
Metoda najmniejszych kwadratów — estymacja parametrów modelu ekonometrycznego
Wprowadzenie
Metoda najmniejszych kwadratów, często oznaczana skrótem MNK, jest jedną z podstawowych metod stosowanych w ekonometrii, statystyce i analizie danych. Jej głównym zadaniem jest estymacja parametrów modelu ekonometrycznego, czyli oszacowanie nieznanych współczynników opisujących zależność między zmienną objaśnianą a zmiennymi objaśniającymi.
W praktyce bardzo często nie znamy prawdziwego, „idealnego” modelu opisującego całą populację. Nie znamy także jego prawdziwych parametrów strukturalnych. Dysponujemy jedynie próbą danych, czyli pewnym fragmentem rzeczywistości. Na podstawie tej próby próbujemy możliwie dobrze odtworzyć zależność zachodzącą w populacji. Właśnie do tego służy metoda najmniejszych kwadratów.
W najprostszym ujęciu MNK polega na takim dobraniu prostej, płaszczyzny albo ogólnie hiperpłaszczyzny regresji, aby suma kwadratów odchyleń wartości rzeczywistych od wartości teoretycznych była jak najmniejsza. Mówiąc bardziej obrazowo: szukamy takiego równania modelu, które możliwie dobrze „przechodzi” przez chmurę punktów, ale nie musi przechodzić dokładnie przez każdy punkt.
W tym artykule wyjaśniamy, czym jest metoda najmniejszych kwadratów, jaka jest jej intuicja, jak wygląda zapis skalarny i macierzowy, czym różnią się parametry modelu od ich ocen, co oznaczają błędy standardowe oszacowania parametrów oraz jakie znaczenie mają założenia Gaussa-Markowa.
Spis treści
- Czym jest metoda najmniejszych kwadratów?
- Model populacyjny a model oszacowany
- Intuicja metody najmniejszych kwadratów
- Prosty model liniowy z jedną zmienną objaśniającą
- Wzory MNK dla modelu z jedną zmienną objaśniającą
- Macierzowy zapis metody najmniejszych kwadratów
- Reszty modelu i suma kwadratów reszt
- Odchylenie standardowe reszt i współczynnik zmienności reszt
- Współczynnik determinacji R²
- Błędy standardowe oszacowania parametrów
- Model z dwiema zmiennymi objaśniającymi
- Założenia Gaussa-Markowa
- Autokorelacja i heteroskedastyczność na wykresach
- Twierdzenie Gaussa-Markowa
- Czego nie obejmuje sama metoda MNK?
- Podsumowanie
Czym jest metoda najmniejszych kwadratów?
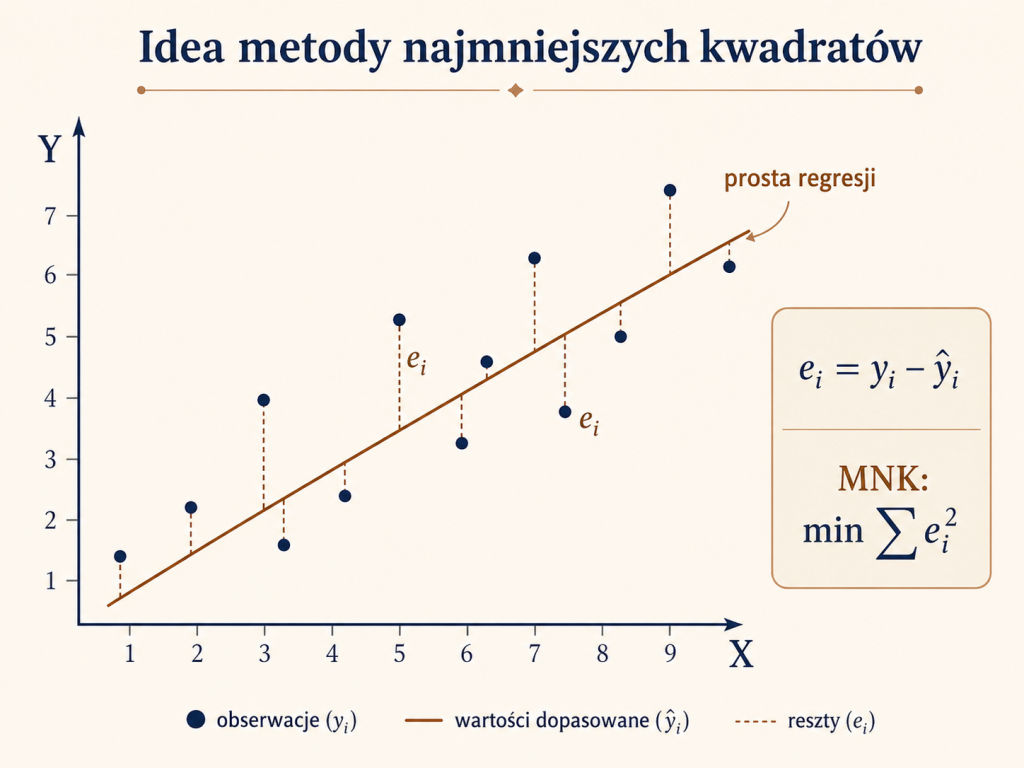
Metoda najmniejszych kwadratów to metoda estymacji parametrów modelu, w której wybieramy takie wartości parametrów, aby suma kwadratów różnic między wartościami zaobserwowanymi a wartościami przewidywanymi przez model była minimalna.
Jeżeli rzeczywista wartość zmiennej objaśnianej dla $i$-tej obserwacji wynosi $y_i$, a wartość teoretyczna, czyli przewidywana przez model, wynosi $\hat{y}_i$, to różnicę między nimi nazywamy resztą:
$$e_i = y_i - \hat{y}_i$$
Metoda najmniejszych kwadratów polega na minimalizacji sumy kwadratów tych reszt:
$$SSE = \sum_{i=1}^{n} e_i^2 = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2$$
Skrót $SSE$ pochodzi od angielskiego określenia sum of squared errors, czyli suma kwadratów błędów albo suma kwadratów reszt. W polskiej literaturze spotyka się również oznaczenia takie jak $SKR$, czyli suma kwadratów reszt.
Kwadraty stosuje się między innymi dlatego, że dodatnie i ujemne odchylenia nie znoszą się wzajemnie. Gdybyśmy minimalizowali zwykłą sumę reszt, dodatnie i ujemne błędy mogłyby się kasować, nawet gdy model byłby źle dopasowany. Podnoszenie do kwadratu sprawia, że każda reszta wnosi dodatni wkład do miary niedopasowania, a duże błędy są „karane” silniej niż małe.
Model populacyjny a model oszacowany
Aby dobrze zrozumieć metodę najmniejszych kwadratów, trzeba odróżnić model populacyjny od modelu oszacowanego na podstawie próby.
W teorii możemy wyobrazić sobie, że w populacji istnieje pewna prawdziwa zależność między zmienną objaśnianą $Y$ a zmiennymi objaśniającymi $X_1, X_2, \ldots, X_k$. Dla liniowego modelu ekonometrycznego zapisujemy ją na przykład tak:
$$Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \ldots + \beta_kX_k + \varepsilon$$
Parametry $\beta_0, \beta_1, \ldots, \beta_k$ są parametrami strukturalnymi modelu populacyjnego. To one opisują prawdziwą, teoretyczną zależność w całej populacji. Problem polega na tym, że w praktyce zwykle ich nie znamy i nie możemy ich poznać bezpośrednio.
Gdybyśmy znali wszystkie obserwacje w populacji i dokładnie wiedzieli, jak działa mechanizm generujący dane, moglibyśmy mówić o idealnym modelu. W rzeczywistych badaniach ekonomicznych, finansowych czy społecznych dysponujemy jednak najczęściej tylko próbą. Na jej podstawie szacujemy parametry, otrzymując ich oceny:
$$\hat{\beta}_0, \hat{\beta}_1, \ldots, \hat{\beta}_k$$
Oszacowany model przyjmuje wtedy postać:
$$\hat{Y} = \hat{\beta}_0 + \hat{\beta}_1X_1 + \hat{\beta}_2X_2 + \ldots + \hat{\beta}_kX_k$$
Warto zauważyć, że symbole z daszkiem, na przykład $\hat{\beta}_1$, oznaczają oceny parametrów, a nie same prawdziwe parametry. Metoda najmniejszych kwadratów nie daje nam więc bezpośrednio wartości $\beta_1$, lecz jej oszacowanie na podstawie danych z próby.
W tym sensie MNK jest metodą estymacji. Nie odkrywamy wprost idealnego modelu populacyjnego, lecz budujemy jego przybliżenie. Jakość tego przybliżenia zależy od wielu czynników: liczebności próby, jakości danych, poprawności doboru zmiennych, spełnienia założeń modelu oraz losowego charakteru próby.
W niektórych podręcznikach mówi się w tym kontekście o regresji teoretycznej, populacyjnej lub regresji pierwszego rodzaju, rozumianej jako zależność zachodząca w populacji, oraz o regresji empirycznej, wyznaczonej na podstawie próby. W praktyce badawczej znamy zwykle tylko tę drugą, czyli oszacowaną postać modelu.
Intuicja metody najmniejszych kwadratów
Najłatwiej zrozumieć MNK na przykładzie wykresu punktowego. Wyobraźmy sobie, że na osi poziomej zaznaczamy wydatki na reklamę, a na osi pionowej sprzedaż. Każdy punkt odpowiada jednej obserwacji, na przykład jednemu miesiącowi działalności firmy.
Jeżeli między wydatkami na reklamę a sprzedażą występuje dodatnia zależność, punkty będą układały się mniej więcej wzdłuż rosnącego kierunku. Nie będą jednak leżały idealnie na jednej prostej, ponieważ sprzedaż zależy również od wielu innych czynników: sezonu, działań konkurencji, cen, przypadkowych zdarzeń czy ogólnej sytuacji rynkowej.
Metoda najmniejszych kwadratów szuka takiej prostej, dla której pionowe odległości punktów od prostej, po podniesieniu do kwadratu i zsumowaniu, są jak najmniejsze. Te pionowe odległości to właśnie reszty modelu.
Można powiedzieć, że MNK wybiera „najbardziej kompromisową” prostą. Nie musi ona przechodzić przez żaden konkretny punkt, ale jest dobrana tak, aby całościowo najlepiej dopasować się do wszystkich obserwacji.
Prosty model liniowy z jedną zmienną objaśniającą
Najprostszym przypadkiem zastosowania metody najmniejszych kwadratów jest model liniowy z jedną zmienną objaśniającą. Model populacyjny można zapisać następująco:
$$Y_i = \beta_0 + \beta_1X_i + \varepsilon_i$$
gdzie:
$Y_i$ — wartość zmiennej objaśnianej dla $i$-tej obserwacji,
$X_i$ — wartość zmiennej objaśniającej dla $i$-tej obserwacji,
$\beta_0$ — wyraz wolny modelu populacyjnego,
$\beta_1$ — współczynnik kierunkowy modelu populacyjnego,
$\varepsilon_i$ — składnik losowy dla $i$-tej obserwacji.
Na podstawie próby szacujemy model:
$$\hat{Y}_i = \hat{\beta}_0 + \hat{\beta}_1X_i$$
W modelu z jedną zmienną objaśniającą $\hat{\beta}_0$ i $\hat{\beta}_1$ mają bardzo prostą interpretację. Parametr $\hat{\beta}_0$ oznacza przewidywaną wartość zmiennej $Y$, gdy $X = 0$. Parametr $\hat{\beta}_1$ informuje, o ile przeciętnie zmieni się wartość $Y$, gdy $X$ wzrośnie o jedną jednostkę.
Przykładowo, jeżeli oszacowany model sprzedaży ma postać:
$$\hat{Y} = 12000 + 4{,}5X$$
to wzrost wydatków reklamowych o jedną jednostkę wiąże się przeciętnie ze wzrostem przewidywanej sprzedaży o 4,5 jednostki. Trzeba jednak pamiętać, że jest to interpretacja statystyczna, oparta na danych z próby i przyjętym modelu.
Wzory MNK dla modelu z jedną zmienną objaśniającą
Dla prostego modelu liniowego z jedną zmienną objaśniającą oceny parametrów otrzymane metodą najmniejszych kwadratów można obliczyć ze wzorów:
$$\hat{\beta}_1 = \frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n}(x_i - \bar{x})^2}$$
oraz:
$$\hat{\beta}_0 = \bar{y} - \hat{\beta}_1\bar{x}$$
gdzie $\bar{x}$ oznacza średnią arytmetyczną wartości zmiennej $X$, $\bar{y}$ oznacza średnią arytmetyczną wartości zmiennej $Y$, a $n$ oznacza liczbę obserwacji w próbie.
W liczniku wzoru na $\hat{\beta}_1$ znajduje się suma iloczynów odchyleń wartości $X$ i $Y$ od ich średnich. Ta część wzoru pokazuje, czy zmienne zmieniają się w tym samym kierunku, czy w przeciwnych kierunkach. W mianowniku znajduje się suma kwadratów odchyleń zmiennej $X$ od jej średniej, czyli miara zróżnicowania zmiennej objaśniającej.
Często stosuje się również skrócone oznaczenia:
$$S_{xx} = \sum_{i=1}^{n}(x_i - \bar{x})^2$$
$$S_{xy} = \sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})$$
Wtedy wzór na współczynnik kierunkowy można zapisać krótko:
$$\hat{\beta}_1 = \frac{S_{xy}}{S_{xx}}$$
Macierzowy zapis metody najmniejszych kwadratów
W modelach z wieloma zmiennymi objaśniającymi wygodniejszy i bardziej uniwersalny jest zapis macierzowy. Klasyczny liniowy model ekonometryczny można zapisać następująco:
$$\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon}$$
gdzie:
$\mathbf{y}$ — wektor wartości zmiennej objaśnianej,
$\mathbf{X}$ — macierz obserwacji zmiennych objaśniających,
$\boldsymbol{\beta}$ — wektor nieznanych parametrów strukturalnych,
$\boldsymbol{\varepsilon}$ — wektor składników losowych.
Dla modelu z wyrazem wolnym macierz $\mathbf{X}$ zawiera w pierwszej kolumnie jedynki:
$$ \mathbf{X} = \begin{bmatrix} 1 & x_{11} & x_{21} & \ldots & x_{k1} \\ 1 & x_{12} & x_{22} & \ldots & x_{k2} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_{1n} & x_{2n} & \ldots & x_{kn} \end{bmatrix} $$
Wektor parametrów ma postać:
$$ \boldsymbol{\beta} = \begin{bmatrix} \beta_0 \\ \beta_1 \\ \beta_2 \\ \vdots \\ \beta_k \end{bmatrix} $$
Ocena wektora parametrów otrzymana metodą najmniejszych kwadratów dana jest wzorem:
$$\hat{\boldsymbol{\beta}} = (\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}$$
Jest to jeden z najważniejszych wzorów w klasycznej ekonometrii. Zapis macierzowy pokazuje, że ta sama metoda działa zarówno dla modelu z jedną zmienną objaśniającą, jak i dla modelu z wieloma zmiennymi. Warunkiem jest między innymi to, aby macierz $\mathbf{X}'\mathbf{X}$ była odwracalna, czyli aby zmienne objaśniające nie były dokładnie liniowo zależne.
Reszty modelu i suma kwadratów reszt
Po oszacowaniu modelu możemy obliczyć wartości teoretyczne:
$$\hat{\mathbf{y}} = \mathbf{X}\hat{\boldsymbol{\beta}}$$
oraz wektor reszt:
$$\mathbf{e} = \mathbf{y} - \hat{\mathbf{y}}$$
czyli:
$$\mathbf{e} = \mathbf{y} - \mathbf{X}\hat{\boldsymbol{\beta}}$$
Suma kwadratów reszt może być zapisana skalarnie:
$$SSE = \sum_{i=1}^{n} e_i^2$$
albo macierzowo:
$$SSE = \mathbf{e}'\mathbf{e}$$
Metoda najmniejszych kwadratów wybiera takie $\hat{\boldsymbol{\beta}}$, dla którego wartość $\mathbf{e}'\mathbf{e}$ jest najmniejsza. Innymi słowy, spośród wszystkich możliwych prostych, płaszczyzn lub hiperpłaszczyzn regresji wybieramy tę, która minimalizuje sumę kwadratów reszt.
Odchylenie standardowe reszt i współczynnik zmienności reszt
Sama suma kwadratów reszt zależy od skali zmiennej objaśnianej oraz od liczby obserwacji, dlatego często wykorzystuje się także odchylenie standardowe reszt, nazywane również standardowym błędem reszt lub standardowym błędem regresji.
Jeżeli model zawiera $p$ szacowanych parametrów, gdzie przy $k$ zmiennych objaśniających i wyrazie wolnym mamy $p = k + 1$, to estymator wariancji składnika losowego zapisujemy jako:
$$\hat{\sigma}^2 = \frac{\sum_{i=1}^{n} e_i^2}{n - p} = \frac{\mathbf{e}'\mathbf{e}}{n - p}$$
Odchylenie standardowe reszt wynosi:
$$s_e = \sqrt{\frac{\sum_{i=1}^{n} e_i^2}{n - p}}$$
Dla modelu z jedną zmienną objaśniającą i wyrazem wolnym mamy dwa szacowane parametry, czyli $p = 2$, dlatego:
$$s_e = \sqrt{\frac{\sum_{i=1}^{n} e_i^2}{n - 2}}$$
Odchylenie standardowe reszt informuje, o ile przeciętnie wartości rzeczywiste odchylają się od wartości teoretycznych wyznaczonych przez model. Im mniejsza wartość $s_e$, tym przeciętnie mniejsze błędy dopasowania modelu.
Czasami wykorzystuje się również współczynnik zmienności reszt, który odnosi odchylenie standardowe reszt do średniej wartości zmiennej objaśnianej:
$$V_e = \frac{s_e}{\bar{y}} \cdot 100\%$$
Jeżeli średnia $\bar{y}$ jest dodatnia i sensowna interpretacyjnie, współczynnik ten pokazuje, jak duży jest typowy błąd modelu w relacji do przeciętnego poziomu zmiennej objaśnianej. W praktyce trzeba jednak uważać, gdy średnia zmiennej $Y$ jest bliska zeru albo gdy zmienna przyjmuje wartości ujemne.
Współczynnik determinacji R²
Jedną z najpopularniejszych miar dopasowania modelu liniowego jest współczynnik determinacji, oznaczany jako $R^2$. Informuje on, jaka część zmienności zmiennej objaśnianej została wyjaśniona przez model.
Całkowitą sumę kwadratów odchyleń zmiennej $Y$ od jej średniej zapisujemy jako:
$$SST = \sum_{i=1}^{n}(y_i - \bar{y})^2$$
Suma kwadratów reszt wynosi:
$$SSE = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2$$
Współczynnik determinacji można zapisać jako:
$$R^2 = 1 - \frac{SSE}{SST}$$
Jeżeli $R^2 = 0{,}80$, to można powiedzieć, że model wyjaśnia 80% zmienności zmiennej objaśnianej w próbie. Pozostałe 20% pozostaje niewyjaśnione przez model i znajduje odzwierciedlenie w resztach.
Należy jednak pamiętać, że wysoki współczynnik determinacji nie oznacza automatycznie, że model jest dobry. Model może być dobrze dopasowany do danych, ale źle wyspecyfikowany, pozbawiony sensownej interpretacji albo oparty na zależnościach przypadkowych. Z tego powodu $R^2$ należy traktować jako jedną z miar dopasowania, a nie jako ostateczny dowód poprawności modelu.
W modelach z wieloma zmiennymi objaśniającymi często stosuje się również skorygowany współczynnik determinacji:
$$\bar{R}^2 = 1 - \frac{SSE/(n-p)}{SST/(n-1)}$$
Skorygowany współczynnik determinacji uwzględnia liczbę parametrów w modelu, dzięki czemu jest bardziej ostrożny przy porównywaniu modeli o różnej liczbie zmiennych objaśniających.
Błędy standardowe oszacowania parametrów
Oceny parametrów $\hat{\beta}_0, \hat{\beta}_1, \ldots, \hat{\beta}_k$ są obliczane na podstawie próby. Gdybyśmy wylosowali inną próbę z tej samej populacji, otrzymalibyśmy zwykle nieco inne oceny parametrów. Oznacza to, że estymatory parametrów są zmiennymi losowymi.
Błąd standardowy oszacowania parametru informuje, jak duża jest przeciętna zmienność estymatora danego parametru. Mówiąc prościej, jest to miara precyzji oszacowania. Mały błąd standardowy oznacza, że dany parametr został oszacowany stosunkowo precyzyjnie. Duży błąd standardowy oznacza większą niepewność oszacowania.
W zapisie macierzowym wariancja estymatora MNK ma postać:
$$Var(\hat{\boldsymbol{\beta}}) = \sigma^2(\mathbf{X}'\mathbf{X})^{-1}$$
Ponieważ prawdziwej wariancji składnika losowego $\sigma^2$ zwykle nie znamy, zastępujemy ją estymatorem $\hat{\sigma}^2$:
$$\widehat{Var}(\hat{\boldsymbol{\beta}}) = \hat{\sigma}^2(\mathbf{X}'\mathbf{X})^{-1}$$
Błędy standardowe poszczególnych parametrów są pierwiastkami z elementów diagonalnych tej macierzy:
$$SE(\hat{\beta}_j) = \sqrt{\widehat{Var}(\hat{\beta}_j)}$$
Dla prostego modelu liniowego z jedną zmienną objaśniającą można zapisać:
$$SE(\hat{\beta}_1) = \frac{s_e}{\sqrt{\sum_{i=1}^{n}(x_i - \bar{x})^2}}$$
oraz:
$$SE(\hat{\beta}_0) = s_e \sqrt{\frac{1}{n} + \frac{\bar{x}^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2}}$$
Błędy standardowe są później wykorzystywane przy weryfikacji istotności parametrów, budowie przedziałów ufności i testach statystycznych. Sama szczegółowa weryfikacja modelu jest jednak osobnym zagadnieniem i zostanie omówiona w oddzielnym artykule.
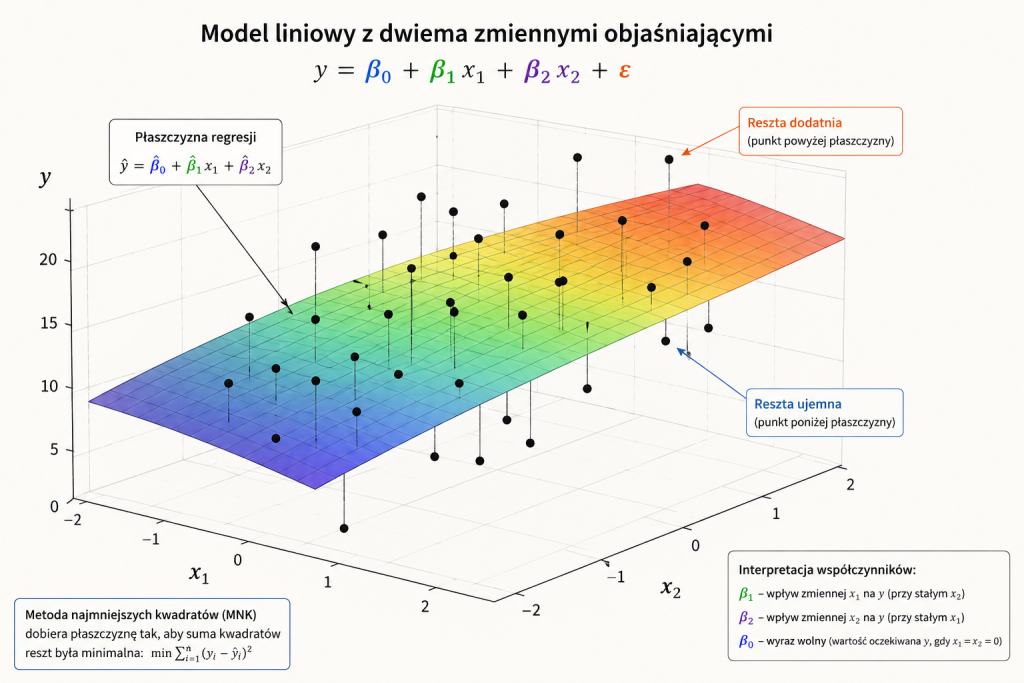
Model z dwiema zmiennymi objaśniającymi
Metoda najmniejszych kwadratów nie ogranicza się do prostej regresji liniowej z jedną zmienną objaśniającą. W modelu z dwiema zmiennymi objaśniającymi zapisujemy:
$$Y_i = \beta_0 + \beta_1X_{1i} + \beta_2X_{2i} + \varepsilon_i$$
Oszacowany model ma postać:
$$\hat{Y}_i = \hat{\beta}_0 + \hat{\beta}_1X_{1i} + \hat{\beta}_2X_{2i}$$
Geometrycznie nie dopasowujemy już prostej do punktów na płaszczyźnie, lecz płaszczyznę do punktów w przestrzeni trójwymiarowej. Na jednej osi znajduje się zmienna $X_1$, na drugiej zmienna $X_2$, a na trzeciej zmienna $Y$.
Parametr $\hat{\beta}_1$ informuje, jak zmienia się przewidywana wartość $Y$, gdy $X_1$ wzrośnie o jedną jednostkę, przy założeniu, że $X_2$ pozostaje bez zmian. Analogicznie $\hat{\beta}_2$ opisuje wpływ zmiennej $X_2$ przy stałym poziomie $X_1$.
To właśnie sformułowanie „przy pozostałych zmiennych niezmienionych” jest bardzo ważne w modelu wielorakim. Parametr przy danej zmiennej nie opisuje już prostej zależności między dwiema zmiennymi, lecz wpływ jednej zmiennej po uwzględnieniu pozostałych zmiennych w modelu.
Założenia Gaussa-Markowa
Metoda najmniejszych kwadratów ma bardzo dobre własności, ale pod pewnymi warunkami. Warunki te są znane jako założenia Gaussa-Markowa. W różnych podręcznikach mogą być formułowane nieco inaczej, ale ich sens jest podobny.
Najważniejsze założenia klasycznego modelu liniowego można przedstawić następująco.
1. Liniowość modelu względem parametrów
Model powinien być liniowy względem parametrów:
$$Y = \beta_0 + \beta_1X_1 + \ldots + \beta_kX_k + \varepsilon$$
Nie oznacza to, że wszystkie zmienne muszą występować wyłącznie w pierwszej potędze. Można stosować na przykład $X^2$, $\ln X$ albo inne przekształcenia zmiennych, o ile model pozostaje liniowy względem parametrów $\beta_0, \beta_1, \ldots, \beta_k$.
2. Brak dokładnej współliniowości zmiennych objaśniających
Zmienne objaśniające nie mogą być dokładnie liniowo zależne. Innymi słowy, żadna zmienna objaśniająca nie powinna być dokładną kombinacją liniową pozostałych zmiennych.
Gdyby taka zależność wystąpiła, macierz $\mathbf{X}'\mathbf{X}$ nie byłaby odwracalna, a wzór:
$$\hat{\boldsymbol{\beta}} = (\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}$$
nie mógłby zostać zastosowany w standardowej postaci. W praktyce problemem bywa także bardzo silna, choć nie idealna współliniowość, ponieważ prowadzi do dużych błędów standardowych parametrów i trudności interpretacyjnych.
3. Egzogeniczność zmiennych objaśniających
Jedno z najważniejszych założeń mówi, że składnik losowy ma wartość oczekiwaną równą zero przy danych wartościach zmiennych objaśniających:
$$E(\varepsilon_i \mid \mathbf{X}) = 0$$
Intuicyjnie oznacza to, że zmienne objaśniające nie powinny być powiązane z tym, co zostało ukryte w składniku losowym. Jeżeli istotny czynnik został pominięty w modelu i jednocześnie jest skorelowany z jedną ze zmiennych objaśniających, oszacowania parametrów mogą być obciążone.
Przykładowo, jeżeli badamy wpływ wykształcenia na wynagrodzenie, ale pomijamy doświadczenie zawodowe, a doświadczenie jest powiązane z poziomem wykształcenia, to część wpływu doświadczenia może błędnie zostać przypisana wykształceniu.
4. Stała wariancja składnika losowego, czyli homoskedastyczność
Założenie homoskedastyczności oznacza, że wariancja składnika losowego jest stała dla wszystkich obserwacji:
$$Var(\varepsilon_i \mid \mathbf{X}) = \sigma^2$$
Jeżeli wariancja składnika losowego zmienia się w zależności od poziomu zmiennych objaśniających, mówimy o heteroskedastyczności. Przykładowo, przy modelowaniu wydatków gospodarstw domowych błędy modelu mogą być większe dla gospodarstw o wysokich dochodach niż dla gospodarstw o niskich dochodach.
Heteroskedastyczność nie musi powodować obciążenia samych ocen parametrów MNK, ale wpływa na błędy standardowe, a więc również na testy istotności i przedziały ufności. Dlatego jest ważnym problemem przy weryfikacji modelu.
5. Brak autokorelacji składnika losowego
Założenie braku autokorelacji oznacza, że składniki losowe dla różnych obserwacji nie są ze sobą skorelowane:
$$Cov(\varepsilon_i, \varepsilon_j \mid \mathbf{X}) = 0 \quad \text{dla } i \neq j$$
Autokorelacja pojawia się szczególnie często w szeregach czasowych. Oznacza sytuację, w której błąd z jednego okresu jest powiązany z błędem z innego okresu. Przykładowo, jeżeli model systematycznie niedoszacowuje sprzedaż w jednym miesiącu, może również niedoszacowywać ją w kolejnym miesiącu.
Autokorelacja jest problemem, ponieważ narusza klasyczne założenia dotyczące składnika losowego i może prowadzić do błędnych wniosków statystycznych. Podobnie jak heteroskedastyczność, jest szczegółowo analizowana na etapie weryfikacji modelu.
6. Zmienne objaśniające jako nielosowe albo traktowane warunkowo
W klasycznym ujęciu często zakłada się, że zmienne objaśniające są nielosowe, czyli ich wartości są ustalone w powtarzalnych próbach. W bardziej współczesnym ujęciu dopuszcza się losowość zmiennych objaśniających, ale analizę prowadzi się warunkowo względem zaobserwowanej macierzy $\mathbf{X}$.
Dla praktycznej interpretacji najważniejsze jest to, aby zmienne objaśniające nie były powiązane ze składnikiem losowym w sposób naruszający założenie egzogeniczności. Jeżeli taka zależność występuje, metoda najmniejszych kwadratów może dawać mylące wyniki.
7. Normalność składnika losowego — założenie dodatkowe
Często przy klasycznym modelu liniowym pojawia się również założenie normalności składnika losowego:
$$\varepsilon_i \sim N(0, \sigma^2)$$
Warto jednak podkreślić, że normalność nie jest konieczna do samego twierdzenia Gaussa-Markowa. Jest natomiast ważna przy dokładnym wnioskowaniu statystycznym w małych próbach, na przykład przy klasycznych testach $t$ i $F$. W dużych próbach wiele procedur opiera się również na wynikach asymptotycznych.
Autokorelacja i heteroskedastyczność na wykresach
Założenia Gaussa-Markowa mogą wydawać się dość abstrakcyjne, dlatego warto zobaczyć je na prostych wykresach. Szczególnie dobrze widać na nich dwa częste problemy: autokorelację reszt oraz heteroskedastyczność.
W dobrze określonym modelu reszty powinny zachowywać się możliwie losowo. Nie powinny tworzyć długich serii wartości dodatnich albo ujemnych, nie powinny też układać się w regularny naprzemienny wzór. Również ich rozrzut powinien być względnie podobny w całym zakresie zmiennych objaśniających.
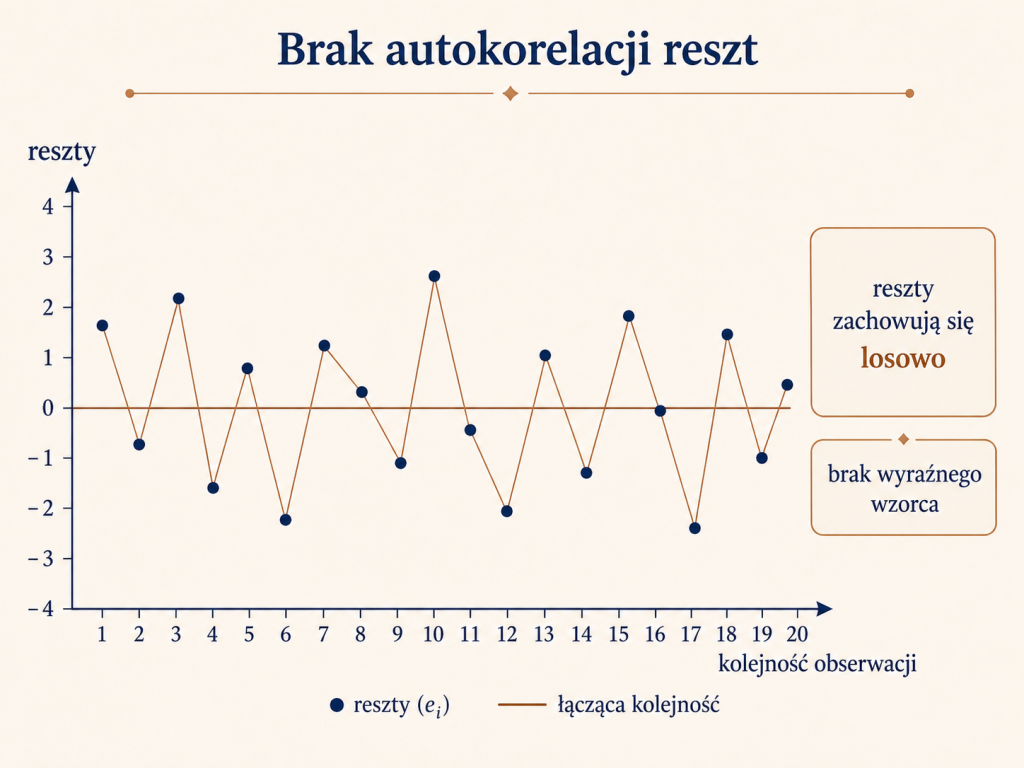
Brak autokorelacji reszt
Gdy reszty nie wykazują autokorelacji, ich wartości zmieniają się w sposób nieregularny. Nie widzimy długich serii dodatnich lub ujemnych reszt ani wyraźnego mechanicznego wzorca. Taki układ jest pożądany, ponieważ sugeruje, że model nie zostawia w resztach łatwo zauważalnej, uporządkowanej informacji.
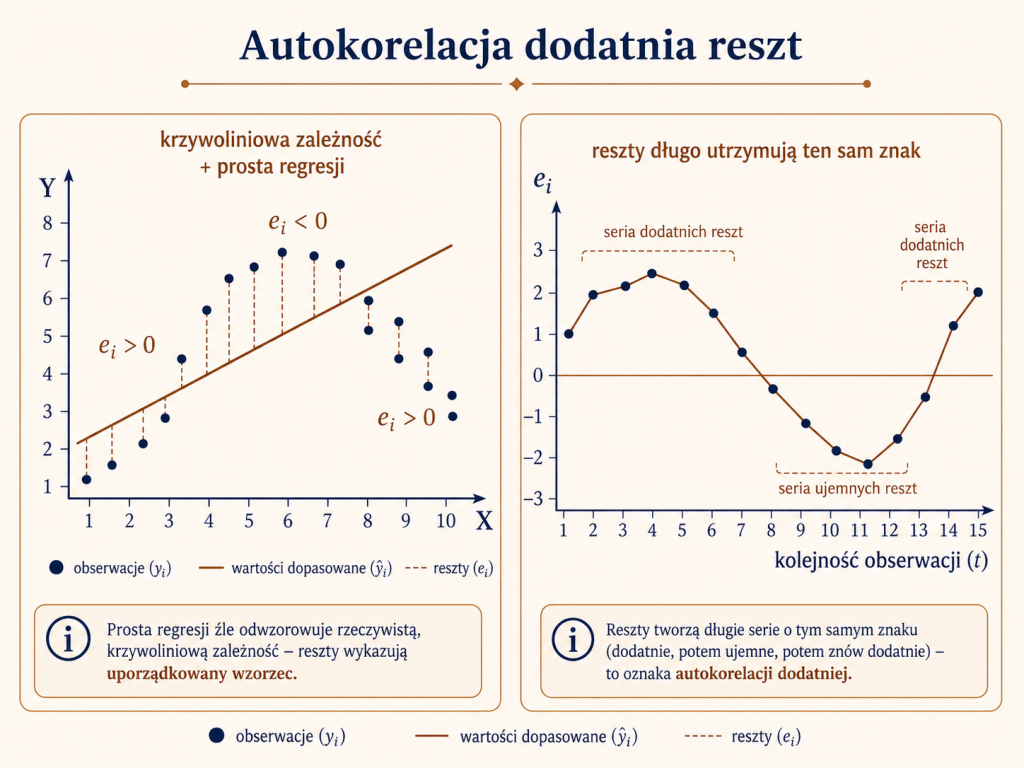
Autokorelacja dodatnia reszt
Autokorelacja dodatnia oznacza, że kolejne reszty mają tendencję do zachowywania tego samego znaku. Dodatnie reszty występują seriami, a potem przez pewien czas mogą dominować reszty ujemne. Można powiedzieć obrazowo, że reszty „niechętnie” zmieniają znak.
Taki układ może pojawić się na przykład wtedy, gdy rzeczywista zależność jest krzywoliniowa, a my na siłę dopasowujemy do niej prostą regresji. Wtedy model w jednych fragmentach systematycznie zawyża wartości, a w innych systematycznie je zaniża. Reszty przestają wyglądać losowo i zaczynają tworzyć uporządkowany wzorzec.
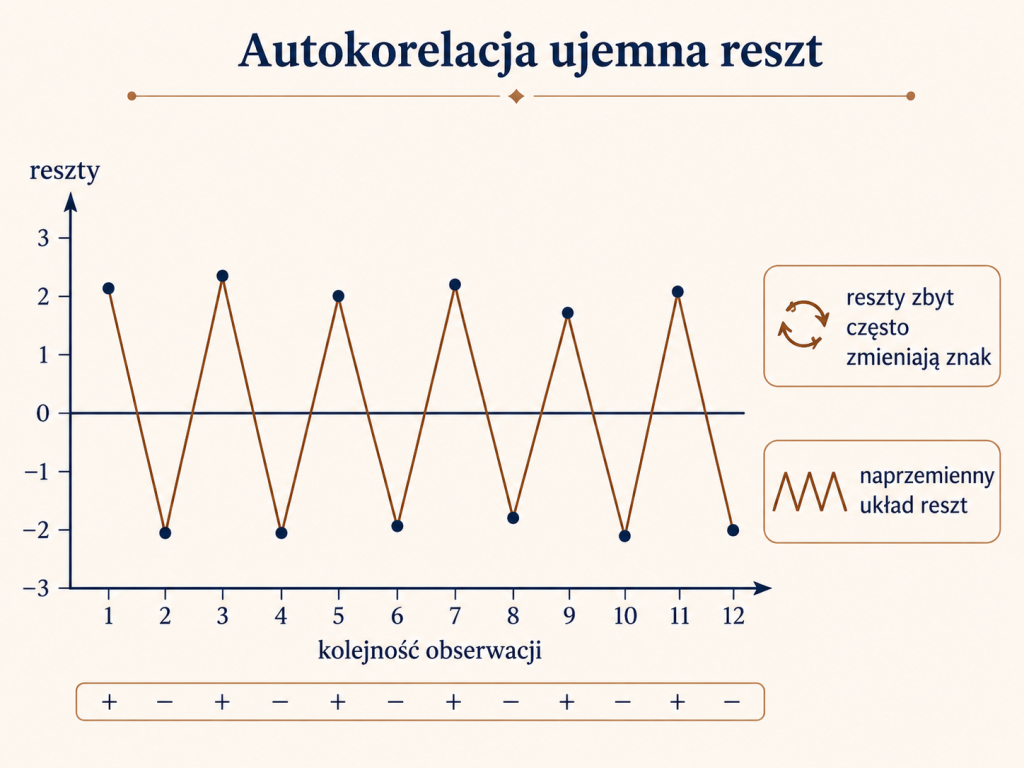
Autokorelacja ujemna reszt
Autokorelacja ujemna występuje wtedy, gdy reszty zbyt często zmieniają znak. Po reszcie dodatniej bardzo często pojawia się reszta ujemna, potem znów dodatnia, potem ujemna i tak dalej. Wykres reszt przyjmuje wtedy charakterystyczny zygzakowaty kształt.
Taki układ również nie jest pożądany, ponieważ reszty nie przypominają losowych odchyleń. Zamiast tego tworzą zbyt regularny, naprzemienny wzorzec. W praktyce może to świadczyć o błędnej specyfikacji modelu, nieodpowiednim uporządkowaniu danych albo o pominięciu istotnej struktury zależności.
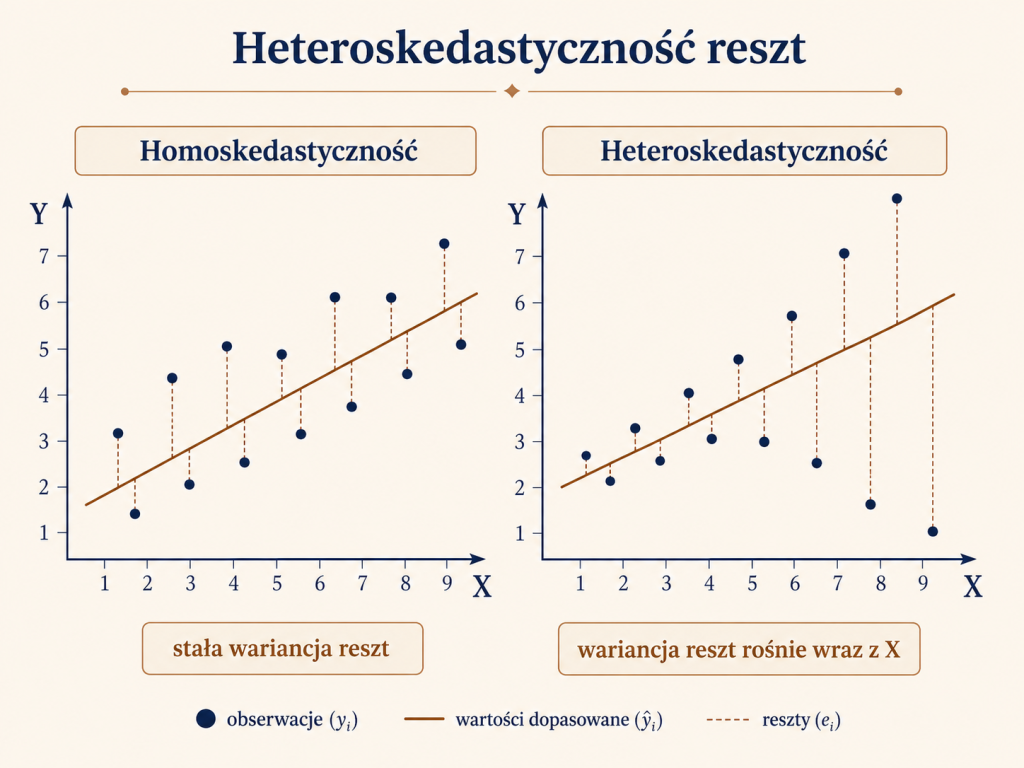
Heteroskedastyczność reszt
Innym częstym problemem jest heteroskedastyczność, czyli zmienna wariancja składnika losowego. W praktyce oznacza to, że rozrzut reszt nie jest jednakowy w całym zakresie obserwacji. Dla małych wartości zmiennej objaśniającej reszty mogą być niewielkie, a dla dużych wartości mogą coraz bardziej się „rozjeżdżać”.
Na wykresie heteroskedastyczność często przypomina lejek: na początku punkty znajdują się blisko prostej regresji, a później ich odległości od prostej stają się coraz większe. Taki układ narusza założenie stałej wariancji składnika losowego i może prowadzić do błędnej oceny precyzji parametrów.
Warto podkreślić, że autokorelacja i heteroskedastyczność nie należą już do samej estymacji parametrów metodą MNK, lecz do późniejszej weryfikacji modelu ekonometrycznego. W tym artykule pokazujemy je tylko intuicyjnie, ponieważ są bezpośrednio związane z założeniami, przy których metoda najmniejszych kwadratów ma najlepsze własności.
Twierdzenie Gaussa-Markowa
Twierdzenie Gaussa-Markowa mówi, że przy spełnieniu odpowiednich założeń klasycznego modelu liniowego estymator MNK jest najlepszym liniowym nieobciążonym estymatorem parametrów modelu.
Po angielsku własność tę określa się skrótem BLUE:
B — Best, czyli najlepszy w sensie najmniejszej wariancji,
L — Linear, czyli liniowy względem obserwacji zmiennej objaśnianej,
U — Unbiased, czyli nieobciążony,
E — Estimator, czyli estymator.
Nieobciążoność oznacza, że wartość oczekiwana estymatora jest równa prawdziwej wartości parametru:
$$E(\hat{\boldsymbol{\beta}}) = \boldsymbol{\beta}$$
Nie oznacza to, że w konkretnej próbie zawsze otrzymamy dokładnie prawdziwy parametr. Oznacza to raczej, że przy wielokrotnym losowaniu prób i wielokrotnym szacowaniu modelu estymator nie będzie systematycznie zawyżał ani zaniżał wartości parametru.
Określenie „najlepszy” w twierdzeniu Gaussa-Markowa nie oznacza najlepszego w każdym możliwym sensie. Chodzi o klasę estymatorów liniowych i nieobciążonych. W tej klasie estymator MNK ma najmniejszą wariancję, czyli jest najbardziej precyzyjny.
Twierdzenie Gaussa-Markowa jest jednym z powodów, dla których metoda najmniejszych kwadratów odgrywa tak ważną rolę w ekonometrii. Pokazuje ono, że przy spełnieniu określonych założeń MNK ma bardzo dobre własności teoretyczne.
Czego nie obejmuje sama metoda MNK?
Metoda najmniejszych kwadratów jest narzędziem estymacji parametrów. Nie rozwiązuje jednak wszystkich problemów związanych z budową modelu ekonometrycznego. Sama MNK nie odpowiada automatycznie na pytanie, czy wybrane zmienne są właściwe, czy model ma dobrą postać, czy dane są poprawne, czy występuje autokorelacja, heteroskedastyczność albo silna współliniowość.
Nie należy więc traktować MNK jako magicznego sposobu na „odkrycie prawdy” z danych. Jest to bardzo ważna metoda, ale jej wyniki muszą być interpretowane w kontekście założeń modelu, jakości danych oraz sensu merytorycznego badanej zależności.
Po oszacowaniu modelu konieczna jest jego weryfikacja. Sprawdza się między innymi istotność parametrów, dopasowanie modelu, własności reszt, zgodność znaków parametrów z teorią oraz ewentualne naruszenia założeń klasycznego modelu liniowego. Te zagadnienia wymagają osobnego omówienia.
Podsumowanie
Metoda najmniejszych kwadratów jest podstawową metodą estymacji parametrów liniowego modelu ekonometrycznego. Polega na takim dobraniu ocen parametrów, aby suma kwadratów reszt, czyli różnic między wartościami rzeczywistymi i teoretycznymi, była jak najmniejsza.
Najważniejsza idea polega na tym, że prawdziwych parametrów populacyjnego modelu zwykle nie znamy. Na podstawie próby wyznaczamy jedynie ich oszacowania. Dlatego symbole $\hat{\beta}_0, \hat{\beta}_1, \ldots, \hat{\beta}_k$ oznaczają oceny parametrów, a nie same parametry strukturalne modelu populacyjnego.
W modelu z jedną zmienną objaśniającą metoda najmniejszych kwadratów pozwala dopasować prostą regresji do chmury punktów. W modelu z dwiema zmiennymi dopasowywana jest płaszczyzna, a w modelu z większą liczbą zmiennych — hiperpłaszczyzna regresji. Uniwersalny zapis macierzowy metody ma postać:
$$\hat{\boldsymbol{\beta}} = (\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}$$
Metoda MNK jest szczególnie ważna ze względu na twierdzenie Gaussa-Markowa. Przy spełnieniu odpowiednich założeń estymator MNK jest najlepszym liniowym nieobciążonym estymatorem parametrów modelu. Nie oznacza to jednak, że każdy model oszacowany metodą MNK jest automatycznie dobry. Konieczna jest także weryfikacja modelu, ocena założeń oraz interpretacja wyników w świetle wiedzy merytorycznej.
W kolejnym artykule można przejść do zagadnień związanych z weryfikacją modelu ekonometrycznego, czyli między innymi oceną istotności parametrów, analizą reszt, testowaniem autokorelacji, heteroskedastyczności oraz sprawdzaniem jakości dopasowania modelu.
Utworzono: 16.05.2026 | Zmodyfikowano: 18.05.2026
Powiązane artykuły
- Model ekonometryczny — czym jest, do czego służy i jak go zbudować?
- Weryfikacja modelu ekonometrycznego
- Generator danych do modelu ekonometrycznego online
- Dobór zmiennych do modelu ekonometrycznego
- Dane przekrojowe, szeregi czasowe i dane panelowe w ekonometrii
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc