ważną rzecz. Aby interpolacja była możliwa, dane punkty muszą odpowiadać funkcji, czyli jednej wartości zmiennej $x$ może odpowiadać tylko jedna wartość $y$. Gdybyśmy mieli np. punkty (3; 5) oraz (3; 6) to nie dałoby się dokonać interpolacji. Nadal dałoby się przez takie punkty poprowadzić prostą, ale byłaby to prosta pionowa, o równaniu $x = 3$, a takie równanie nie jest równaniem funkcji liniowej. Nic nie stoi natomiast na przeszkodzie, aby ten sam $y$ odpowiadał różnym wartościom $x$. Dla punktów (2; 4), (3; 5), (4; 4) bez problemu można znaleźć wielomian interpolacyjny.
U nas zatem, skoro mamy cztery punkty, potrzebujemy wielomianu stopnia trzeciego. Czyli takiej funkcji:
$$W_3(x) = a_0 + a_1 x + a_2 x^2 + a_3 x^3$$
Tak naprawdę, to właściwsze byłoby stwierdzenie, że potrzebujemy wielomianu stopnia co najwyżej trzeciego. Bo wyobraźmy sobie, że np. te cztery punkty akurat leżą na jednej prostej – wtedy wystarczyłoby równanie prostej. Matematyka sobie z taką sytuacją poradzi w taki sposób, że po prostu współczynniki $a_2$ oraz $a_3$ wyszłyby równe zero.
Spróbujmy wyznaczyć sobie ten wielomian interpolacyjny nie korzystając ze wzorów przerabianych na kursie metod numerycznych. Jak wiadomo, kluczowe dla interpolacji jest, by „dla podanych iksów wychodziły podane igreki”. Innymi słowy, uwzględniając punkty z naszej tabeli, muszą być spełnione warunki: $W_3(3) = 11$, $W_3(5) = 16$, $W_3(7) = 21$, $W_3(10) = 25$. Podstawiając te zależności do wzoru (1) dostaniemy układ równań:
w którym niewiadomymi są współczynniki $a_0$, $a_1$, $a_2$, $a_3$. I o to chodzi! Będą współczynniki, będziemy mieć wielomian. Współczynniki są cztery, równania też cztery. Jest więc szansa na rozwiązanie.
Jako, że tematem artykułu nie jest rozwiązywanie układów równań liniowych, przeto nie będziemy dokładnie opisywać metodyki rozwiązania układu – ograniczymy się tylko do wzoru na wektor niewiadomych:
Na poniższym wykresie zaprezentowano przebieg wyliczonego wielomianu interpolacyjnego.
Interpolacja wielomianowa
Interpolacja wielomianem stopnia trzeciego
Jak widać, w zakresie wartości zmiennej $x$ pomiędzy najmniejszą a największą wartością z tabeli, nie można mieć do naszego wielomianu większych zastrzeżeń. Łatwo policzyć, że dla zakładanej wstępnie wartości 5,8 kg, nasz wielomian osiąga wartość (wynik zaokrąglono):
$$W_3(5,8) = 18,09$$
otrzymano więc wartość nieznacznie wyższą od uzyskanej poprzednio.
Jak widać na wykresie, poza zakresem zmienności zmiennej $x$ z danych, wykres zupełnie się „rozjeżdża” i bez jakiejkolwiek logiki, pomimo wcześniejszego wzrostu, natychmiast po przekroczeniu przez $x$ wartości 10, wartość funkcji gwałtownie spada… Nieco inaczej będzie to wyglądało w przypadku aproksymacji, ale o tym powiemy w dalszej części.
Interpolacja Lagrange’a
W ramach kursu badań operacyjnych zazwyczaj nie wyznacza się współczynników wielomianu interpolacyjnego poprzez rozwiązanie układu równań liniowych. Najczęściej korzysta się z wielomianów interpolacyjnych Lagrange’a oraz Newtona.
Wielomian interpolacyjny Lagrange’a wylicza się ze wzoru:
We wzorze tym licznik sumy $i=0,1,2,...,n$ odpowiada kolejnym punktom interpolacyjnym – punktów tych jest $n+1$ (numerujemy od zera!) a wielomian jest stopnia $n$, co zgodne jest z poprzednią konkluzją, że stopień wielomianu interpolacyjnego jest o 1 niższy od ilości punktów.
Budowa wzoru jest prosta – ilość składników sumy równa jest ilości punktów interpolacyjnych. W liczniku od zmiennej $x$ odejmujemy wartości współrzędnej $x$ kolejnych punktów pomijając wartość współrzędnej $x$ punktu odpowiadającemu liczonemu składnikowi. Mianownik ma taką samą budowę, jak licznik, tyle, że w miejscu zmiennej $x$ znajduje się pominięta współrzędna.
W naszym przypadku ze wzoru skorzystamy w sposób następujący:
Wzór działa według prostej koncepcji. Dla danego punktu interpolacyjnego $x_i$ wyrażenia $x - x_i$ przy wszystkich pozostałych punktach (w liczniku) równe są zero a z kolei dla tego punktu licznik równy jest mianownikowi (ułamek staje się jedynką), dzięki czemu w prosty sposób osiąga się warunek $W_n(x_i) = y_i$.
Po wymnożeniu liczb oraz wyrażeń we wzorze (3) oraz zredukowaniu wyrażeń podobnych, otrzymujemy wielomian określony wzorem (2). Jest to normalne, gdyż może istnieć tylko jeden wielomian interpolacyjnystopnia co najwyżej $n$ dla danego zestawu punktów.
Oczywiście można wykonać owe przekształcenia i doprowadzić wielomian do postaci ogólnej i często wymagają tego prowadzący zajęcia, ale generalnie idea wzoru Lagrange’a polega na tym, aby właśnie tego nie robić, tylko bez kłopotliwych przekształceń od razu skonstruować działający wielomian interpolacyjny.
Wielomian interpolacyjny Lagrange’a to nie jest nazwa jakiegoś specjalnego rodzaju wielomianu. To tylko nazwa sprytnego zapisu działającego wielomianu interpolacyjnego, bez wyznaczania jego współczynników. Gdybyśmy np. chcieli w jakimś języku programowania zapisać taki działający wielomian, to spokojnie wystarczyłoby zdefiniować funkcję wg wzoru (3). Oczywiście postać (2) jest ładniejsza i pewnie szybsza dla kompilatora/interpretera/parsera, ale obie postaci są matematycznie równoważne.
W zasadzie, moim zdaniem, nie powinno się mówić wielomian interpolacyjny Lagrange’a tylko wzór interpolacyjny Lagrange’a.
Interpolacja Newtona
Tutaj również mówi się o wielomianie interpolacyjnym Newtona, choć de facto jest to po prostu wzór na jeden i ten sam wielomian interpolacyjny. Skonstruowany według nieco innych zasad. Sam wzór posiada dość skomplikowany zapis, więc pokażemy od razu sposób konstrukcji wielomianu.
Skonstruowanie wielomianu według wzoru interpolacyjnego Newtona wymaga wyliczenia ilorazów różnicowych funkcji. Jeśli ktoś uważał na zajęciach z analizy matematycznej, to powinien pamiętać to pojęcie. Występuje ono przy definiowaniu pochodnej funkcji. Jest ona definiowana, jako granica ilorazu różnicowego, dla przyrostu funkcji dążącego do zera.
Jeśli mamy dwa punkty $x_0$ oraz $x_1$, gdzie $x_0 < x_1$ pomiędzy którymi funkcja nasza jest ciągła, to ilorazem różnicowymfunkcji nazywamy stosunek zmiany wartości funkcji do przyrostu jej argumentu, tj.:
Pojęcie ilorazu różnicowego można rozszerzyć na iloraz różnicowy wyższych rzędów. Iloraz różnicowy drugiego rzędu jest to po prostu iloraz różnicowy z ilorazu różnicowego pierwszego rzędu. Czyli mamy trzy punkty $x_0, x_1, x_2$, obliczamy ilorazy różnicowe między $x_0$ a $x_1$ oraz między $x_1$ a $x_2$ i dla tych ilorazów różnicowych obliczamy ilorazy różnicowe, czyli:
Analogicznie wyprowadza się ilorazy różnicowe kolejnych rzędów.
Kolejne ilorazy obliczamy w tabeli:
$i$
$x_i$
$y_i=f(x_i)$
$ {{\Delta f(x_0, x_1)} \over {\Delta x}}$
$ {{\Delta f(x_0, x_1)} \over {\Delta x}}$
${{\Delta^3 f(x_0, x_1,x_2)} \over {\Delta x^3}}$
1
3
11
—
—
—
2,5
—
2
5
16
0
2,5
$-{1 \over 30}$
3
7
21
$-{7 \over 30}$
$4 \over 3$
—
4
10
25
—
—
—
Czy ta $-{1 \over 30}$ coś Wam przypomina?
Teraz, to co najfajniejsze, to współczynniki we wzorze interpolacyjnym Newtona czytamy tak jakby „po trójkącie” i mamy dwie możliwości: po górnym, lub dolnym trójkącie. Najpierw wypiszemy wzór a potem będzie komentarz:
Wartość 2,5 przedstawiono, jako $5 \over 2$, aby nie mieszać różnych postaci ułamka w jednym wzorze, a 0 zapisano, by było wiadomo, jak wzór powstał. Po jego wyeliminowaniu wzór przybiera postać:
Zauważamy ten schemat? Wzór jakby narasta wraz z kolejnym składnikiem o wyrażenie $x-x_i$, gdzie $x_i$ jest współrzędną $x$ kolejnego punktu: licząc od początku, jeśli wybieramy górny trójkąt, albo od końca, jeśli wybieramy dolny.
Czytelnicy ze smykałką do programowania od razu zauważą, że wartości takiego wielomianu świetnie oblicza się w pętli, wykorzystując namnażanie przyrostowe – w Pascalu byłoby to:
iloczyn := iloczyn*(x - x[i])
czy też w C prościej:
iloczyn *= x - x[i];
Oczywiście wzory (6) oraz (7) po przekształceniu doprowadzą do wielomianu (2), co Czytelnik sprawdzić może samodzielnie. Z tego też powodu zarówno w postaci (6), jak i (7), występuje ten sam współczynnik $-{1 \over 30}$. Jak już bowiem powiedziano, wielomian interpolacyjny Newtona nie jest żadnym innym, specjalnego rodzaju wielomianem, ale jest to po prostu wzór interpolacyjny na wyznaczenie wielomianu interpolacyjnego bez de facto wyznaczania jego współczynników w postaci ogólnej (1).
Wzór interpolacyjny Newtona posiada także swoją specjalną wersję, przeznaczoną dla argumentów równoodległych. U nas nie miałby on zastosowania, gdyż pierwsze trzy punkty są wprawdzie równoodległe (3; 5; 7) – różnica między nimi wynosi 2 (tworzą więc ciąg arytmetyczny), ale kolejny punkt ma współrzędną $x$ równą 10 i z tego ciągu się wyłamuje. W tym artykule nie będziemy jednak omawiać tego wzoru – być może poświęcimy mu odrębny artykuł.
Istnieje wiele metod interpolacji i związanych z interpolacją, jak interpolacja funkcjami giętkimi (splajnami), interpolacja Hermite’a czy wybór węzłów interpolacyjnych w oparciu o wzór Czebyszewa. Również zasługują na inny, obszerny artykuł.
Aproksymacja
O co chodzi w aproksymacji?
Głównym tematem niniejszego artykułu nie jest szczegółowe omawianie zagadnień interpolacji czy aproksymacji, ale przede wszystkim uzmysłowienie podstawowej różnicy między tymi metodami.
W odróżnieniu bowiem od interpolacji, dla której najważniejszą kwestią było, aby wyznaczyć taką funkcję, która pozwoli dla zadanych współrzędnych $x_i$ otrzymać dokładne wartości $y_i$ – czyli (dla „wzrokowców”) aby otrzymać taką krzywą, która przejdzie przez wszystkie punkty, aproksymacja szuka takiej krzywej, która jak najlepiej dopasuje się do ułożenia tychże punktów niekoniecznie przez nie przechodząc.
Jak zauważyliśmy na wykresie sporządzonym dla danych z naszej tabeli, punkty układały się „mniej więcej” wzdłuż linii prostej – co jest logiczne, bo im więcej waży zwierzę, tym więcej preparatu należy mu zaaplikować. Wielomian interpolacyjny świetnie się do tych punktów dopasował, ale poza obszarem objętym interpolacją, zupełnie z owym spodziewanym liniowym wzrostem się rozjechał.
Aproksymacja tutaj, jak za chwilę zobaczymy, okaże się znacznie lepszym narzędziem. Polega ona bowiem na wyznaczeniu takiej funkcji aproksymującej $A(x)$, że łączna, szeroko pojęta, różnica (odległość) pomiędzy wartościami funkcji aproksymującej a aproksymowanej (czyli naszymi punktami $y_i$) będzie jak najmniejsza:
$$\sum_{i=0}^n d \left( f(x_i), A(x_i) \right) \rightarrow \min$$
Owa różnica, czy też odległość może być bardzo różnie zdefiniowana. Nie może być to po prostu różnica: $d \left( f(x_i), A(x_i) \right) = f(x_i) - A(x_i)$ gdyż wówczas nawet bardzo duże odległości ujemne znosiłyby się (kompensowały) z odległościami dodatnimi i dopasowanie wyszłoby fatalne. Już całkiem niegłupia byłaby wartość bezwzględna: $d \left( f(x_i), A(x_i) \right) = |f(x_i) - A(x_i)$|, ale ona z kolei jest funkcją „ciężką” obliczeniowo, choćby dlatego, że jej wykresem jest litera v (co oznacza, że nie jest różniczkowalna w zerze)1.
Aproksymacja średniokwadratowa
Znacznie lepszą odległością jest kwadrat różnicy: $d \left( f(x_i), A(x_i) \right) = \left( f(x_i) - A(x_i) \right)^2$. Przyjęcie takiej funkcji prowadzi do najpopularniejszego wariantu aproksymacji, czyli aproksymacji średniokwadratowej. W aproksymacji tej funkcję $A(x)$ dopasowujemy w taki sposób, aby:
O co chodzi z funkcją kary? Otóż możemy sobie zdecydować, że nie wszystkie punkty są jednakowo ważne. Dokładniejsze dopasowanie do pewnych punktów uznać możemy za znacznie ważniejsze niż dopasowanie do innych. Aby to osiągnąć, po prostu tym ważniejszym punktom przypisujemy wyższa wartość funkcji kary niż tym mniej ważnym i aparat matematyczny metody, o którym wkrótce napiszemy, minimalizując wyrażenie (9) zadba o to, by uczynić zadość naszym preferencjom.
Póki co jednak, dla uproszczenia, załóżmy, że nie uwzględniamy funkcji kary, czyli przyjmujemy $w(x_i) = 1$, a zatem wszystkie punkty są dla nas jednakowo ważne. Jak wyznaczyć funkcję $A(x)$?
Aby wyznaczyć funkcję aproksymującą $A(x)$, należy w pierwszej kolejności ustalić postać tej funkcji. W przypadku aproksymacji zakładaną postać funkcji aproksymującej definiuje się w oparciu o tzw. funkcje bazowe. Definicja taka wygląda następująco:
gdzie $\varphi_j(x)$ są przyjętymi funkcjami bazowymi, natomiast $a_j$ to poszukiwane wartości współczynników.
Wygląda to groźnie, ale w praktyce jest znacznie łatwiejsze. Przypuśćmy, że chcemy przyjąć $A(x)$ jako funkcję liniową (czyli wielomian stopnia pierwszego), tj:
$$A(x) = a_0 + a_1 x \tag {11} \label {eq:{11}}$$
wówczas, porównując wyrażenia (10) oraz (11) zauważamy, że funkcjami bazowymi będą: $\varphi_0 (x) = 1$ oraz $\varphi_1 (x) = x$. Możemy przyjmować najróżniejsze postaci funkcji bazowych. Wybór uzasadniony powinien być albo układem punktów empirycznych, a najlepiej powinien być uzasadniony merytorycznie. Przykładowo jeśli punkty empiryczne są np. wynikami pomiaru wydłużenia próbki materiału pod wpływem działającej siły, spodziewamy się zależności liniowej i taką też funkcję dobieramy. Jeśli jest to np. pomiar temperatury stygnącego obiektu, dokonywany w określonych odstępach czasu, wówczas należałoby dobrać funkcję wykładniczą, itd.
W przypadku danych przedstawionych w naszej wyjściowej tabeli, wydaje się, że najwłaściwszą funkcją będzie właśnie funkcja liniowa.
Współczynniki $a_0, a_1, ..., a_m$ funkcji aproksymującej oblicza się najczęściej wzorami macierzowymi.
$\mathbf F$ jest macierzą wartości funkcji bazowych dla naszych punktów empirycznych, natomiast wektor $\boldsymbol y$ jest wektorem współrzędnych $y$ naszych punktów.
Wektor $\boldsymbol a$ współczynników funkcji aproksymującej $A(x)$ obliczamy ze wzoru:
Jeśli ktoś zetknął się kiedyś z ekonometrią, wzór (12) może wydawać mu się dziwnie znajomy. Skojarzenie jest jak najbardziej trafne! Aproksymacja średniokwadratowa i estymacja parametrów równania regresji wielorakiej metodą najmniejszych kwadratów, to – z matematycznego punktu widzenia – praktycznie jedno i to samo. Różnice są przede wszystkim natury merytorycznej. Przy aproksymacji nie analizuje się właściwości reszt (błędów aproksymacji) pod kątem stałości wariancji czy autokorelacji. Wyznaczonych wartości współczynników funkcji aproksymującej $A(x)$ nie traktuje się jak estymatory, gdyż nie traktujemy punktów empirycznych jako próby losowej.
Regresja wieloraka kładzie większy nacisk na zależność przyczynowo-skutkową pomiędzy zmienną zależną a zmiennymi objaśniającymi a w aproksymacji liczy się przede wszystkim dopasowanie matematyczne. W regresji wielorakiej kolumny macierzy $\mathbf F$, zwanej tam zazwyczaj macierzą $\mathbf X$ są wartościami kolejnych zmiennych objaśniających, podczas gdy w aproksymacji są to wartości funkcji bazowych wyliczone dla tego samego zestawu współrzędnych $x$. Można powiedzieć, że aproksymacja to taka regresja wieloraka, w której zmiennymi objaśniającymi są funkcje bazowe. Jak powiedziano, w zastosowaniach praktycznych czasem jednak się zdarza, że dobór poszczególnych funkcji bazowej wynika z przesłanek merytorycznych.
Wyliczmy zatem postać liniowej funkcji aproksymującej średniokwadratowo dane z naszej tabeli. Funkcje bazowe, jak wspomniano, mieć będą postać $\varphi_0 (x) = 1$ oraz $\varphi_1 (x) = x$. Nasze macierze równe będą:
Dopasowanie wyznaczonej linii pokazuje poniższy wykres:
Aproksymacja średniokwadratowa
Aproksymacja średniokwadratowa funkcją liniową
Tym razem, poza zakresem zmienności zmiennej $x$, funkcja nie zmienia tendencji, co jest oczywiste w przypadku funkcji liniowej.
Obliczmy wartość funkcji aproksymującej dla $x = 5,8$:
$$A(5,8) = 5,692 + 2,009 \cdot 5,8 = 17,34$$
Wartość ta nieco niższa niż otrzymana w wyniku interpolacji liniowej przeprowadzonej między punktami $(5; 16)$ oraz $(7; 21)$. Na wyraźnie widać przyczynę takiego stanu rzeczy. Odcinek łączący wskazane punkty znajduje się powyżej wykresu wyznaczonej funkcji aproksymującej.
Dla porównania wyliczmy wartość funkcji aproksymującej w postaci wielomianu drugiego stopnia. Funkcje bazowe mają w tym wypadku postać: $\varphi_0(x) = 1$, $\varphi_1(x) = x$, $\varphi_2(x) = x^2$.
Wykres dopasowania obu funkcji pokazano na poniższym rysunku.
Aproksymacja średniokwadratowa
Aproksymacja średniokwadratowa wielomianem stopnia drugiego
Widać tu podobną „słabość”, jak w przypadku interpolacji. Wielomian drugiego stopnia świetnie dopasowuje się do punktów empirycznych, niemalże przez nie przechodząc (wyliczone wartości funkcji aproksymującej wynoszą $A(3) = 10,87$, $A(5) = 16,36$, $A(7) = 20,70$, $A(10) = 25,06$ czyli są bardzo zbliżone do wartości $y_0 = 11$, $y_1 = 16$, $y_2 = 21$, $y_3 = 25$.
Aproksymacja – interpolacją
Ale do najciekawszych konkluzji dochodzimy, gdy próbujemy znaleźć funkcję aproksymującą w postaci wielomianu trzeciego stopnia. Funkcjami bazowymi będą $\varphi_0(x) = 1$, $\varphi_1(x) = x$, $\varphi_2(x) = x^2$, $\varphi_3(x) = x^3$.
Gdzieś taką macierz już chyba widzieliśmy… Tak! Jest to przecież macierz współczynników z zadania interpolacji wielomianowej! Dochodzimy tu bowiem do najważniejszego odkrycia. Otóż w pewnej szczególnej sytuacji, a mianowicie: gdy ilość wyznaczanych parametrów funkcji aproksymującej równa jest ilości punktów empirycznych, wtedy aproksymacja staje się interpolacją.
To niesamowite. Przekonywaliśmy, że to dwa odrębne zagadnienia, że się różnią, a jednak. Jednak posiadają one pewien „wspólny mianownik” w postaci tego, że czasem po prostu aproksymacja staje się interpolacją. Dlaczego tak? Zarówno funkcja interpolująca, jak i aproksymująca posiadają parametry – tutaj, były nimi współczynnik wielomianu. Działają one, jak pokrętła sterujące. Zmieniając wartości poszczególnych współczynników można, coraz bardziej dopasować funkcję do przebiegu punktów empirycznych, tak samo, jakbyśmy kręcili pokrętłami skomplikowanej maszyny.
Gdy pokręteł jest mniej niż punktów, zazwyczaj nie damy rady idealnie dopasować do wszystkich punktów. Kręcąc dwoma pokrętłami, gdy punkty są cztery, zawsze coś poprawiając, gdzie indziej coś zepsujemy. Mamy wówczas aproksymację – dopasowanie jak najlepsze, ale nieidealne.
Gdy jednak ilość pokręteł jest równa ilości punktów można sobie wyobrazić, że jednym pokrętłem dopasowujemy do jednego punktu, innym do innego – dając w ten sposób radę dopasować do wszystkich. Mamy interpolację.To oczywiście spore uproszczenie, ale dobrze oddaje matematyczny sens opisywanej sytuacji.
Z drugiej strony idealność dopasowania nie jest celem samym w sobie, bo najczęściej płacimy za nią całkowicie bezsensownym przebiegiem funkcji poza oknem interpolacji. Można powiedzieć, że aproksymacja, starając się kilkoma tylko parametrami dopasować do wielu punktów, robi coś uniwersalnego – dopasowanie na tyle dobre, że jeśli punktów dołożymy, to nadal efekt jej działania będzie miał sens. Interpolacja natomiast kreuje „fachowca od jednej śrubki”. Funkcję, która tak koncentruje się na dokładnym dopasowaniu do wszystkiego, co jest, że zupełnie się kompromituje, gdy coś nowego przybędzie.
Omawiając interpolację zaznaczyliśmy, że interpolować możemy tylko wówczas, gdy wśród punktów empirycznych nie ma dwu (lub więcej) takich, które maja jednakową wartość współrzędnej $x$ a różne wartości zmiennej $y$. Aproksymacji to w żaden sposób nie przeszkadza, o ile nie jest to ten przypadek, gdy aproksymacja przeszła w interpolację.
Inne aproksymacje
Warto na zakończenie zasygnalizować, że korzystając z odpowiednich przekształceń, można aproksymować najróżniejszymi funkcjami. Przykładowo można zastosować potęgową funkcje aproksymującą:
Jeśli teraz podstawimy $B(x) = \ln A(x)$, $z = \ln x$, $b_0 = \ln a_0$, $b_1 = a_1$, otrzymamy:
$$B(z) = b_0 + b_z \cdot z$$
czyli najzwyklejszą aproksymację funkcją liniową. Po wyznaczeniu wartości parametrów $b_0$ oraz $b_1$ dokonujemy zwrotnego podstawienia $a_0 = e^{b_0}$, $a_1 = b_1$ i w ten sposób mamy wyznaczoną postać (13).
Innym ciekawym zagadnieniem związanym z aproksymacją, jest aproksymacja ciągła. Dotychczas omawiana aproksymacja byłą aproksymacją dyskretną, polegającą na jak najlepszym dopasowaniu funkcji aproksymującej do pewnej skończonej ilości punktów empirycznych. W aproksymacji ciągłej dopasowujemy funkcję nie do punktów a do innej ciągłej funkcji. Czyli łączna odległość liczona jest nie od skończonej ilości punktów, ale od całego kontinuum punktów tamtej funkcji. Ciągłym odpowiednikiem sumy jest całka, zatem odpowiednikami wzorów (8) i (9) dla interpolacji ciągłej na przedziale $\left \langle a, b \right \rangle$. są:
W ten sposób uogólnić można oczywiście tylko aproksymację. Ciągła wersja interpolacji nie miałaby sensu, gdyż po prostu funkcją interpolującą musiałaby być ta sama funkcja, co funkcja interpolowana – przynajmniej na wskazanym przedziale.
Niektórzy twierdzą, że wartość bezwzględna nie jest funkcją elementarną. Oczywiście powinni oni jak najszybciej wrócić do szkoły, albo zapisać się na nasze korepetycje, bo przecież $|x| = \sqrt {x^2}$, czyli jest jak najbardziej funkcją elementarną. ↩︎
Sebastian Dziarmaga-Działyński
Różne oblicza odchylenia standardowego i wariancji
Sebastian Dziarmaga-Działyński
Wprowadzenie
Każdy nowy Klient korzystający z moich korepetycji ze statystyki (zresztą podobnie w przypadku innych przedmiotów), proszony jest o pokazanie notatek, prezentacji z uczelni bądź – jako wariant minimum – karty wzorów. Jak wiadomo, uczelnie a także poszczególni prowadzący zajęcia i wykłady, różnią się pod względem zakresu przerabianego materiału, przyjętej konwencji oznaczeń a także wzorów na konkretne miary statystyczne. Jedną z ważniejszych i bardzo istotnych różnic jest rozumienie pojęcia odchylenia standardowego i wzory stosowane do obliczenia tej miary.
Czym jest odchylenie standardowe
Odchylenie standardowe, to najpowszechniejsza klasyczna miara rozrzutu danych. Klasyczna, dlatego, że w wyliczeniu odchylenia standardowego biorą udział wszystkie dane w szeregu, a nie tylko niektóre, jak ma to miejsce w przypadku miar pozycyjnych. Rozrzutu, zwanego także zróżnicowaniem bądź dyspersją dlatego, że mierzy ono, jak bardzo poszczególne wartości cechy w badanej zbiorowości różnią się między sobą.
Jeżeli mamy $n$-elementową zbiorowość, daną szeregiem szczegółowym: $X=\{x_1, x_2,...,x_n \}$, to odchylenie standardowe, oznaczane najczęściej symbolem $s$ wyraża się wzorem:
W dalszej części niniejszego artykułu wariancja pojawiać się będzie bardzo często, być może nawet nieco częściej niż odchylenie standardowe. Wynika to ze ścisłego związku tych miar, a obliczenie odchylenia standardowego zawsze wymaga – jawnego bądź niejawnego – obliczenia wariancji, stąd wszelkie niemal uwagi tyczą się obydwu tych miar.
Jak widać, obliczenie wariancji oraz odchylenia standardowego wymaga w pierwszej kolejności obliczenia średniej arytmetycznej:
$$\bar x = {1 \over n} \cdot \sum_{i=1}^n x_i$$
Ponieważ bardzo często średnia ma część ułamkową, każdorazowe obliczanie odchyłki od średniej $x_i - \bar x$ może być żmudne (gdy musimy obliczenia prowadzić „ręcznie”) i prowadzić do kumulowania błędów zaokrągleń, często stosuje się równoważny wzór na wariancję, pozbawiony tej niedogodności:
W tym przypadku do kwadratu podnosimy same wartości zmiennej $x$, a kwadrat średniej odejmujemy tylko raz, na samym końcu. Wadą z kolei tego sposobu jest to, że otrzymujemy dość wysokie liczby, gdyż podnosimy bezpośrednio nasze dane, a nie ich odchyłki od średniej. Generalnie więc wybór wariantu wzoru podyktowany jest tylko wygodą obliczającego, gdyż oba warianty wzoru dają jednakowe wyniki a ewentualne drobne różnice wyniknąć mogą tylko i wyłącznie z błędów zaokrągleń. Jeśli średnia arytmetyczna wyraża się liczbą całkowitą, wybieramy wariant (2), a jeśli jest to jakiś „skomplikowany”, okresowy ułamek – wówczas optymalnym wyborem staje się (3).
Nie na tym jednak polega największy problem z odchyleniem standardowym i wariancją, jako pojęciami obecnymi w kursie statystyki na najróżniejszych kierunkach wyższych uczelni.
Próbka a populacja
Źródłem największej ilości nieporozumień oraz niezrozumienia (i to niezrozumienia po obu stronach wykładowej auli) jest to, że w statystycznym „obiegu”, równolegle do wariancji (a tym samym i odchylenia standardowego, jako pierwiastka kwadratowego z wariancji) określonej wzorami (2) oraz (3) funkcjonuje jeszcze tak zwana wariancja próbkowa, często oznaczana jako ${\hat s}^2$, wyliczana ze wzoru:
Jak widać różni się ona od omówionej wcześniej wariancji występowaniem w mianowniku $n-1$ w miejsce $n$. Wariancja ta bywa czasem oznaczana ${\hat \sigma }^2$, choć bardzo często bywa również oznaczana przez $s^2$ zwłaszcza przez tych prowadzących, którzy w ogóle „nie uznają” wariancji wyliczonej ze wzorów (2) oraz (3).
Oczywiście pierwiastek z wariancji próbkowej to odchylenie standardowe próbkowe, oznaczane odpowiednio przez $\hat s$, $\hat \sigma$ lub czasem, niestety, po prostu przez $s$.
Dla wariancji próbkowej również istnieje alternatywny wzór, przydatny wówczas, gdy średnia arytmetyczna z danych jest ułamkowa. Wówczas można wariancję próbkową obliczyć ze wzoru:
Można także, oczywiście, przeliczać między jedną a drugą wariancją, korzystając z zależności:
$${\hat s}^2 = {n \over {n-1}} \cdot s^2$$
Oczywiście, jak łatwo wywnioskować ze wzorów, wariancja próbkowa ${\hat s}^2$ zawsze jest nieco wyższa od wariancji $s^2$ (zwanej często, dla odróżnienia wariancją populacyjną) i różnica ta jest tym mniejsza, im większa jest liczebność zbioru danych $n$, co jest oczywiste.
Po co to wszystko? Dlaczego dwie różne wariancje?
Otóż prawidłowy wybór określonego rodzaju wariancji zależy od tego, w jaki sposób traktujemy badaną zbiorowość statystyczną. Jeśli nasz zbiór danych jest kompletną populacją, czyli badamy wszystkie jednostki, wówczas jedynym słusznym wyborem jest wariancja „populacyjna”, określona wzorami (2) oraz (3) i ewentualnie odchylenie standardowe „populacyjne” jako pierwiastek z tej wariancji.
A zatem jeśli chcemy wyliczyć odchylenie standardowe np wzrostu wszystkich studentów w naszej grupie, to wszystkich ich mierzymy i obliczając wariancję korzystamy wyłącznie ze wzoru (2) lub (3). Obliczenie wariancji próbkowej będzie w takim wypadku błędem (choć niektórzy nauczyciele akademiccy, niestety, są innego zdania).
Jeśli jednak badana zbiorowość statystyczna jest tylko próbką, wybraną w sposób losowy z jakiejś większej zbiorowości i chcemy nie tyle obliczyć wariancję w naszej próbce, co oszacować (estymować) wariancję w całej populacji, wówczas właściwym wyborem jest wariancja próbkowa, do wyliczenia której stosujemy wzór (4) lub (5) i pierwiastek z tej wariancji wyliczamy, jako odchylenie standardowe.
Jeśli więc, chcąc oszacować odchylenie standardowe masy ciała wszystkich dorosłych mieszkańców miasta dysponujemy masą ciała np. pięćdziesięciu w reprezentatywny (najlepiej losowo) wybrany sposób takich mieszkańców, to wyliczymy wariancję próbkową i pierwiastek z niej będzie owym poszukiwanym oszacowaniem.
Ważna uwaga. Jak wynika z postaci przytoczonych wyżej wzorów, do wyliczenia wariancji (czy to „populacyjnej”, czy też próbkowej) potrzebna jest średnia arytmetyczna. W przypadku szacowania wariancji na podstawie próbki, ową średnią arytmetyczną traktujemy, jako oszacowanie przeciętnej wartości zmiennej w populacji (czyli oszacowanie tzw. wartości oczekiwanej tej zmiennej). Gdybyśmy jednak, w jakiś cudowny sposób znali tę przeciętną wartość – nie oszacowaną, ale dokładną (oznaczmy ją przez $\mu$) to wówczas, wariancję próbkową policzylibyśmy ze wzoru:
A zatem, pomimo iż nadal jest to wariancja próbkowa, mamy nie $n-1$ a po prostu $n$. Dlaczego tak się dzieje? Wyjaśnienie jest proste.
Załóżmy, że nic nie wiemy o przeciętnej wadze mieszkańców jakiejś odległej planety. Wysłana sonda kosmiczna zważyła losowo wybranego jednego mieszkańca tej planety. Powiedzmy, że ważył on 150 kg. Co możemy na podstawie tej próbki oszacować? Czy możemy oszacować przeciętną masę ciała, a może jej rozrzut?
Jeśli chodzi o przeciętną masę ciała, jak najbardziej możemy ją oszacować, obliczając po prostu średnią arytmetyczną z próby. Ponieważ $n=1$, toteż średnia równa jest po prostu wartości jedynej danej, jaką dysponujemy i wynosi ona $\bar x = 150$. Oczywiście mogliśmy mieć niefart i „trafił” nam się akurat jakiś nietypowy mieszkaniec planety, ale dzięki tak nawet szczątkowej informacji można sformułować twierdzenie, że tamtejsi kosmici są nieco ciężsi od ludzi, ale nie są to raczej ani krasnoludki ani dinozaury. Czy jednak możemy cokolwiek powiedzieć o zróżnicowaniu masy ciała kosmitów na tamtejszej planecie? Nie! Nie jesteśmy w stanie powiedzieć o niej absolutnie nic. Skąd mamy wiedzieć, czy są oni pod względem masy bardziej, czy mniej zróżnicowani, skoro mamy tylko masę ciała jednego osobnika?
Obliczenie wariancji „populacyjnej” nic nam nie da, gdyż dla $n=1$ wariancja wyjdzie zawsze zero – tak samo, jak dla szeregu składającego się z $n$ takich samych wartości. Wariancji próbkowej natomiast nie policzymy, z uwagi na $n-1$ w mianowniku – w naszym przypadku w mianowniku tym znalazłoby się zero. Już rozumiemy, skąd owo $n-1$ w „próbkowych” wariantach wzorów, prawda?
Sytuacja diametralnie się zmieni, gdy będziemy dysponowali masa ciała dwóch osobników zamiast jednego. Wtedy policzymy wariancję próbkową i pierwiastek z niej. Ale nie tylko wtedy. Rozrzut masy ciała wspomnianych kosmitów na podstawie jednoelementowej próbki oszacujemy także wówczas, gdybyśmy jakimś „cudem” posiadali informację o przeciętnej masie ciała w całej populacji. Gdybyśmy wiedzieli np., że ta wartość oczekiwana masy wynosi 150 kg i nasz jedyny zważony osobnik również waży 150 kg, to już mielibyśmy wystarczająca informację, by spodziewać się bardzo niewielkiego zróżnicowania masy ciała, nie wykluczając opcji, że wszyscy, jak jeden mąż, ważą 150 kg.
Gdyby z naszych informacji wynikało, że przeciętna masa wynosi 200 kg, to również mielibyśmy jakąś tam orientację przynajmniej o rzędzie wielkości różnic masy analizowanych kosmitów. No to już chyba jasne, skąd we wzorach (6) oraz (7) wzięło się $n$?
Odchylenie standardowe we wnioskowaniu statystycznym
Nieporozumienia związane z omówionymi dwoma rodzajami odchylenia standardowego pojawiają się także bardzo często przy okazji kursu statystyki matematycznej. Choć w teorii estymacji bardziej właściwą miarą jest próbkowe odchylenie standardowe, to jego populacyjny odpowiednik również się tam pojawia.
W zagadnieniach związanych z estymacją średniej (wartości oczekiwanej) oraz weryfikacji hipotez dotyczących wartości oczekiwanej, niezbędne jest obliczenie standardowego błędu estymacji średniej. Jest on niezbędny zarówno do wyznaczenia krańców przedziału ufności dla wartości oczekiwanej, jak tez i do wyznaczenia statystyki testowej w teście istotności dotyczącym wartości oczekiwanej. Standardowy błąd estymacji średniej oznacza, o ile średnio estymator wartości oczekiwanej w populacji (czyli średnia arytmetyczna) różni się od rzeczywistej, nieznanej wartości oczekiwanej w populacji generalnej.
W stosunkowo rzadkim przypadku, gdy znamy odchylenie standardowe w populacji generalnej (tzw. „model I”), standardowy błąd estymacji średniej wyraża się wzorem:
W pozostałych jednak – znacznie bardziej realistycznych – przypadkach, gdy odchylenie standardowe w populacji generalnej pozostaje nieznane, standardowy błąd estymacji średniej wylicza się za pomocą wzoru:
Jak więc wynika z porównania wzorów (9) oraz (10), w zależności od tego, jaki rodzaj odchylenia standardowego wyliczono z próby, w mianowniku wzoru na standardowy błąd estymacji średniej pojawia się albo $\sqrt{n-1}$ albo $\sqrt n$.
Najprościej zapamiętać sobie, że obowiązuje zasada „obu pierwiastków”, czyli $\sqrt{n-1}$ oraz $\sqrt n$. Albowiem, jeśli do wyliczenia standardowego błędu estymacji średniej użyto „populacyjnego” odchylenia standardowego, które zawiera już w sobie pierwiastek z $n$, to w mianowniku pojawi się pierwiastek z $n-1$. I na odwrót, jeśli użyjemy próbkowego odchylenia standardowego, które ma w swojej formule zawarty pierwiastek z $n-1$, to we wzorze na standardowy błąd estymacji pojawić się musi pierwiastek z $n$. Innymi słowy, podstawiając do wzoru (9) wzór (2) albo też do wzoru (10) wzór (4), dostaniemy finalnie:
$$S \left( \bar x \right) = \sqrt{{\sum_{i=1}^n \left(x_i - \bar x \right)^2} \over {n \cdot (n -1)}} \tag {11} \label{eq:11}$$
Wszystko jest jasne i oczywiste, jeśli mamy dane wartości i sami z nich wyliczamy średnią oraz odchylenie standardowe. Wówczas to do nas należy decyzja, czy liczymy odchylenie standardowe „populacyjne”, czy próbkowe i którego wariantu wzoru finalnie użyjemy. Problem pojawia się wówczas, gdy – jak to ma miejsce na większości kolokwiów czy egzaminów – wyznaczyć musimy przedział ufności bądź zweryfikować hipotezę w oparciu o miary już wyliczone. Czyli mamy zadanie typu:
Producent śrubek chce sprawdzić, czy produkowane śrubki spełniają normy (…) w wyniku losowo pobranej próby 50 śrubek otrzymano średnią arytmetyczną równą 5,03 mm i odchylenie standardowe 0,05 mm (…).
Niestety w zadaniu tego typu trzeba zgadywać, jakie odchylenie standardowe jego autor miał na myśli. W praktyce korepetytorskiej, najczęściej przeglądam notatki, karty wzorów, bądź szukam podobnych zadań w prezentacjach. Pewien trop daje także liczebność próby. Zazwyczaj zadania są tak dobrane, by „łatwo się liczyło”. Skoro trzeba wyciągać pierwiastek, to bardzo często jest tak, że pierwiastek ten jest liczbą całkowitą. Jeśli więc w zadaniu z estymacji bądź hipotez mamy liczebność próby będącą pełnym kwadratem (9; 16; 25, itd), to skłaniam się ku twierdzeniu, że „anonimowe” odchylenie standardowe, o którym mowa w treści zadania, to odchylenie próbkowe, bowiem wówczas korzystamy ze wzoru (10) i wyciągamy pierwiastek z $n$. Natomiast jeśli w zadaniu mamy kwadrat powiększony o 1, czyli $n$ wynosi 10; 17; 26; 37, czy tak, jak w naszym przypadku 50, to oznacza, że mamy wyciągać pierwiastek z $n-1$, czyli wymieniając bezimienne odchylenie standardowe w treści zadania, autor miał na myśli odchylenie „populacyjne”, a zatem obliczając standardowy błąd estymacji średniej korzystać będziemy ze wzoru (9).
Tego typu śledztwo nie wyjaśnia wszystkich wątpliwości, gdyż prowadzący bardzo często „mieszają” wzory – np. w zadaniach z niewielką liczebnością próby (korzystających z rozkładu Studenta) domyślnie zakładają próbkowe odchylenie standardowe ale już w przypadku dużej liczebności (gdy aproksymujemy rozkładem normalnym) zakładają wersję „populacyjną”. Niektórzy robią też dokładnie na odwrót. Jednak jest to temat na inny artykuł.
Obliczenia w Excelu
W arkuszu kalkulacyjnym Microsoft Excel korzystać można z obu rodzajów wariancji oraz odchylenia standardowego. Warto jednak mieć na uwadze, że w polskiej wersji tego programu, standardowe nazwy formuł:
WARIANCJA()
ODCH.STANDARDOWE()
dotyczą wariancji próbkowej oraz próbkowego odchylenia standardowego (czyli tych z $n-1$ w mianowniku). Dodatkowo, na chwilę obecną (2025 rok), formuły te mają status depreciated , co oznacza, że Microsoft nie zaleca ich stosowania, gdyż mogą one w nowszych wersjach zostać wycofane i wykorzystujące takie formuły pliki mogą się w tych przyszłych wersjach już nie otwierać.
Zamiast owych wycofywanych formuł, do wyliczenia wariancji próbkowej oraz próbkowego odchylenia standardowego, Microsoft rekomenduje formuły:
WARIANCJA.PRÓBKI()
ODCH.STANDARD.PRÓBKI()
Z kolei do obliczenia „populacyjnych” wersji obu miar, dotychczas służyły formuły:
WARIANCJA.POPUL()
ODCH.STANDARD.POPUL()
Obie mają współcześnie status depreciated, toteż zamiast nich, Microsoft rekomenduje stosowanie formuł:
WARIANCJA.POP()
ODCH.STAND.POPUL()
Dodatkowo nowsze (a więc te niebędące depreciated) formuły posiadają także warianty:
WARIANCJA.PRÓBKI.A() , ODCH.STANDARDOWE.A()
dla próbki, oraz
WARIANCJA.POPUL.A() , ODCH.STANDARD.POPUL.A()
dla populacji, w sposób niestandardowy traktujące tekst oraz wartości logiczne PRAWDA i FAŁSZ. Podstawowe warianty formuł bowiem ignorują wartości tekstowe i logiczne (traktują zawierające je komórki tak, jak gdyby były one puste). Natomiast warianty z .A na końcu traktują wartości tekstowe oraz FAŁSZ, jak zera, natomiast wartości logiczne PRAWDA traktują, jak liczbę 1.
Sebastian Dziarmaga-Działyński
Metoda graficzna
mgr inż.
Sebastian Dziarmaga-Działyński
Wprowadzenie
Metoda graficzna to najbardziej podstawowa metoda rozwiązywania zadań programowania liniowego, od której student zaczyna swoją „przygodę” przedmiotem badania operacyjne.
W tym artykule przedstawię najważniejsze cechy tej metody, istotne „tricki” ułatwiające rozwiązywanie zadań, a także pewne niestandardowe sytuacje, jakie mogą wystąpić podczas rozwiązywania zadań metodą graficzną.
Na czym polega metoda graficzna
Metoda graficzna służy do rozwiązywania zadań programowania liniowego, w których występują dwie zmienne decyzyjne. W pewnych szczególnych sytuacjach, można jej użyć także do rozwiązania zadań z większą ilością zmiennych decyzyjnych. Metoda ta polega na sporządzeniu wykresu na kartezjańskim układzie współrzędnych $x_1$, $x_2$, w którym nanosi się obszar dopuszczalny zadania oraz (najlepiej) również izokwanty (poziomice) funkcji celu. Dzięki unaocznieniu na wykresie elementów zadania, wyznaczenie rozwiązania staje się proste.
Przykładowe zadanie
Każde zadanie programowania liniowego składa się z czterech następujących elementów:
zmienne decyzyjne,
funkcja celu,
warunki ograniczające,
warunki brzegowe.
Załóżmy, że w naszym zadaniu mamy funkcję celu: $f(\textbf x) = 2 x_1 + 4 x_2 \rightarrow \max$
Dla klasycznych warunków brzegowych: $x_1 \geq 0$, $x_2\geq 0$.
Zaczynamy od narysowania obszaru. Poszczególne nierówności rysujemy w taki sposób, że rysujemy najpierw prostą, odpowiadająca równaniu a następnie zaznaczamy, po której stronie prostej występuje obszar. Z uwagi na warunki brzegowe, rysunek ograniczony zostanie do pierwszej ćwiartki układu współrzędnych.
Weźmy pierwszą nierówność: $x_1 + x_2 \leq 12$. Rysujemy najpierw prostą $x_1 + x_2 = 12$. Aby narysować prostą (a w zasadzie reprezentujący ją odcinek), wyznaczamy dwa punkty, przez które prosta ta przechodzi. Aby narysowanie prostej za pomocą długopisu i linijki było łatwiejsze, punkty te powinny: po pierwsze, być od siebie odpowiednio oddalone, a po drugie, najlepiej, by miały takie współrzędne, aby przy przyjętej skali rysunku, wyrażały się one całkowitą ilością jednostek lub kratek. Dobrze też, gdy współrzędne obydwu punktów wyrażać się będą nieujemnymi wartościami współrzędnych, gdyż i tak obszar leży w pierwszej ćwiartce. Naturalnie, jeśli narysowanie prostej będzie przez to łatwiejsze, można wyznaczyć taką parę współrzędnych, w których jedna z nich (lub nawet obie) będzie wyrażać się niewielką liczbą ujemną (np. -1).
Jeśli, tak jak w powyższym przypadku, obie współrzędne są sumowane, najprościej przyjąć punkty, leżące na osiach układu współrzędnych – czyli wyznaczyć taką wartość jednej zmiennej, dla której równość będzie spełniona, a jedna ze współrzędnych równa będzie zero. W naszym przypadku takie współrzędne to $(0; 12)$ oraz $(12; 0)$.
Następnie musimy ustalić, z której strony narysowanej prostej znajduje się obszar dopuszczalny. W tym celu należy pamiętać o prostej zasadzie:
Następnie patrzymy na znak nierówności oraz znak współczynnika przy danej współrzędnej. Jeśli znak współczynnika jest dodatni, wówczas położenie obszaru względem prostej jest niejako „intuicyjnie zgodne” z kierunkiem owej nierówności. Czyli przy znaku $\leq$ obszar znajduje się na lewo od prostej (jeśli współczynnik przy $x_1$ jest dodatni) oraz poniżej prostej (jeśli współczynnik przy $x_2$ jest dodatni). Przy znaku $\geq$ obszar ten znajduje się odpowiednio na prawo oraz powyżej prostej.
Ujemny współczynnik odwraca tę „intuicyjną zgodność”. Ujemny współczynnik przy zmiennej $x_1$ sprawia, że znak $\leq$ oznacza, iż obszar znajduje się na prawo od prostej a $\geq$ – na lewo. Analogicznie ujemny współczynnik przy zmiennej $x_2$ sprawia, że przy znaku $\leq$ obszar jest powyżej, a przy znaku $\geq$ – poniżej prostej.
Jako, że w pierwszej nierówności ograniczającej $x_1 + x_2 \leq 12$ współczynniki przy obu zmiennych są dodatnie, to wobec znaku $\leq$ obszar dopuszczalny znajduje się na lewo oraz poniżej narysowanej prostej, co warto zaznaczyć na rysunku małą strzałeczką”.
Metoda graficzna
Ograniczenie x₁ + x₂ ≤ 12
Ograniczenie naniesione na wykres
Analogicznie nanosimy kolejną nierówność ograniczającą: $3x_1 + 2x_2 \geq 6$. Najpierw rysujemy prostą $3x_1 + 2x_2 = 6$. Najłatwiejszymi punktami do wyznaczenia są $(0; 3)$ oraz $(2; 0)$. Przy obydwu zmiennych współczynniki są dodatnie, zatem wobec znaku $\geq$ obszar dopuszczalny znajduje się na prawo oraz powyżej tej prostej.
Ostatnią z nierówności ograniczających jest $2x_1 - 4x_2 \geq 8$. Rysujemy prostą $2x_1 - 4x_2 = 8$. W tym wypadku pierwszy punkt wyznaczyć można analogicznie do poprzednich, jak $(4; 0)$, ale chcąc znaleźć punkt przecięcia z osią $Ox_2$ należałoby wziąć punkt $(0; -2)$. Wzięcie takiego punktu nie jest błędem, ale należałoby przedłużyć oś odciętych $Ox_2$ poniżej osi rzędnych. Zamiast tego można dobrać inny punkt spełniający równanie prostej – np. może to być punkt $(6; 1)$.
Przy zmiennej $x_1$ współczynnik jest dodatni (wynosi 2), ale przy zmiennej $x_2$ jest on ujemny (wynosi -4). Zatem wobec znaku nierówności $\geq$ obszar znajduje się na prawo od narysowanej prostej (zgodnie z „intuicją”) ale jednocześnie poniżej tej prostej (czyli przeciwnie niż mówi „intuicja”).
Finalnie, obszar dopuszczalny wygląda następująco:
Metoda graficzna
Naniesione wszystkie ograniczenia
Obszar dopuszczalny zadania
Sporządzenie obszaru dopuszczalnego to najważniejsza część zadania. Często, w ramach kursu badań operacyjnych, studenci nie uczą się rysowania niczego więcej, albowiem sensownym jest poszukiwanie rozwiązania optymalnego wyłącznie wśród wierzchołków tego obszaru.
W niniejszym artykule zostanie jednak pokazany łatwiejszy sposób wyznaczania rozwiązania optymalnego: w oparciu o izokwantę funkcji celu oraz jej gradient.
Jeśli jednak chcielibyśmy poszukiwać rozwiązania optymalnego wyłącznie wśród wierzchołków, to musimy znać ich współrzędne. O ile współrzędne wierzchołków stanowiących podstawę naszego trójkąta znamy, gdyż używaliśmy ich przecież do rysowania prostych – są to punkty $(4; 0)$ oraz $(12; 0)$ – nazwijmy je odpowiednio punktami $A$ oraz $B$: $A = (4; 0)$ $B=(12; 0)$, o tyle trzeci punkt musi być znaleziony analitycznie, jako punkt przecięcia się „zielonej” prostej $x_1 + x_2 = 12$ oraz „brązowej” prostej $2x_1 - 4x_2 = 8$. Współrzędne te znajdujemy rozwiązując układ równań:
Dysponując tylko współrzędnymi punktów wierzchołkowych, rozwiązanie optymalne zadania znaleźć można obliczając wartości funkcji celu we wszystkich punktach wierzchołkowych i wybierając najlepszą z nich, z punktu widzenia kierunku optymalizacji. W naszym przypadku funkcja celu jest maksymalizowana, stąd wybieramy wartość największą.
Tutaj widzimy już słabość takiej metody rozwiązywania zadania, gdyż w naszym prostym zadaniu są tylko trzy punkty wierzchołkowe, ale w ogólności punktów tych może być znacznie więcej. Ale skoro są trzy, to obliczmy:
Jednak rozwiązywanie zadania można sobie znacząco ułatwić, nanosząc na obszar dopuszczalny izokwantę funkcji celu oraz kierunek, w którym przesuwa się ona wraz ze wzrostem wartości tej funkcji.
W pierwszej kolejności warto narysować przykładową izokwantę (zwaną także poziomicą lub warstwicą) funkcji celu, przechodząca przez nasz obszar dopuszczalny. Najlepiej, by przechodziła ona „w miarę” przez środek tego obszaru. Jak tego dokonać?
Wybierzmy sobie jakiś punkt leżący wewnątrz tego obszaru – niech będzie to, przykładowo, punkt $(9; 1)$. Jak narysować taka izokwantę? Mamy dwie możliwości. Pierwsza możliwość polega na obliczeniu wartości funkcji celu w tym punkcie: $f(9; 1) = 2 \cdot 9 + 4 \cdot 1 = 18 + 4 = 22$ i następnie rysujemy prostą $f(x_1, x_2) = 22$, tj. prostą $2x_1 + 4x_2 = 22$ dokładnie w taki sam sposób, jak robimy to w przypadku prostych ograniczających. Punkt $(9; 1)$ już mamy – sami go sobie obraliśmy, no to bierzemy jakiś jeszcze jeden – w miarę oddalony, by rysunek wykonać precyzyjnie. Może to być punkt $(11; 0)$ a jeszcze lepszym (bo bardziej oddalonym) może być np. punkt $(1; 5)$.
Znacznie jednak lepszą metodą jest metoda oparta o gradient funkcji celu. Po narysowaniu jednej izokwanty bowiem nadal nie wiemy, w która stronę ona się przesuwa, gdy wartość funkcji celu wzrasta. Musielibyśmy narysować jeszcze jedną izokwantę, w innym punkcie i dopiero wówczas posiadalibyśmy taką wiedzę. Gradient jednak wskaże nam to o wiele szybciej.
Gradient funkcji celu jest to wektor o składowych równych współczynnikom przy zmiennych decyzyjnych w funkcji celu. W naszym przypadku jest to wektor $\nabla f = \vec u = [2 ; 4]$. Traktujemy go jak wektor swobodny, który „zaczepić” możemy w dowolnym punkcie naszego wykresu – najlepiej, by był to obrany punkt $(9; 1)$ – i uwaga – wcale nie musimy rysować najpierw izokwanty! Wręcz przeciwnie – lepiej zacząć właśnie od gradientu! Wektor to „strzałka” mająca początek i koniec (z „grotem”). Początek rysujemy w wybranym punkcie $(9; 1)$, koniec zaś w punkcie przesuniętym względem tego punktu o 2 jednostki w poziomie i 4 jednostki w pionie. Gradient wskazuje nam, w którą stronę izokwanta, która do naszego gradientu jest zawsze prostopadła, przesuwa się wraz ze wzrostem wartości funkcji celu.
Wiedząc o prostopadłości gradientu i izokwanty, tę ostatnią można narysować właśnie już po narysowaniu gradientu. I – uwaga – nie będzie tu potrzebna ekierka. Skoro początek naszego wektora jest w punkcie $(9; 1)$ i wektor ma składowe $[2; 4]$ – czyli „przesuwa” o dwie jednostki w prawo i cztery w górę, to aby „ładnie” narysować prostopadłą do niego izokwantę, wystarczy narysować dwa jej punkty – jeden przesunięty o (uwaga!) cztery jednostki w prawo i dwie w dół (czyli będzie to punkt $(13; -1)$) a drugi przesunięty względem punktu $(9;1)$ na odwrót, tj. o cztery jednostki w lewo i dwie jednostki w górę (tj. będzie to punkt $(5; 3)$.
Wykorzystujemy tutaj fakt, że aby otrzymać wektor prostopadły do danego, należy zamienić jego składowe i przed jedną z nich zmienić znak na przeciwny. Tj. wektorami prostopadłymi (ortogonalnymi) do $[2; 4]$ są wektory $[4; -2]$ oraz $[-4; 2]$.
Metoda graficzna
Obszar dopuszczalny, izokwanty oraz gradient funkcji celu
Obszar dopuszczalny, izokwanty oraz gradient funkcji celu
Mając narysowaną zarówno izokwantę, jak i gradient, bez trudu ustalamy, że punktem optymalnym jest punkt $C$, gdyż jest to ostatni punkt obszaru dopuszczalnego, przez który obszar ten opuści, przesuwająca się w kierunku wskazanym przez gradient, izokwanta funkcji celu.
Gdybyśmy szukali minimum funkcji celu, wówczas punktem optymalnym byłby punkt $A=(4; 0)$, gdyż z kolei jest to ostatni punkt obszaru, przez który opuści go izokwanta przesuwająca się w kierunku przeciwnym do wskazanego przez gradient.
Dla ustalenia rozwiązania optymalnego metodą opartą o gradient funkcji celu konieczne jest sporządzenie jak najprecyzyjniejszego rysunku, gdyż czasem nachylenie krawędzi obszaru jest bardzo podobne do nachylenia izokwanty i może być trudno ustalić, który dokładnie punkt jest tym „ostatnim”. Może się zresztą zdarzyć, że nachylenie tej krawędzi będzie identyczne i wówczas rozwiązaniem optymalnym nie będzie jeden konkretny punkt, ale wszystkie punkty należące do odcinka (rozwiązanie optymalne niejednoznaczne).
Oczywiście w razie wątpliwości zawsze można policzyć wartości funkcji celu w „wątpliwych” wierzchołkach – jeśli będą się różnić, to optymalnym punktem będzie ten, dający „lepszą” (z punktu widzenia kryterium optymalizacji) wartość. Wartości jednakowe oznaczać będą, że optymalny jest cały odcinek.
Metoda graficzna
Przykład zadania z optymalnym całym brzegiem obszaru dopuszczalnego
Zadanie z optymalnym całym brzegiem obszaru dopuszczalnego.
Na powyższym rysunku mamy taką właśnie sytuację. Jest to zadanie o takim samym obszarze dopuszczalnym, jak wcześniej, ale o innej funkcji celu:
$g(\textbf x) = x_1 + x_2 \rightarrow \max$
Widzimy, że izokwanta nie opuści obszaru przez punkt $C$, ale przez cały odcinek $BC$. Rozwiązaniami optymalnymi są wszystkie punkty tego odcinka, a zatem zarówno punkt $B=(12;0)$ jak i $C = \left( {28 \over 3}; {8 \over 3} \right)$ ale także wszystkie punkty leżące na odcinku $BC$, pomiędzy jego końcami. Jak zapisać takie rozwiązanie? Otóż jedną ze zmiennych w rozwiązaniu wypisujemy podając zakres jej zmian w postaci dwustronnej nierówności, a drugą podajemy w postaci liniowej zależności od tej pierwszej (zauważmy, że obydwa te punkty leżą na prostej $x_1 + x_2 = 12$).
Stosując metodę gradientową możemy spotkać się z sytuacją, że wartości współczynników funkcji celu będą zupełnie innych rzędów wielkości aniżeli współrzędne punktów obszaru ograniczającego. Co wówczas? Otóż w przypadku gradientu znaczenie mają jedynie jego kierunek oraz zwrot. Nie jest istotna jego długość. Co za tym idzie, zamiast rysować wprost gradient, można narysować dowolną dodatnią jego wielokrotność (mniejszą lub większą). Jeśli zatem przy naszym obszarze dopuszczalnym, funkcja celu byłaby postaci: $h(\textbf x) = 3000x_1 + 2000x_2 \rightarrow \max$ to nie musimy rysować wektora $[3000; 2000]$. Możemy obie jego współrzędne podzielić przez 1000 (czyli pomnożyć przez skalar 0,001), otrzymując łatwy do narysowania wektor $[3;2]$. Ważne, by obie współrzędne były pomnożone przez tę samą liczbę (w przeciwnym razie zmianie ulegnie kierunek) i by liczba ta była dodatnia (w przeciwnym wypadku zmieni się zwrot).
Czym metoda graficzna może nas zaskoczyć?
Rozwiązując zadania metodą graficzną można natknąć się na przypadki szczególne. Najłatwiejszy z nich, to obszar dopuszczalny będący zbiorem pustym. Weźmy zadanie o następującym układzie ograniczeń:
Przykład zadania sprzecznego – obszar dopuszczalny jest zbiorem pustym
Zadanie sprzeczne – obszar dopuszczalny jest zbiorem pustym.
W takim wypadku oczywiście mamy $D=\emptyset$ co oznacza, że rozważane zadanie programowania liniowego jest zadaniem sprzecznym, a zatem nie posiada rozwiązania optymalnego, gdyż aby istniało rozwiązanie optymalne zadania programowania liniowego, musi ono posiadać jakiekolwiek rozwiązania dopuszczalne. Dopiero spośród nich może się bowiem „rekrutować” rozwiązanie optymalne. Jeśli rozwiązań dopuszczalnych brak, to i rozwiązanie optymalne istnieć nie może.
Czasem jednak spotkać się możemy z innym przypadkiem, gdzie również nie ma rozwiązania optymalnego, ale z zupełnie innego powodu. Weźmy następujące zadanie programowania liniowego:
Dla klasycznych warunków brzegowych: $x_1 \geq 0$, $x_2\geq 0$.
Sporządzamy wykres obszaru dopuszczalnego i nanosimy gradient wraz z przykładową izokwantą.
Metoda graficzna
Przykład zadania nieposiadającego skończonego rozwiązania optymalnego
Zadanie nie posiada skończonego rozwiązania optymalnego.
Obszar dopuszczalny, jak widać, nie jest bynajmniej pusty, jednakże przy zadanej funkcji celu rozwiązania optymalnego nie da się wyznaczyć. Ale nie dlatego, że nie istnieje ono w ogóle, lecz dlatego, że nie jest ono skończone. Izokwanta może przesuwać się w kierunku wskazanym przez gradient, nie napotykając na jakikolwiek opór. Wszystko jednak zależy od funkcji celu. Jeśli bowiem – pozostawiając ten sam obszar dopuszczalny – funkcję celu zmienimy na:
$g(\textbf x) = -2 x_1 + 3 x_2 \rightarrow \max$
wówczas sytuacja pokazana na rysunku zmieni się na:
Metoda graficzna
Przykład zadania z obszarem dopuszczalnym, jak na rys. 6, posiadającego rozwiązanie optymalne
Obszar dopuszczalny, jak na rys. 6 – zadanie posiada rozwiązanie optymalne.
i rozwiązaniem optymalnym będzie punkt przecięcia „brązowej” i „niebieskiej” prostej. Łatwo to rozwiązanie znaleźć, wynosi ono:
Jak wspomniano, metody graficznej używamy wówczas, gdy w zadaniu występują dwie zmienne decyzyjne. Jednak w niektórych przypadkach metoda graficzna okazuje się przydatna także, przy większej ich ilości.
Z pierwszym tego typu przypadkiem mamy do czynienia wówczas, gdy występują wprawdzie trzy zmienne decyzyjne, ale jedno z ograniczeń ma charakter równości, w związku z czym jedną ze zmiennych można po prostu wyrugować z układu ograniczającego. Weźmy następujące zadanie programowania liniowego.
Warunki brzegowe typowe: $x_1 \geq 0$, $x_2\geq 0$, $x_3\geq 0$.
Ponieważ trzecie ograniczenie jest równością, można wykorzystać je do wyrugowania jednej ze zmiennych, poprzez przedstawienie jej, jako funkcji liniowej dwu pozostałych zmiennych. Załóżmy, że wyrugujemy zmienną $x_1$ (wyrugowanie zmiennej $x_3$ może być kłopotliwe, z uwagi na ułamkowe współczynniki, jakie się w takim wypadku pojawią).
Przekształcając trzecie ograniczenie dostajemy:
$$x_1 = x_2 - 2x_3 + 12$$
Zależność tę podstawiamy do funkcji celu oraz dwu pozostałych ograniczeń, otrzymując:
Czy to już wszystko? Otóż nie. Na wszystkie trzy zmienne narzucono warunki nieujemności, zatem zmienna $x_1$ również musi być nieujemna, co oznacza konieczność uwzględnienia jeszcze jednej nierówności: $x_2 - 2x_3 \geq -12$. Teraz mamy już kompletne, przekształcone zadanie programowania liniowego z dwiema zmiennymi decyzyjnymi:
i takie zadanie może już być z powodzeniem rozwiązane metodą graficzną. Komentarza wymaga funkcja celu, w której pojawia się stała (wyraz wolny). Otóż zadanie takie rozwiązuje się po prostu w taki sposób, jakby stała ta była równa zero, bowiem jeśli wyrażenie $6x_2 - 3 x_3$ osiągnie wartość maksymalną (minimalną), to i w sposób oczywisty wartość wyrażenia $6x_2 - 3 x_3 + 24$ również będzie maksymalna (minimalna).
Przedstawiony problem można uogólnić – metodą graficzną mogą być rozwiązane także zadania programowania liniowego z k zmiennymi decyzyjnymi ($k>2$), o ile wśród ograniczeń takiego zadania wystąpi $k-2$ liniowo niezależnych równości.
Innym przypadkiem zadania z większą niż dwie ilością zmiennych decyzyjnych, które może być rozwiązane z wykorzystaniem metody graficznej, jest zadanie zawierające więcej niż dwie zmienne decyzyjne, ale tylko dwa warunki ograniczające. Zadanie takie może być rozwiązane metoda graficzną z wykorzystaniem dualności zadań programowania liniowego. Jest to jednak temat o tyle obszerny, że poświęcony mu będzie osobny artykuł.
Sebastian Dziarmaga-Działyński
Kwantyle w szeregu szczegółowym
Mgr inż.
Sebastian Dziarmaga-Działyński
Wprowadzenie
Jednym z zagadnień statystyki opisowej, gdzie wśród autorów podręczników i nauczycieli akademickich nie ma konsensusu, jest kwestia obliczania kwantyli (w szczególności kwartyli, mediany) dla danych podanych w postaci szeregu szczegółowego (indywidualnego). Kwantyle stanowią jedno z kluczowych pojęć w statystyce opisowej. W tym artykule przyjrzymy się, czym kwantyle w statystyce są naprawdę, jak definiuje się je w szeregu szczegółowym oraz dlaczego sposób ich przedstawiania w podręcznikach akademickich często budzi wątpliwości.
O ile dla szeregów rozdzielczych przedziałowych w zasadzie obowiązuje jednolity wzór:
$x_{0m}$ jest lewym krańcem przedziału zawierającego dany kwantyl,
$N_q = n \cdot q$ jest numerem pozycji danego kwantyla,
$nsk_{m-1}$ jest skumulowaną liczebnością przedziału poprzedzającego przedział zawierający kwantyl; jeśli kwantyl jest w przedziale pierwszym, przyjmuje się $nsk_0 = 0$,
$n_m$ jest liczebnością przedziału zawierającego kwantyl,
$h_m$ jest długością przedziału zawierającego dany kwantyl.
Użycie tego wzoru wymaga ustalenia, w którym przedziale znajduje się kwantyl – jest to najniższy przedział, którego liczebność skumulowana jest równa co najmniej $N_q$.
o tyle w przypadku szeregów szczegółowych podejścia są bardzo różne.
Najczęściej stosowane wzory na kwantyle
Pełna zgodność panuje w zasadzie tylko przy obliczaniu mediany. Obowiązuje tutaj zasada, że medianę oblicza się w zależności od tego, czy liczebność zbioru danych jest parzysta, czy nieparzysta.
Dla parzystej ilości danych, medianę oblicza się jako średnia arytmetyczną dwu „środkowych” elementów uporządkowanego ciągu danych, tj:
dla szeregu zawierającego nieparzystą ilość danych, mediana równa jest wartości „środkowej”, tj.:
$$Me=x_{{n+1} \over 2}$$
jeśli jednak chodzi o pozostałe kwartyle, czy też kwantyle innych rzędów (np. decyle, centyle) jednolitości takiej już nie ma.
Kwartyle w statystyce opisowej: Q1 (dolny), mediana Q2 i Q3 (górny).
Kwartyle – dolny ($Q_1$) oraz górny ($Q_3$) obliczane są – według nauczycieli akademickich na większości polskich uczelni – na jeden z dwu sposobów:
według sposobu podanego w „kultowym” podręczniku W. Krysicki, J. Bartos, K. Królikowska i inni Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, tj. szereg danych dzielony jest na dwie grupy – do pierwszej zalicza się wszystkie wartości mniejsze od mediany i medianę, a do drugiej medianę i wszystkie wartości większe od mediany – i następnie kwartyl dolny oblicza się, jako medianę pierwszej, a górny – jako medianę drugiej grupy wartości.
poprzez „zaokrąglenie” (zazwyczaj za pomocą funkcji entier – zwanej swojsko „podłogą”) wartości $n \over 4$ oraz ${3 \over 4} n$ i przyjęcie wartości kwartyla równej wartości w uporządkowanym szeregu danych, stojącej na tak obliczonych pozycjach. Co gorsze, niektórzy nauczyciele akademiccy zamiast $n$ stosują $n+1$… Ręce opadają.
O ile pierwszy z wymienionych sposobów można uznać za w miarę logiczny i zasadny, choć niepozbawiony kontrowersji zwłaszcza w sytuacji, gdy kilka wartości w szeregu równych jest medianie (przy literalnym traktowaniu podręcznikowego przepisu należałoby wartość taką wziąć tylko raz), o tyle drugi ze sposobów nie może być nazwany inaczej, jak „radosna twórczość” akademickich nauczycieli całkowicie pozbawionych statystycznego „wyczucia”.
Największy mankament pierwszego z opisywanych sposobów jest taki, że za pomocą tego schematu obliczyć można w zasadzie tylko kwartyle. Przeprowadzając dalsze „połowienie” szeregu danych, w analogiczny sposób można policzyć np. kwantyle rzędu 0,125; 0,375,… (oktyle?), ale nie znajdują one zastosowania w praktyce statystycznej.
Drugi z opisywanych sposobów jest całkowicie bezsensowny chociażby przez to, że „na siłę” dopasowuje kwartyle, czy też wyliczane kwantyle innych rzędów, dokładnie do wartości danych z szeregu, podczas gdy przykład mediany dla parzystej ilości danych pokazuje, że nie zawsze wartość kwantyla musi rekrutować się spośród wartości z szeregu. Taka zbieżność wręcz, o ile nie mówimy o szeregu rozdzielczym punktowym, gdzie sporo wartości się powtarza, jest na ogół wyłącznie dziełem przypadku (czy raczej występuje wyłącznie dla konkretnych wartości $n$ – i w przypadku kwartyli bynajmniej nie są to wartości podzielne przez 4, co dobitnie pokazuje mediana, która wprost równa jest wartości z szeregu tylko dla nieparzystych (a zatem niepodzielnych przez 2) wartości.
Najgorsze i najbardziej groteskowe w tym wszystkim jest to, że jako korepetytor przygotowujący studentów do kolokwiów i egzaminów, sam muszę ich tych sposobów uczyć… Czuję się wówczas, jak katecheta, który wziął zastępstwo za polonistkę i przerabia akurat mitologię grecką.
Okazuje się, że pojęcie o obliczaniu kwantyli w szeregu szczegółowym mają jedynie programiści firmy Microsoft…
Jak powinniśmy obliczać kwantyle w szeregu szczegółowym?
Jak wiemy, „idealne” do obliczenia mediany są szeregi szczegółowe o nieparzystej ilości danych. Dla przypomnienia, weźmy szereg o pięciu elementach. Jako, że tym etapie interesuje nas wyłącznie pozycja elementu, a nie jego wartość, toteż zamiast liczb rozważać będziemy „kółka”. Każdorazowo pisząc o szeregu, będziemy mieli na myśli uporządkowany ciąg danych od najmniejszej do największej wartości.
Położenie mediany w szeregu szczegółowym o pięciu elementach
Jak widać, medianą jest trzeci element, gdyż zgodnie z „filozofią” mediany, tyle samo elementów jest na lewo od niego, ile elementów jest po jego prawej stronie.
Pozycję mediany wyznaczyć tutaj możemy, jako: $N_{Me} = {{n + 1} \over 2}$
W tym samym szeregu zauważymy również, że idealnymi kwartylami: dolnym i górnym są odpowiednio drugi oraz czwarty element:
Położenie kwartyli (dolnego i górnego) w szeregu szczegółowym o pięciu elementach
Dlaczego tak? A dlatego, że pierwszy element po swojej prawej stronie ma dokładnie trzy razy więcej elementów niż po swojej lewej stronie (1 vs 3 tak samo, jak 25% vs 75%) i analogicznie czwarty element ma po swojej lewej stronie trzykrotnie więcej elementów, niż po prawej.
Jak się za chwilę okaże, takie „dokładne trafienie” w pozycję kwartyla ma miejsce zawsze, gdy ilość elementów szeregu jest postaci $4k+1$, czyli przy dzieleniu przez cztery daje resztę jeden.
Który jednak element, jako kwartyl, wskażą wspomniane wcześniej dwa najpopularniejsze w nauczaniu akademickim sposoby? W przypadku sposobu z podręcznika „Krysicki i inni”, wszystko zależy od konkretnych wartości. Dla szeregu bowiem:
1; 2; 3; 4; 5
Medianą jest 3 i obie grupy mieć będą postaci: 1; 2; 3 oraz 3; 4; 5 i jako kwartyle dolny i górny poprawnie wskazane zostaną liczby odpowiednio 2 oraz 4. Jednak już dla szeregu:
1; 2; 2; 3; 3
Medianą jest 2 i pierwszą grupę (elementy mniejsze od mediany i medianę) tworzą liczby 1, 2 a ich medianą, czyli pierwszym kwartylem jest liczba 1,5.
Drugi ze sposobów daje jeszcze dziwniejsze wyniki. $n=5$, zatem $Q_1 = x_{\left[ n \over 4 \right]} = x_{[1,25]}=x_1$ oraz $Q_3 = x_{\left[ {3 \over 4} \cdot n \right]} = x_{[3,75]}=x_3$ Przyjmując zasadę zaokrąglania matematycznego, zamiast funkcji „podłoga” otrzymamy w tym akurat wypadku prawidłowy wynik $Q_3=x_4$.
Nieco lepiej sprawa będzie wyglądać, gdy – jak to niektórzy nauczyciele akademiccy robią – zamiast $n$ użyjemy $n+1$. Zaokrąglając za pomocą funkcji „podłoga” otrzymamy $Q_1=x_1$ oraz $Q_3=x_4$ natomiast zaokrąglając matematycznie uzyskamy $Q_1=x_2$ oraz $Q_3=x_5$ (sic!).
Oczywiście zupełnie bezsensowne rezultaty tą metodą otrzymamy dla ilości elementów niespełniających warunku $n = 4k +1$. Wówczas bowiem, jako kwartyle zostają cały czas wskazane konkretne elementy z szeregu, podczas gdy intuicja powinna nam mówić, że muszą to być jakieś elementy „pośrednie” – tak, jak dzieje się to w przypadku mediany przy parzystej ilości elementów.
Jak zatem podejść do problemu?
Otóż, aby wyznaczyć kwartyle i dowolnego rzędu inne kwantyle w szeregu szczegółowym, należy zacząć od wyznaczenia w prawidłowy sposób, pozycji tego kwantyla. Jeśli będzie to liczba całkowita, wówczas kwantylem będzie wartość w szeregu stojąca na tej właśnie pozycji. Jeśli będzie to pozycja o wartości ułamkowej, kwantyl otrzymamy interpolując liniowo wartość stojącą na pozycji równej wyznaczonej pozycji kwantyla zaokrąglonej w dół i kolejnej wartości.
Rozważmy szereg zawierający $n$ elementów. Zgodnie z najczęściej stosowanym w statystyce zwyczajem, elementy te numerujemy indeksami od $1$ do $n$. Stąd wynika, że długość takiego szeregu wynosi $n-1$. Zrozumienie tego, prostego skądinąd, faktu jest kluczowe dla prawidłowego liczenia kwantyli w szeregu szczegółowym.
„Odległość” pomiędzy danymi w szeregu szczegółowym
W takiej sytuacji, przykładowo mediana znajdować się powinna w „odległości” ${n-1} \over 2$ od pierwszej wartości szeregu, kwartyl dolny w odległości ${n-1} \over 4$ i – ogólnie – kwantyl rzędu $q$ w odległości $(n-1) \cdot q$.
Zaraz zaraz, czy aby na pewno $n - 1$? Na pewno! Zauważmy, że wprawdzie odległość liczymy od zera, ale dane indeksujemy od 1, stąd aby wyliczyć pozycję kwantyla, należy do tak wyliczonej odległości dodać 1.
Eureka! Już wiemy, skąd we wzorze wzięło się $n+1$, w bezrefleksyjny sposób przenoszone przez wielu prowadzących zajęcia ze statystyki na wyższych uczelniach, na kwantyle innego rzędu.
W przypadku bowiem kwantyli innego rzędu, $n+1$ już się nie pojawi, gdyż wzór na numer pozycji będzie miał postać:
$$N_q = {{\left( n - 1 \right) q} + 1}$$
Jeśli tak wyliczony numer pozycji okaże się liczbą całkowitą, to – jak wspomniano wyżej – kwantyl równy będzie po prostu wskazanemu elementowi. Co jednak, jeśli pozycja kwantyla wyjdzie wartością ułamkową?
Wyprowadzamy prawidłowy wzór na kwantyl rzędu q
Kwantyl o pozycji niebędącej liczbą całkowitą
Załóżmy, że pozycja kwantyla $q$ wynosi $k+w$, gdzie k jest częścią całkowitą $k=\left[ N_q \right]$ natomiast $w$ jest częścią ułamkową. W takiej sytuacji logicznym jest, że kwantyl $q$ powinien zostać wyznaczony poprzez interpolację liniową wartości $x_k$ oraz $x_{k+1}$.
Dokonajmy takiej interpolacji:
$$q=x_k + \left(x_{k+1} - x_k \right) \cdot w = x_k \cdot \left(1 - w \right) + x_{k+1} \cdot w$$
Jak widać, kwantyl $q$ jest średnią ważoną wartości na pozycjach $k$ oraz $k+1$ w szeregu, gdzie wagami przy wartości na danej pozycji szeregu są odległości od drugiej z pozycji.
W takiej sytuacji, wzór na kwantyl rzędu $q$ może być zapisany w następującej postaci:
gdzie oczywiście $\left[ x \right]$ jest funkcją „podłoga”, znaną także pod nazwą funkcji entier, czyli największa liczbą całkowita nie większa od $x$ (kiedyś, w czasach popularności tablic logarytmicznych, funkcja ta nazywała się po prostu cechą liczby $x$).
Wyprowadzony wzór wygląda dość skomplikowanie. Można go jednak zapisać w postaci prostego algorytmu.
Wyznacz numer pozycji kwantyla $N_q = {\left(n - 1 \right) \cdot q} + 1$
Jeśli tak wyznaczony numer jest liczbą całkowitą, to $q={x_{N_q}}$, czyli szukany kwantyl jest równy elementowi uporządkowanego szeregu na wyznaczonej pozycji. Kończymy obliczenia. W przeciwnym razie wykonaj punkt 3.
Niech $k=\left[ N_q \right]$, tj. zaokrąglamy w dół wartość $N_q$ i wyznaczamy w ten sposób k-tą pozycję w szeregu. Jeśli $x_k = x_{k+1}$, tj. jeśli wartości w szeregu na pozycjach $k$ oraz $k+1$ są jednakowe, to ich wspólna wartość jest obliczaną wartością kwantyla: $q = x_k = x_{k+1}$. Kończymy obliczenia. W przeciwnym razie przechodzimy do pkt 4.
Niech $w$ oznacza część ułamkową wyznaczonej pozycji kwantyla: $w=N_q - \left[ N_q \right]$. Obliczamy wartość kwantyla, jako: $q = x_k \cdot (1-w) + x_{k+1} \cdot w$.
Ten sposób oczywiście działa również dla mediany, dając identyczne wyniki z „klasycznym” sposobem, albowiem dla parzystej wartości $n$, numer pozycji $N_{Me} = \left( n - 1 \right) \cdot 0.5 +1 = {{n+1} \over 2} $ posiada część ułamkową $w=0,5$ i medianą jest średnią ważoną z liczb na pozycjach $n \over 2$ oraz ${n \over 2} + 1$ z obiema wagami równymi 0,5, a zatem ich średnią arytmetyczną.
Przykłady
Przykład nr 1
Weźmy uporządkowany szereg o 11 elementach: 2; 3; 5; 5; 7; 9; 10; 18; 21; 24; 25
Obliczmy dla tego szeregu najczęściej liczone kwantyle, tj.: medianę, dolny (pierwszy) oraz górny (trzeci) kwartyl, używane do wyliczenia pozycyjnych wersji odchylenia ćwiartkowego, współczynnika zmienności oraz współczynnika asymetrii a także decyle pierwszy oraz dziewiąty, służące do wyliczenia pozycyjnego współczynnika skupienia.
Jak widać, oba decyle i mediana mają całkowite numery pozycji, zatem są one równe wprost odpowiednim elementom szeregu:
$d_1 = x_2 = 3$
$Me = x_6 = 9$
$d_9 = x_{10} = 24$
Natomiast części ułamkowe numerów kwartyli równe są 0,5 co oznacza, że są one równe de facto średnim arytmetycznym dwu sąsiednich elementów: kwartyl pierwszy jest średnią elementów trzeciego oraz czwartego natomiast kwartyl trzeci – ósmego i dziewiątego.
Tym razem wszystkie pozycje są ułamkowe. Wartości poszczególnych kwantyli obliczamy jako średnie ważone wartości na obu pozycjach „pomiędzy” którymi wypada wyliczona pozycja ułamkowa, tj. wartością zaokrągloną w dół i wartością następną.
Dla decyla pierwszego będzie to średnia ważona elementów na pozycjach 1 oraz 2. Ponieważ część ułamkowa wynosi 0,9, toteż wartość z pozycji pierwszej będzie ważona wartością 0,1 a wartość z pozycji drugiej – wagą 0,9.
Weźmy dane w postaci szeregu rozdzielczego punktowego. Szereg rozdzielczy punktowy stanowi tak naprawdę efekt „kompresji bezstratnej” szeregu szczegółowego, zatem obowiązują dokładnie te same reguły. Ponieważ jednak znacznie częściej będzie się zdarzać, że dane się będą powtarzać, toteż obliczanie zazwyczaj będzie uproszczone (średnia ważoną dwu takich samych liczb równa jest tym liczbom, niezależnie od wag – punkt 3 algorytmu).
Do ustalenia pozycji poszczególnych elementów w szeregu, wykorzystujemy liczebności skumulowane. Wyliczamy ten sam zestaw kwantyli, co poprzednio.
W przypadku decyla pierwszego, zarówno na pozycji szóstej, jak i siódmej jest liczba 1, a zatem:
$d_1 = x_6 = x_7 = 1$
Analogicznie obliczając kwartyl pierwszy zauważamy, że na pozycjach 15 oraz 16 jest również ta sama liczba i również jest to 1:
$Q_1 = x_{16} = x_{17} = 1$
Tak samo licząc medianę, zauważmy, że tak na pozycji 30, jak i na pozycji 31 jest ta sama liczba i jest to liczba 2, zatem:
$Me = x_{30} = x_{31} = 2$
W przypadku kwartyla trzeciego sytuacja jest odmienna. Zaokrąglając numer kwartyla (45,25) w dół, zauważamy, że na pozycji czterdziestej piątej jest jeszcze liczba 3, ale na kolejnej, czterdziestej szóstej pozycji jest liczba 4. Wobec tego należy użyć średniej ważonej. Jako, że część ułamkowa wynosi 0,25, to wagi wyniosą odpowiednio 0,75 oraz 0,25:
I tak samo w przypadku dziewiątego decyla. Numer jego pozycji to 54,1. Na pozycji 54. jest jeszcze liczba 4, ale na 55. pozycji jest liczba 5. Wobec tego decyl ten jest średnią ważoną z tych liczb, z wagami równymi odpowiednio 0,9 oraz 0,1:
Sceptyk może zapytać – skoro na polskich uczelniach, w ramach kursu statystyki, nikt tak nie liczy kwantyli w szeregu szczegółowym, to może jednak nie mam racji? A jeśli mam rację, to może powinienem zgłosić to doniosłe odkrycie? Cóż, na medal Fieldsa jestem już zbyt dorosły – a sposób liczenia wcale nie jest jakiś nieznany, czy przełomowy. Od lat jest bowiem stosowany w arkuszach kalkulacyjnych z najpopularniejszym Excelem na czele. Czytelnik może łatwo sprawdzić, że każdy z zaprezentowanych przykładów w Excelu da identyczny wynik z otrzymanym tutaj – oczywiście dane z przykładu 3 trzeba będzie wprowadzić do Excela, jako szereg szczegółowy, tj. wpisać pięciokrotnie zero, dwanaście razy jedynkę i tak dalej.
Na pytanie: dlaczego na polskich uczelniach uczy się studentów herezji, niestety nie jestem w stanie odpowiedzieć.