
Dobór zmiennych do modelu ekonometrycznego
Wprowadzenie
Dobór zmiennych do modelu ekonometrycznego jest jednym z najważniejszych etapów budowy modelu. Nawet bardzo dobra metoda estymacji, na przykład metoda najmniejszych kwadratów, nie uratuje modelu, jeżeli już na początku wybierzemy niewłaściwe zmienne objaśniające. Model może wtedy wyglądać poprawnie formalnie, ale prowadzić do błędnych, przypadkowych albo trudnych do interpretacji wniosków.
W ekonometrii nie chodzi o mechaniczne wrzucenie do modelu wszystkich dostępnych kolumn z arkusza kalkulacyjnego. Zmienne powinny mieć uzasadnienie merytoryczne, odpowiednią zmienność, właściwy kierunek oddziaływania oraz nie powinny nadmiernie powielać informacji zawartej w innych zmiennych. Dlatego dobór zmiennych łączy wiedzę z zakresu ekonomii, statystyki, matematyki i praktycznej analizy danych.
W tym artykule omawiamy zarówno merytoryczne, jak i formalne metody doboru zmiennych. Wyjaśniamy, czym są metody a priori i a posteriori, dlaczego należy uważać na zmienne quasi-stałe oraz współliniowość, na czym polega metoda Hellwiga, metoda analizy współczynników korelacji, metoda grafowa Bartosiewiczowej oraz eliminacja zmiennych na podstawie wyników oszacowanego modelu.
Spis treści
- Dlaczego dobór zmiennych jest ważny?
- Zmienna objaśniana i zmienne objaśniające
- Merytoryczne kryteria doboru zmiennych
- Zmienność zmiennych objaśniających
- Zmienne quasi-stałe
- Współliniowość zmiennych objaśniających
- VIF — współczynnik inflacji wariancji
- Metody a priori i a posteriori doboru zmiennych
- Metoda analizy współczynników korelacji
- Metoda grafowa Bartosiewiczowej
- Metoda Hellwiga
- Przykład metody Hellwiga
- Eliminacja a posteriori zmiennych nieistotnych
- Ryzyko mechanicznego doboru zmiennych
- Jak łączyć różne metody doboru zmiennych?
- Podsumowanie
Dlaczego dobór zmiennych jest ważny?
Model ekonometryczny ma opisywać zależność między zmienną objaśnianą a zmiennymi objaśniającymi. Jeżeli dobierzemy zmienne przypadkowo, model może pokazywać pozorne zależności, które nie mają sensu merytorycznego. Może też pomijać ważne czynniki, przez co parametry pozostałych zmiennych zostaną oszacowane w sposób zniekształcony.
Dobór zmiennych wpływa między innymi na:
interpretację parametrów modelu,
istotność statystyczną zmiennych,
jakość prognoz,
wielkość błędów standardowych,
współczynnik determinacji,
stabilność oszacowań,
zgodność modelu z teorią ekonomii lub inną teorią dziedzinową.
Zbyt ubogi model może pomijać ważne czynniki. Zbyt rozbudowany model może być trudny do interpretacji, nadmiernie dopasowany do konkretnej próby albo obciążony problemem współliniowości. Dlatego dobór zmiennych jest sztuką znalezienia rozsądnego kompromisu między prostotą, merytorycznością i jakością statystyczną.
Zmienna objaśniana i zmienne objaśniające
Punktem wyjścia jest określenie zmiennej objaśnianej, czyli tej wielkości, którą chcemy wyjaśnić, opisać lub prognozować. Oznacza się ją zwykle symbolem $Y$. Może to być na przykład sprzedaż, cena mieszkania, zysk przedsiębiorstwa, poziom wynagrodzenia, stopa bezrobocia albo wartość kredytów zagrożonych w banku.
Zmienne objaśniające oznacza się zwykle jako $X_1, X_2, \ldots, X_k$. Są to czynniki, które potencjalnie wpływają na zmienną $Y$. W modelu ceny mieszkania mogą to być powierzchnia, liczba pokoi, lokalizacja, piętro i rok budowy. W modelu sprzedaży mogą to być cena, wydatki na reklamę, dochody konsumentów, sezonowość i liczba punktów sprzedaży.
Ogólną postać liniowego modelu ekonometrycznego zapisujemy jako:
$$Y_i = \beta_0 + \beta_1X_{1i} + \beta_2X_{2i} + \ldots + \beta_kX_{ki} + \varepsilon_i$$
Dobór zmiennych polega na ustaleniu, które spośród potencjalnych zmiennych $X_1, X_2, \ldots, X_m$ powinny ostatecznie znaleźć się w modelu.
Merytoryczne kryteria doboru zmiennych
Pierwszym kryterium doboru zmiennych powinien być sens merytoryczny. Zmienna objaśniająca powinna mieć uzasadnienie w teorii ekonomii, finansów, zarządzania, socjologii, demografii albo innej dziedzinie, której dotyczy model.
Przykładowo, jeżeli budujemy model popytu, naturalnymi zmiennymi objaśniającymi mogą być cena dobra, dochód konsumentów, ceny dóbr substytucyjnych i komplementarnych, preferencje konsumentów oraz sezonowość. Jeżeli budujemy model wynagrodzeń, sensowne zmienne to między innymi staż pracy, wykształcenie, branża, region, doświadczenie zawodowe i stanowisko.
Zmienna nie powinna być wybierana tylko dlatego, że „ładnie koreluje” ze zmienną objaśnianą. Korelacja może być przypadkowa, pozorna albo wynikać z działania trzeciej zmiennej. Dlatego przed zastosowaniem formalnych metod selekcji warto zadać pytania:
czy dana zmienna może rzeczywiście wpływać na zmienną objaśnianą?
czy kierunek tego wpływu jest zgodny z teorią?
czy zmienna jest mierzona poprawnie?
czy zależność ma charakter przyczynowo-skutkowy, czy tylko statystyczny?
czy zmienna jest dostępna w praktyce, jeżeli model ma służyć do prognozowania?
W praktyce dobry model powinien łączyć trzy elementy: sens merytoryczny, poprawność statystyczną oraz użyteczność praktyczną.
Zmienność zmiennych objaśniających
Zmienna objaśniająca powinna wykazywać odpowiednią zmienność. Jeżeli prawie się nie zmienia, trudno oczekiwać, że pomoże wyjaśnić zmienność zmiennej objaśnianej. Taka zmienna nie wnosi do modelu istotnej informacji, ponieważ jej wartości są prawie takie same dla wszystkich obserwacji.
Do oceny zmienności można wykorzystać na przykład współczynnik zmienności:
$$V_j = \frac{s_j}{\bar{x}_j} \cdot 100\%$$
gdzie $s_j$ oznacza odchylenie standardowe zmiennej $X_j$, a $\bar{x}_j$ jej średnią arytmetyczną. Jeżeli współczynnik zmienności jest bardzo mały, zmienna może zostać uznana za quasi-stałą.
Trzeba jednak uważać przy zmiennych, których średnia jest bliska zeru albo które mogą przyjmować wartości ujemne. Wtedy klasyczny współczynnik zmienności może być mylący. W takich przypadkach warto analizować także odchylenie standardowe, zakres zmienności, wykresy oraz sens ekonomiczny zmiennej.
Zmienne quasi-stałe
Zmienna quasi-stała to zmienna, która w badanej próbie przyjmuje bardzo podobne wartości. Nie musi być dokładnie stała, ale jej zmienność jest tak mała, że praktycznie nie pomaga w wyjaśnianiu zmian zmiennej objaśnianej.
Jeżeli model zawiera wyraz wolny, zmienna prawie stała może w pewnym sensie „gryźć się” z wyrazem wolnym. Wyraz wolny reprezentuje stały poziom zmiennej objaśnianej, a zmienna quasi-stała dostarcza bardzo podobnej informacji dla wszystkich obserwacji. W efekcie jej parametr zwykle jest mało precyzyjnie oszacowany i często okazuje się nieistotny statystycznie.
Przykładowo, jeżeli analizujemy ceny mieszkań w jednym mieście i jedna ze zmiennych przyjmuje wartość 1 dla prawie wszystkich obserwacji, a tylko sporadycznie wartość 0, to taka zmienna może nie dostarczać wystarczającej informacji. Podobnie, jeżeli w modelu przedsiębiorstw prawie wszystkie firmy należą do tej samej branży, zmienna branżowa może być praktycznie bezużyteczna w danej próbie.
Wstępna selekcja zmiennych często zaczyna się właśnie od usunięcia zmiennych o zbyt małej zmienności, brakach danych, błędnych pomiarach albo zbyt małej wartości informacyjnej.
Współliniowość zmiennych objaśniających
Kolejnym ważnym problemem jest współliniowość zmiennych objaśniających. Występuje ona wtedy, gdy jedna zmienna objaśniająca jest silnie powiązana z innymi zmiennymi objaśniającymi. Jeżeli zależność jest dokładna, mówimy o dokładnej współliniowości. Jeżeli jest bardzo silna, ale nie idealna, mówimy o silnej współliniowości.
Dokładna współliniowość uniemożliwia oszacowanie klasycznego modelu MNK, ponieważ macierz $\mathbf{X}'\mathbf{X}$ nie jest odwracalna. W praktyce częściej spotykamy jednak silną, ale niedokładną współliniowość. Model da się wtedy oszacować, ale jego wyniki mogą być niestabilne.
Silna współliniowość może powodować:
duże błędy standardowe parametrów,
brak istotności pojedynczych parametrów mimo wysokiego dopasowania modelu,
zmianę znaków parametrów na sprzeczne z teorią,
dużą wrażliwość wyników na dodanie lub usunięcie kilku obserwacji,
trudności z interpretacją wpływu poszczególnych zmiennych.
Współliniowość jest jednym z głównych powodów, dla których nie należy wprowadzać do modelu wielu zmiennych opisujących prawie to samo zjawisko. Przykładowo dochód gospodarstwa domowego, wydatki ogółem i poziom konsumpcji mogą być ze sobą bardzo silnie powiązane. Podobnie aktywa ogółem, przychody i liczba pracowników mogą jednocześnie mierzyć skalę przedsiębiorstwa.
VIF — współczynnik inflacji wariancji
Jedną z najczęściej stosowanych miar współliniowości jest VIF, czyli variance inflation factor, po polsku współczynnik inflacji wariancji.
Dla zmiennej $X_j$ współczynnik VIF oblicza się według wzoru:
$$VIF_j = \frac{1}{1 - R_j^2}$$
gdzie $R_j^2$ oznacza współczynnik determinacji z regresji pomocniczej, w której zmienna $X_j$ jest objaśniana przez pozostałe zmienne objaśniające.
Jeżeli $X_j$ jest słabo powiązana z pozostałymi zmiennymi, $R_j^2$ jest małe, a VIF jest bliski 1. Jeżeli $X_j$ jest silnie wyjaśniana przez pozostałe zmienne, $R_j^2$ zbliża się do 1, a VIF gwałtownie rośnie.
W praktyce często przyjmuje się orientacyjnie, że VIF powyżej 5 może sygnalizować problem, a VIF powyżej 10 oznacza poważną współliniowość. Nie są to jednak granice absolutne. Wiele zależy od celu badania, liczby obserwacji, rodzaju danych i charakteru zmiennych.
O współliniowości warto wspomnieć zarówno przy doborze zmiennych, jak i przy weryfikacji modelu ekonometrycznego. Na etapie doboru zmiennych staramy się unikać zmiennych nadmiernie skorelowanych, a po oszacowaniu modelu możemy dodatkowo sprawdzić wartości VIF i stabilność parametrów.
Metody a priori i a posteriori doboru zmiennych
Metody doboru zmiennych można podzielić na dwie duże grupy: metody a priori oraz metody a posteriori.
Metody a priori stosuje się przed oszacowaniem ostatecznego modelu. Wykorzystują one wiedzę merytoryczną, zmienność zmiennych, korelacje między zmiennymi oraz formalne procedury selekcji. Celem jest wybranie rozsądnego zestawu zmiennych jeszcze przed estymacją modelu.
Do metod a priori można zaliczyć między innymi:
dobór merytoryczny na podstawie teorii,
eliminację zmiennych quasi-stałych,
analizę korelacji zmiennych objaśniających ze zmienną objaśnianą,
analizę korelacji między zmiennymi objaśniającymi,
metodę analizy współczynników korelacji,
metodę grafową Bartosiewiczowej,
metodę Hellwiga.
Metody a posteriori stosuje się po oszacowaniu modelu. Polegają one na analizie wyników estymacji: istotności parametrów, znaków parametrów, błędów standardowych, VIF, dopasowania modelu oraz diagnostyki reszt. Najbardziej typowym przykładem jest eliminacja zmiennych nieistotnych statystycznie.
W praktyce najlepsze efekty daje połączenie obu podejść. Najpierw warto przygotować merytorycznie uzasadniony i statystycznie rozsądny zestaw kandydatów, a dopiero później dopracować model na podstawie wyników estymacji.
Metoda analizy współczynników korelacji
Metoda analizy współczynników korelacji jest jedną z klasycznych metod a priori doboru zmiennych objaśniających. Jej idea polega na wyborze takich zmiennych, które są istotnie skorelowane ze zmienną objaśnianą $Y$, ale jednocześnie nie są zbyt silnie skorelowane między sobą.
W tej metodzie nie należy opierać się wyłącznie na umownych określeniach typu „słaba”, „umiarkowana” lub „silna” korelacja. W klasycznym ujęciu wyznacza się krytyczną wartość współczynnika korelacji, oznaczaną zwykle jako $r^*$. Wartość ta zależy od przyjętego poziomu istotności oraz od liczebności próby.
Punktem wyjścia jest test istotności współczynnika korelacji Pearsona. Dla hipotezy:
$$H_0: \rho = 0$$
$$H_1: \rho \neq 0$$
stosuje się statystykę:
$$t = \frac{r\sqrt{n-2}}{\sqrt{1-r^2}}$$
gdzie $r$ oznacza współczynnik korelacji z próby, a $n$ oznacza liczbę obserwacji. Po przekształceniu tego wzoru otrzymujemy krytyczną wartość współczynnika korelacji:
$$r^* = \frac{t^*}{\sqrt{(t^*)^2+n-2}}$$
gdzie $t^*$ oznacza wartość krytyczną rozkładu t-Studenta dla $n-2$ stopni swobody oraz przyjętego poziomu istotności, najczęściej $\alpha = 0{,}05$. Przy teście dwustronnym wartość $t^*$ odczytujemy dla poziomu $\alpha/2$ w każdym ogonie rozkładu.
Następnie porównujemy wartości bezwzględne współczynników korelacji z wartością krytyczną $r^*$. Jeżeli:
$$|r_{0j}| > r^*$$
to zmienna $X_j$ jest istotnie skorelowana ze zmienną objaśnianą $Y$ i może być kandydatem do modelu. Jeżeli natomiast:
$$|r_{0j}| \leq r^*$$
to zmienna $X_j$ jest zbyt słabo powiązana ze zmienną objaśnianą i zwykle usuwa się ją ze zbioru kandydatów.
Podobnie analizujemy korelacje między zmiennymi objaśniającymi. Jeżeli dwie zmienne objaśniające są ze sobą zbyt silnie skorelowane, czyli:
$$|r_{ij}| > r^*$$
to zwykle nie powinny jednocześnie znaleźć się w modelu, ponieważ mogą prowadzić do współliniowości. Z takiej pary pozostawia się najczęściej tę zmienną, która jest silniej skorelowana ze zmienną objaśnianą $Y$ albo ma lepsze uzasadnienie merytoryczne.
Typowa procedura może wyglądać następująco:
Obliczamy współczynniki korelacji między $Y$ a wszystkimi potencjalnymi zmiennymi objaśniającymi.
Obliczamy współczynniki korelacji między samymi zmiennymi objaśniającymi.
Wyznaczamy krytyczną wartość korelacji $r^*$ na podstawie rozkładu t-Studenta.
Usuwamy zmienne, dla których $|r_{0j}| \leq r^*$, ponieważ nie są istotnie skorelowane ze zmienną objaśnianą.
Wybieramy zmienną najsilniej skorelowaną ze zmienną $Y$.
Usuwamy ze zbioru kandydatów zmienne zbyt silnie skorelowane z już wybraną zmienną, czyli takie, dla których $|r_{ij}| > r^*$.
Z pozostałych zmiennych wybieramy kolejną najlepiej skorelowaną z $Y$.
Powtarzamy procedurę aż do wyczerpania kandydatów.
Przykładowo, jeżeli dla danej liczby obserwacji i poziomu istotności $\alpha = 0{,}05$ otrzymamy $r^* = 0{,}63$, to korelacje o wartości bezwzględnej mniejszej lub równej 0,63 uznajemy za zbyt słabe. Natomiast korelacje między zmiennymi objaśniającymi większe od 0,63 mogą wskazywać, że zmienne przekazują podobną informację i nie powinny jednocześnie występować w modelu.
Załóżmy, że mamy trzy potencjalne zmienne objaśniające: $X_1$, $X_2$, $X_3$. Ich korelacje ze zmienną $Y$ wynoszą:
$$r_{01}=0{,}82,\quad r_{02}=0{,}76,\quad r_{03}=0{,}12$$
Korelacje między zmiennymi objaśniającymi wynoszą:
$$r_{12}=0{,}91,\quad r_{13}=0{,}10,\quad r_{23}=0{,}08$$
Jeżeli $r^* = 0{,}63$, to zmienna $X_3$ zostanie usunięta, ponieważ $|r_{03}| = 0{,}12 \leq 0{,}63$. Zmienne $X_1$ i $X_2$ są istotnie skorelowane ze zmienną $Y$, ale jednocześnie są bardzo silnie skorelowane między sobą, ponieważ $|r_{12}| = 0{,}91 > 0{,}63$. W takiej sytuacji wybieramy zwykle zmienną $X_1$, ponieważ ma większą korelację ze zmienną objaśnianą niż $X_2$.

Zaletą tej metody jest prostota i jasna logika postępowania. Wadą jest to, że opiera się głównie na korelacjach liniowych parami. Może więc pomijać zmienne merytorycznie ważne, które nie mają silnej prostej korelacji z $Y$, ale stają się istotne w modelu wielowymiarowym albo po odpowiednim przekształceniu.
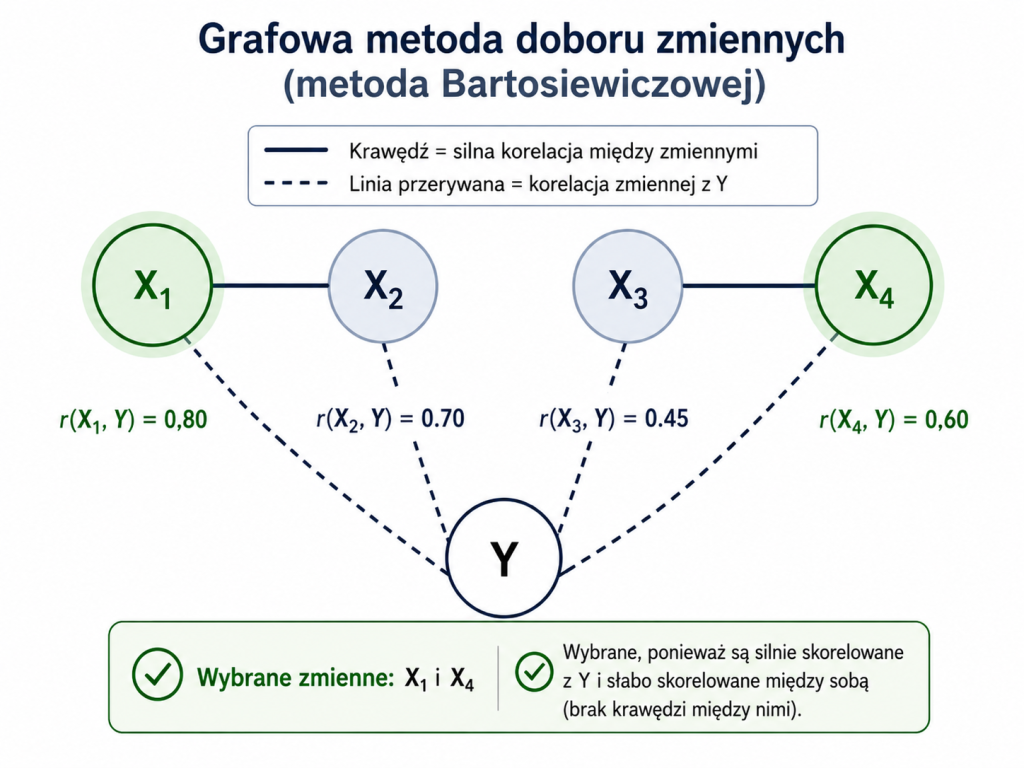
Metoda grafowa Bartosiewiczowej
Metoda grafowa Bartosiewiczowej, nazywana również metodą analizy grafów albo metodą Bartosiewicz, jest klasyczną metodą a priori doboru zmiennych objaśniających. W polskiej dydaktyce ekonometrii pojawia się dość często, choć w praktyce analitycznej bywa rzadziej stosowana niż metody regresyjne lub informacyjne.
Metoda ta polega na zbudowaniu grafu powiązań między potencjalnymi zmiennymi objaśniającymi. Wierzchołkami grafu są zmienne $X_1, X_2, \ldots, X_k$, a krawędź między dwiema zmiennymi pojawia się wtedy, gdy są one zbyt silnie skorelowane, czyli gdy:
$$|r_{ij}| > r^*$$
gdzie $r^*$ oznacza przyjętą krytyczną wartość korelacji.
Interpretacja jest następująca: jeżeli dwie zmienne są połączone krawędzią, to przekazują do modelu podobną informację. Nie chcemy więc zwykle wprowadzać ich obu jednocześnie, ponieważ mogłoby to prowadzić do współliniowości.
W metodzie grafowej szczególnie interesują nas:
zmienne odosobnione, czyli nieskorelowane silnie z innymi kandydatami,
podgrafy zmiennych wzajemnie powiązanych,
zmienne centralne w danym podgrafie, reprezentujące grupę podobnych zmiennych,
korelacje poszczególnych zmiennych ze zmienną objaśnianą $Y$.
Przykładowo załóżmy, że mamy cztery zmienne: $X_1$, $X_2$, $X_3$, $X_4$. Przyjmujemy $r^* = 0{,}7$. Korelacje między zmiennymi objaśniającymi są następujące:
$$r_{12}=0{,}82,\quad r_{13}=0{,}20,\quad r_{14}=0{,}15,\quad r_{23}=0{,}18,\quad r_{24}=0{,}10,\quad r_{34}=0{,}76$$
W grafie pojawią się dwie krawędzie: między $X_1$ i $X_2$ oraz między $X_3$ i $X_4$. Oznacza to, że mamy dwie pary silnie powiązanych zmiennych. Z każdej pary wybieramy zwykle tę zmienną, która jest silniej skorelowana ze zmienną objaśnianą $Y$ albo ma lepsze uzasadnienie merytoryczne.
Jeżeli korelacje ze zmienną $Y$ wynoszą:
$$r_{01}=0{,}80,\quad r_{02}=0{,}70,\quad r_{03}=0{,}45,\quad r_{04}=0{,}60$$
to z pary $X_1$, $X_2$ wybralibyśmy raczej $X_1$, a z pary $X_3$, $X_4$ raczej $X_4$. Ostatecznie do modelu mogłyby trafić zmienne $X_1$ i $X_4$.
Zaletą metody grafowej jest przejrzystość. Bardzo dobrze pokazuje ona problem współliniowości i grupowania podobnych zmiennych. Wadą jest pewna arbitralność wyboru wartości krytycznej $r^*$ oraz uproszczone traktowanie zależności, ponieważ metoda opiera się głównie na korelacjach parami.
Metoda Hellwiga
Metoda Hellwiga, nazywana również metodą wskaźników pojemności informacji albo metodą optymalnego wyboru predyktant, jest jedną z najbardziej znanych formalnych metod doboru zmiennych objaśniających w polskiej ekonometrii.
Jej idea polega na tym, aby wybrać taki podzbiór zmiennych objaśniających, który ma dużą wartość informacyjną względem zmiennej objaśnianej, ale jednocześnie nie zawiera zmiennych silnie powielających tę samą informację.
Metoda Hellwiga premiuje więc zmienne silnie skorelowane ze zmienną $Y$, ale karze zestawy zmiennych, które są zbyt silnie skorelowane między sobą. Dzięki temu dobrze wpisuje się w klasyczną zasadę: zmienne objaśniające powinny mocno wyjaśniać zmienną objaśnianą i jednocześnie nie powinny być nadmiernie współliniowe.
Dla każdego niepustego podzbioru zmiennych objaśniających oblicza się indywidualne pojemności informacyjne, a następnie integralną pojemność informacyjną całego podzbioru.
Jedna z często spotykanych postaci indywidualnej pojemności informacyjnej zmiennej $X_j$ w podzbiorze $l$ ma postać:
$$h_{lj} = \frac{r_{0j}^2}{1 + \sum_{i \in I_l,\, i \neq j}|r_{ij}|}$$
gdzie:
$r_{0j}$ — korelacja zmiennej $X_j$ ze zmienną objaśnianą $Y$,
$r_{ij}$ — korelacja między zmiennymi objaśniającymi $X_i$ i $X_j$,
$I_l$ — rozpatrywany podzbiór zmiennych objaśniających.
Integralna pojemność informacyjna podzbioru $l$ jest sumą indywidualnych pojemności informacyjnych:
$$H_l = \sum_{j \in I_l} h_{lj}$$
Wybieramy ten podzbiór zmiennych, dla którego wartość $H_l$ jest największa.
Jeżeli mamy $m$ potencjalnych zmiennych objaśniających, liczba niepustych podzbiorów wynosi:
$$2^m - 1$$
Dla trzech zmiennych mamy więc 7 podzbiorów, dla czterech 15, dla pięciu 31, a dla dziesięciu już 1023. Przy większej liczbie zmiennych ręczne obliczenia stają się więc pracochłonne, ale w arkuszu kalkulacyjnym lub programie statystycznym można je zautomatyzować.
Metoda Hellwiga jest czasem krytykowana, ponieważ opiera się na korelacjach i formalnej miarze informacyjnej, która nie zastępuje wiedzy merytorycznej. Mimo to jest bardzo często spotykana w dydaktyce ekonometrii na polskich uczelniach i dobrze pokazuje problem kompromisu między informacją a współliniowością.
Przykład metody Hellwiga
Rozważmy prosty przykład z trzema potencjalnymi zmiennymi objaśniającymi: $X_1$, $X_2$, $X_3$. Załóżmy, że korelacje ze zmienną objaśnianą $Y$ wynoszą:
$$r_{01}=0{,}80,\quad r_{02}=0{,}70,\quad r_{03}=0{,}40$$
Korelacje między zmiennymi objaśniającymi wynoszą:
$$r_{12}=0{,}85,\quad r_{13}=0{,}20,\quad r_{23}=0{,}30$$
Mamy trzy zmienne, więc rozpatrujemy $2^3 - 1 = 7$ niepustych podzbiorów:
$\{X_1\}$,
$\{X_2\}$,
$\{X_3\}$,
$\{X_1, X_2\}$,
$\{X_1, X_3\}$,
$\{X_2, X_3\}$,
$\{X_1, X_2, X_3\}$.
Dla jednoelementowych podzbiorów pojemność informacyjna jest po prostu kwadratem korelacji ze zmienną $Y$:
$$H_{\{X_1\}} = 0{,}80^2 = 0{,}64$$
$$H_{\{X_2\}} = 0{,}70^2 = 0{,}49$$
$$H_{\{X_3\}} = 0{,}40^2 = 0{,}16$$
Dla podzbioru $\{X_1, X_2\}$ otrzymujemy:
$$h_1 = \frac{0{,}80^2}{1+|0{,}85|} = \frac{0{,}64}{1{,}85} \approx 0{,}346$$
$$h_2 = \frac{0{,}70^2}{1+|0{,}85|} = \frac{0{,}49}{1{,}85} \approx 0{,}265$$
$$H_{\{X_1,X_2\}} \approx 0{,}346 + 0{,}265 = 0{,}611$$
Mimo że $X_1$ i $X_2$ są mocno skorelowane z $Y$, ich wspólny zestaw jest karany za bardzo silną korelację między sobą.
Dla podzbioru $\{X_1, X_3\}$:
$$h_1 = \frac{0{,}80^2}{1+|0{,}20|} = \frac{0{,}64}{1{,}20} \approx 0{,}533$$
$$h_3 = \frac{0{,}40^2}{1+|0{,}20|} = \frac{0{,}16}{1{,}20} \approx 0{,}133$$
$$H_{\{X_1,X_3\}} \approx 0{,}666$$
Dla podzbioru $\{X_2, X_3\}$:
$$h_2 = \frac{0{,}70^2}{1+|0{,}30|} = \frac{0{,}49}{1{,}30} \approx 0{,}377$$
$$h_3 = \frac{0{,}40^2}{1+|0{,}30|} = \frac{0{,}16}{1{,}30} \approx 0{,}123$$
$$H_{\{X_2,X_3\}} \approx 0{,}500$$
Dla pełnego podzbioru $\{X_1, X_2, X_3\}$:
$$h_1 = \frac{0{,}80^2}{1+|0{,}85|+|0{,}20|} = \frac{0{,}64}{2{,}05} \approx 0{,}312$$
$$h_2 = \frac{0{,}70^2}{1+|0{,}85|+|0{,}30|} = \frac{0{,}49}{2{,}15} \approx 0{,}228$$
$$h_3 = \frac{0{,}40^2}{1+|0{,}20|+|0{,}30|} = \frac{0{,}16}{1{,}50} \approx 0{,}107$$
$$H_{\{X_1,X_2,X_3\}} \approx 0{,}647$$
Porównując wartości $H_l$, otrzymujemy orientacyjnie:
| Podzbiór zmiennych | Integralna pojemność informacyjna |
|---|---|
| {X1} | 0,640 |
| {X2} | 0,490 |
| {X3} | 0,160 |
| {X1, X2} | 0,611 |
| {X1, X3} | 0,666 |
| {X2, X3} | 0,500 |
| {X1, X2, X3} | 0,647 |
Największą wartość uzyskuje podzbiór $\{X_1, X_3\}$, więc według metody Hellwiga to właśnie ten zestaw zmiennych należałoby wybrać do modelu.
Warto zauważyć, że metoda nie wybrała pary $X_1$, $X_2$, mimo że obie zmienne są silnie skorelowane z $Y$. Powodem jest ich bardzo silna korelacja między sobą. Metoda Hellwiga uznała, że lepiej połączyć silną zmienną $X_1$ ze słabszą, ale bardziej niezależną informacyjnie zmienną $X_3$.
Eliminacja a posteriori zmiennych nieistotnych
W praktyce bardzo często stosuje się metodę eliminacji a posteriori. Polega ona na oszacowaniu modelu z pełnym, wstępnie wybranym zestawem zmiennych, a następnie stopniowym usuwaniu zmiennych nieistotnych statystycznie.
Typowa procedura wygląda następująco:
Dobieramy wstępny zestaw zmiennych na podstawie teorii i analizy danych.
Szacujemy model zawierający wszystkie wybrane zmienne.
Sprawdzamy istotność parametrów, najczęściej za pomocą testu t-Studenta.
Usuwamy zmienną o najwyższym p-value, jeżeli jest nieistotna statystycznie.
Ponownie szacujemy model.
Powtarzamy procedurę, aż w modelu pozostaną zmienne istotne albo merytorycznie konieczne.
Metoda ta jest intuicyjna i często stosowana w praktyce, ale ma także ograniczenia. Usunięcie jednej zmiennej może zmienić istotność pozostałych zmiennych, zwłaszcza gdy występuje współliniowość. Czasami zmienna nieistotna statystycznie jest ważna merytorycznie i jej usunięcie prowadzi do błędnej specyfikacji modelu.
Dlatego eliminacja a posteriori nie powinna być stosowana mechanicznie. Nie należy usuwać zmiennej tylko dlatego, że jej p-value przekracza 0,05, jeżeli zmienna jest kluczowa z punktu widzenia teorii albo pełni funkcję kontrolną. W badaniach ekonomicznych często ważniejszy jest sens modelu niż ślepe podporządkowanie się jednej procedurze statystycznej.
Można spotkać sytuację, w której po kolejnych eliminacjach w modelu pozostają tylko dwie zmienne, ale model traci sens ekonomiczny. Można też spotkać sytuację odwrotną: zmienna jest merytorycznie ważna, ale w konkretnej próbie okazuje się nieistotna, na przykład z powodu małej liczby obserwacji albo współliniowości.
Ryzyko mechanicznego doboru zmiennych
Formalne metody doboru zmiennych są pomocne, ale nie powinny zastępować myślenia. Każda metoda ma swoje ograniczenia. Metody korelacyjne badają głównie zależności liniowe parami. Metoda Hellwiga opiera się na korelacjach i pojemności informacyjnej. Metoda grafowa dobrze pokazuje współliniowość, ale także zależy od przyjętej wartości krytycznej korelacji. Eliminacja a posteriori może prowadzić do modelu dopasowanego do konkretnej próby, ale słabego merytorycznie.
Do najczęstszych błędów należą:
dobór zmiennych wyłącznie na podstawie korelacji,
ignorowanie teorii ekonomii,
usuwanie zmiennych kontrolnych tylko dlatego, że są nieistotne,
wprowadzanie do modelu wielu zmiennych opisujących to samo zjawisko,
pomijanie problemu współliniowości,
zbyt mechaniczne stosowanie progów p-value,
budowanie modelu pod z góry oczekiwany wynik.
Model ekonometryczny powinien być nie tylko statystycznie poprawny, ale także merytorycznie sensowny. Jeżeli wynik formalnej procedury jest sprzeczny z teorią albo zdrowym rozsądkiem, warto wrócić do danych i zastanowić się, czy nie występuje problem pomiaru, pominięcia ważnej zmiennej, obserwacji odstających albo błędnej postaci modelu.
Jak łączyć różne metody doboru zmiennych?
W praktyce dobór zmiennych najlepiej prowadzić etapami. Nie ma jednej metody, która zawsze daje najlepszy model. Rozsądna procedura może wyglądać następująco:
Najpierw określamy problem badawczy i zmienną objaśnianą.
Na podstawie teorii i wiedzy dziedzinowej tworzymy listę potencjalnych zmiennych objaśniających.
Usuwamy zmienne z błędami, dużą liczbą braków danych albo zbyt małą zmiennością.
Analizujemy korelacje zmiennych z $Y$ oraz korelacje między zmiennymi objaśniającymi.
Sprawdzamy ryzyko współliniowości, na przykład przy pomocy macierzy korelacji lub VIF.
Możemy pomocniczo zastosować metodę Hellwiga, metodę grafową albo analizę współczynników korelacji.
Szacujemy model i przeprowadzamy eliminację a posteriori, ale z zachowaniem kontroli merytorycznej.
Na końcu przeprowadzamy weryfikację modelu ekonometrycznego: testy istotności, diagnostykę reszt i ocenę specyfikacji.
Takie połączenie metod pozwala uniknąć dwóch skrajności. Z jednej strony nie opieramy modelu wyłącznie na intuicji, z drugiej strony nie oddajemy całej decyzji automatycznej procedurze matematycznej.
Dobór zmiennych jest procesem iteracyjnym. Czasami po oszacowaniu modelu trzeba wrócić do wcześniejszych etapów, zmienić zestaw zmiennych, przekształcić zmienne, usunąć obserwacje odstające albo przemyśleć samą postać modelu.
Podsumowanie
Dobór zmiennych do modelu ekonometrycznego jest jednym z kluczowych etapów modelowania. Zmienne powinny być dobrane nieprzypadkowo, zgodnie z teorią i celem badania. Powinny mieć odpowiednią zmienność, być sensownie mierzone i nie powinny nadmiernie powielać informacji zawartej w innych zmiennych.
Wstępna selekcja zmiennych obejmuje zwykle ocenę merytoryczną, analizę zmienności, eliminację zmiennych quasi-stałych oraz analizę współliniowości. Silnie skorelowane zmienne objaśniające mogą prowadzić do dużych błędów standardowych parametrów, niestabilnych oszacowań i problemów interpretacyjnych. Pomocną miarą współliniowości jest współczynnik VIF.
Do klasycznych metod a priori należą metoda analizy współczynników korelacji, metoda grafowa Bartosiewiczowej oraz metoda Hellwiga. Metoda Hellwiga wybiera podzbiór zmiennych o największej integralnej pojemności informacyjnej, premiując zmienne silnie powiązane z $Y$ i jednocześnie niezbyt silnie skorelowane między sobą.
Metody a posteriori, takie jak eliminacja zmiennych nieistotnych statystycznie, są bardzo użyteczne, ale nie powinny być stosowane mechanicznie. Wyniki testów istotności należy zawsze interpretować w kontekście wiedzy merytorycznej, celu modelu oraz jakości danych.
Dobry dobór zmiennych jest kompromisem między teorią, statystyką i praktycznym celem modelu. To właśnie od tego etapu w dużej mierze zależy, czy model ekonometryczny będzie nie tylko poprawny formalnie, ale także sensowny i użyteczny.
Utworzono: 16.05.2026 | Zmodyfikowano: 18.05.2026
Powiązane artykuły
- Model ekonometryczny — czym jest, do czego służy i jak go zbudować?
- Metoda najmniejszych kwadratów — estymacja parametrów modelu ekonometrycznego
- Dane przekrojowe, szeregi czasowe i dane panelowe w ekonometrii
- Generator danych do modelu ekonometrycznego online
- Weryfikacja modelu ekonometrycznego
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc