
Dane przekrojowe, szeregi czasowe i dane panelowe w ekonometrii
Wprowadzenie
W ekonometrii bardzo ważne jest nie tylko to, jakie zmienne wybieramy do modelu, ale również to, jakiego rodzaju dane analizujemy. Inaczej buduje się model dla obserwacji zebranych w jednym momencie dla wielu obiektów, inaczej dla danych uporządkowanych w czasie, a jeszcze inaczej dla danych, które łączą oba te wymiary.
Najczęściej wyróżnia się trzy podstawowe typy danych wykorzystywanych w modelach ekonometrycznych: dane przekrojowe, szeregi czasowe oraz dane panelowe. Każdy z tych typów danych ma własną specyfikę, własne zalety, ograniczenia oraz typowe problemy diagnostyczne.
W artykule wyjaśniamy, czym są dane przekrojowe, czym różnią się szeregi czasowe od danych przekrojowych, na czym polegają dane panelowe oraz dlaczego rodzaj danych ma wpływ na dobór zmiennych, estymację, weryfikację modelu i interpretację wyników.
Spis treści
- Dlaczego rodzaj danych ma znaczenie?
- Dane przekrojowe
- Przykłady danych przekrojowych
- Szeregi czasowe
- Przykłady szeregów czasowych
- Najważniejsze cechy szeregów czasowych
- Trend, sezonowość i wahania losowe
- Stacjonarność szeregu czasowego
- Autokorelacja w szeregach czasowych
- Dane panelowe
- Przykłady danych panelowych
- Panel zbilansowany i niezbilansowany
- Porównanie typów danych
- Jaki model dla jakich danych?
- Najczęstsze błędy przy interpretacji danych
- Podsumowanie
Dlaczego rodzaj danych ma znaczenie?
Rodzaj danych wpływa na sposób budowy modelu ekonometrycznego. Od tego zależy między innymi, jakie zmienne można wprowadzić do modelu, jakie założenia są szczególnie ważne, jakie testy diagnostyczne należy wykonać oraz jak interpretować parametry.
W przypadku danych przekrojowych interesują nas różnice między obiektami. W przypadku szeregów czasowych analizujemy zmiany badanego zjawiska w czasie. Dane panelowe łączą oba podejścia, ponieważ obserwujemy wiele obiektów w wielu okresach.
Przykładowo, jeżeli analizujemy ceny mieszkań w jednym roku w różnych miastach, mamy dane przekrojowe. Jeżeli analizujemy średnią cenę mieszkań w jednym mieście w kolejnych kwartałach, mamy szereg czasowy. Jeżeli analizujemy ceny mieszkań w wielu miastach przez wiele lat, mamy dane panelowe.
Ten podział jest bardzo ważny, ponieważ każdy typ danych niesie inne ryzyko błędów. W danych przekrojowych często pojawia się heteroskedastyczność. W szeregach czasowych szczególnie ważna jest autokorelacja, trend i stacjonarność. W danych panelowych dochodzi dodatkowo problem zróżnicowania obiektów i efektów indywidualnych.
Dane przekrojowe
Dane przekrojowe to dane dotyczące wielu obiektów obserwowanych w tym samym momencie lub w tym samym okresie. Obiektami mogą być osoby, gospodarstwa domowe, przedsiębiorstwa, banki, miasta, regiony, państwa, mieszkania, sklepy albo produkty.
W danych przekrojowych głównym źródłem zmienności są różnice między obiektami. Nie interesuje nas tutaj przede wszystkim to, jak jedno zjawisko zmienia się w czasie, ale to, dlaczego jedne obiekty różnią się od innych.
Przykładowy model dla danych przekrojowych może mieć postać:
$$Y_i = \beta_0 + \beta_1X_{1i} + \beta_2X_{2i} + \ldots + \beta_kX_{ki} + \varepsilon_i$$
gdzie indeks $i$ oznacza kolejne obiekty, na przykład osoby, firmy albo mieszkania.
Jeżeli badamy wynagrodzenia pracowników, zmienną objaśnianą $Y_i$ może być wynagrodzenie $i$-tej osoby, a zmiennymi objaśniającymi: staż pracy, wykształcenie, branża, stanowisko i region.
Przykłady danych przekrojowych
Do typowych przykładów danych przekrojowych należą:
dochody gospodarstw domowych w danym roku,
ceny mieszkań sprzedanych w wybranym kwartale,
wynagrodzenia pracowników w danym przedsiębiorstwie,
zyski przedsiębiorstw w jednym roku,
zadłużenie gmin w określonym momencie,
wyniki egzaminów uczniów z jednej sesji egzaminacyjnej,
wskaźniki finansowe banków dla jednego roku.
W danych przekrojowych bardzo ważne jest, aby obserwacje były porównywalne. Jeżeli zestawiamy bardzo różne obiekty, na przykład małe sklepy rodzinne i duże międzynarodowe korporacje, model może wymagać dodatkowych zmiennych kontrolnych albo podziału próby na bardziej jednorodne grupy.
Typowym problemem w danych przekrojowych jest heteroskedastyczność, czyli zmienna wariancja składnika losowego. Przykładowo błędy modelu mogą być większe dla dużych firm niż dla małych firm albo większe dla gospodarstw o wysokich dochodach niż dla gospodarstw o niskich dochodach.
Szeregi czasowe
Szereg czasowy to zbiór obserwacji tej samej zmiennej uporządkowanych w czasie. W przeciwieństwie do danych przekrojowych, gdzie analizujemy różnice między obiektami, w szeregach czasowych analizujemy zmiany danego zjawiska w kolejnych okresach.
Indeks obserwacji oznacza się zwykle literą $t$, która reprezentuje czas:
$$Y_t = \beta_0 + \beta_1X_{1t} + \beta_2X_{2t} + \ldots + \beta_kX_{kt} + \varepsilon_t$$
Szeregi czasowe mogą mieć różną częstotliwość. Mogą być dzienne, tygodniowe, miesięczne, kwartalne, roczne albo nawet godzinowe. Wybór częstotliwości ma duże znaczenie, ponieważ wpływa na liczbę obserwacji, widoczność sezonowości i charakter zależności między zmiennymi.
W szeregach czasowych szczególnie ważne jest to, że kolejność obserwacji nie jest przypadkowa. Obserwacja z jednego okresu może być powiązana z obserwacją z okresu poprzedniego. To właśnie dlatego w modelach szeregów czasowych tak często pojawia się problem autokorelacji.
Przykłady szeregów czasowych
Przykładami szeregów czasowych są:
miesięczna sprzedaż przedsiębiorstwa,
kwartalny produkt krajowy brutto,
roczna stopa bezrobocia,
dzienne kursy walut,
notowania akcji na giełdzie,
miesięczna inflacja,
liczba klientów sklepu internetowego w kolejnych tygodniach,
zużycie energii elektrycznej w kolejnych godzinach.
Przy analizie szeregów czasowych bardzo ważne jest uwzględnienie jednostki czasu. Inaczej interpretuje się dane roczne, a inaczej miesięczne lub dzienne. W danych miesięcznych często widoczna jest sezonowość, w danych finansowych mogą występować gwałtowne zmiany zmienności, a w danych makroekonomicznych często pojawia się trend długookresowy.
Najważniejsze cechy szeregów czasowych
Szeregi czasowe różnią się od danych przekrojowych kilkoma ważnymi cechami.
Po pierwsze, obserwacje są uporządkowane w czasie. Nie można ich dowolnie przestawiać bez utraty informacji. Kolejność obserwacji jest częścią danych.
Po drugie, w szeregach czasowych często występują zależności między kolejnymi obserwacjami. Dzisiejsza sprzedaż może być powiązana ze sprzedażą wczorajszą, a inflacja w tym miesiącu z inflacją w poprzednich miesiącach.
Po trzecie, wiele szeregów czasowych wykazuje trend, sezonowość, cykliczność albo zmiany poziomu zmienności. Oznacza to, że klasyczny model liniowy stosowany bezrefleksyjnie może prowadzić do błędnych wniosków.
Po czwarte, w szeregach czasowych pojawia się problem stacjonarności. Wiele metod statystycznych zakłada, że podstawowe własności szeregu nie zmieniają się w czasie. Jeżeli szereg jest niestacjonarny, konieczne może być jego przekształcenie albo zastosowanie specjalnych metod modelowania.
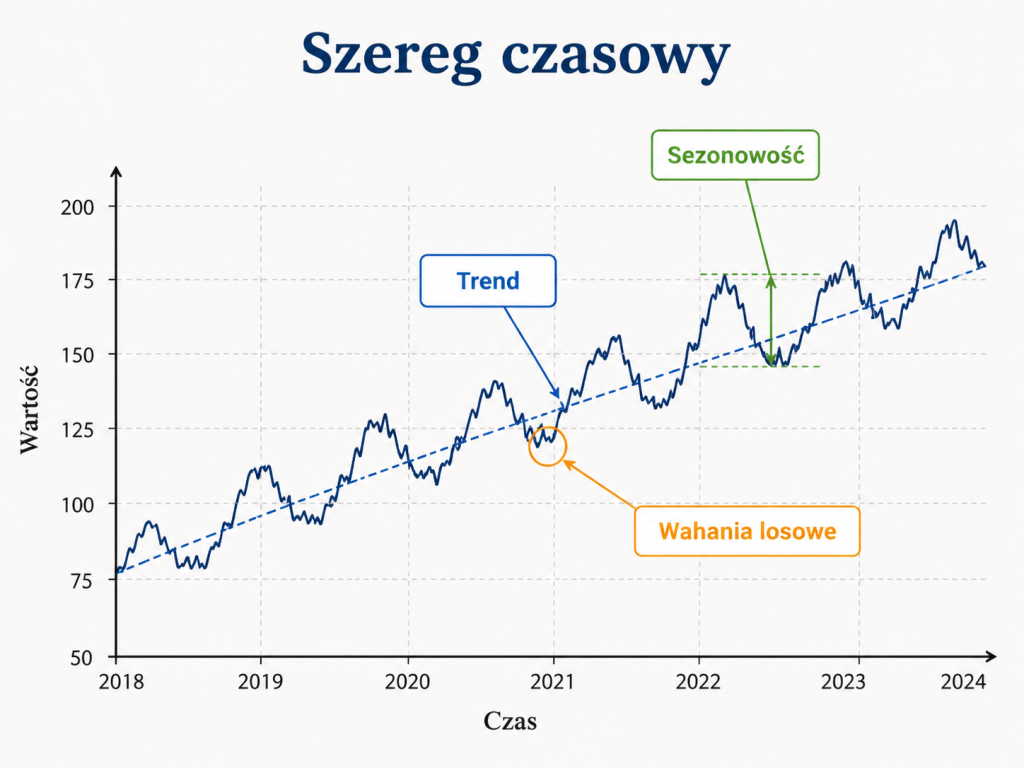
Trend, sezonowość i wahania losowe
W szeregach czasowych często wyróżnia się kilka składowych: trend, sezonowość, wahania cykliczne oraz wahania losowe.
Trend oznacza długookresową tendencję wzrostową lub spadkową. Przykładem może być wzrost przeciętnych wynagrodzeń w kolejnych latach albo wzrost liczby użytkowników usługi internetowej.
Sezonowość oznacza regularnie powtarzające się wahania w określonych porach roku, miesiącach, dniach tygodnia albo godzinach. Przykładowo sprzedaż lodów rośnie latem, sprzedaż opału zimą, a ruch w sklepie internetowym może zależeć od dnia tygodnia.
Wahania cykliczne są związane z dłuższymi okresami koniunktury i dekoniunktury. W ekonomii mogą dotyczyć cyklu gospodarczego, inwestycji, produkcji albo rynku pracy.
Wahania losowe to nieregularne odchylenia, których nie da się łatwo wyjaśnić trendem, sezonowością ani cyklem. W modelu ekonometrycznym część takich odchyleń trafia do składnika losowego.
Stacjonarność szeregu czasowego
Jednym z najważniejszych pojęć w analizie szeregów czasowych jest stacjonarność. Intuicyjnie szereg stacjonarny to taki, którego podstawowe własności nie zmieniają się w czasie. Jego średni poziom, zmienność i struktura zależności pozostają względnie stabilne.
Jeżeli szereg ma wyraźny trend wzrostowy albo spadkowy, zwykle nie jest stacjonarny. Jeżeli jego wariancja rośnie w czasie, również może być niestacjonarny. Wiele szeregów ekonomicznych, takich jak PKB, ceny, dochody czy podaż pieniądza, wykazuje niestacjonarność.
Niestacjonarność jest problemem, ponieważ może prowadzić do pozornych zależności. Dwie zmienne mogą rosnąć w czasie i wykazywać wysoką korelację, choć w rzeczywistości nie istnieje między nimi sensowny związek przyczynowy. Jest to jeden z powodów, dla których w analizie szeregów czasowych trzeba zachować szczególną ostrożność.
W praktyce do badania stacjonarności stosuje się specjalne testy, na przykład test Dickeya-Fullera lub jego rozszerzoną wersję ADF. Szczegółowe omówienie tych testów wymaga osobnego artykułu poświęconego modelowaniu szeregów czasowych.
Autokorelacja w szeregach czasowych
W szeregach czasowych często występuje autokorelacja, czyli zależność obserwacji od jej wcześniejszych wartości. Jeżeli wartość zmiennej w okresie $t$ jest powiązana z wartością w okresie $t-1$, mówimy o autokorelacji pierwszego rzędu.
Autokorelacja może dotyczyć samej zmiennej, ale w klasycznej diagnostyce modelu ekonometrycznego szczególnie ważna jest autokorelacja reszt. Jeżeli reszty są skorelowane w czasie, oznacza to, że model nie uchwycił pewnej struktury zależności.
W artykule o weryfikacji modelu ekonometrycznego omawialiśmy między innymi test Durbina-Watsona oraz test Breuscha-Godfreya. Są to narzędzia pozwalające sprawdzić, czy w resztach modelu występuje autokorelacja.
W praktyce autokorelacja jest jednym z najważniejszych powodów, dla których modelowanie szeregów czasowych wymaga innych narzędzi niż proste modele przekrojowe. Czasami konieczne jest dodanie opóźnionych zmiennych, składników autoregresyjnych, trendu, sezonowości albo zastosowanie modeli specjalnie zaprojektowanych dla szeregów czasowych.
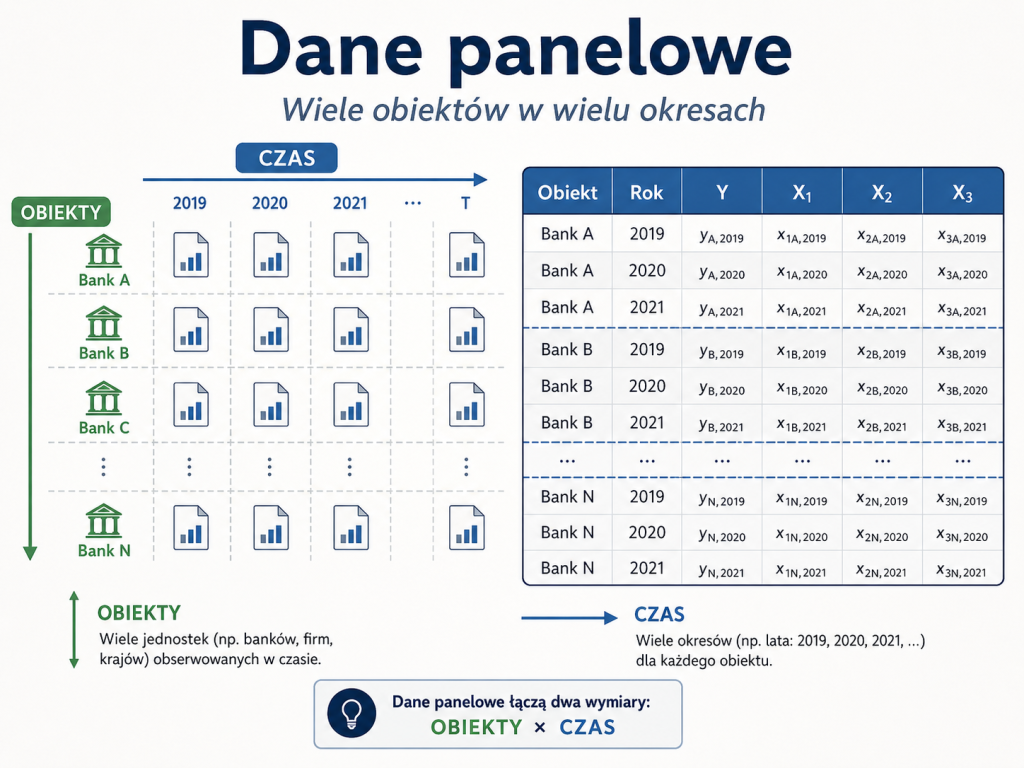
Dane panelowe
Dane panelowe łączą cechy danych przekrojowych i szeregów czasowych. Oznacza to, że obserwujemy wiele obiektów w wielu okresach. Każdy obiekt ma więc własny mini-szereg czasowy, a jednocześnie w każdym okresie możemy porównywać różne obiekty między sobą.
Przykładowy zapis modelu panelowego może wyglądać następująco:
$$Y_{it} = \beta_0 + \beta_1X_{1it} + \beta_2X_{2it} + \ldots + \beta_kX_{kit} + \varepsilon_{it}$$
gdzie indeks $i$ oznacza obiekt, na przykład firmę, bank, gospodarstwo domowe albo państwo, a indeks $t$ oznacza czas.
Dane panelowe są bardzo cenne, ponieważ pozwalają analizować jednocześnie zróżnicowanie między obiektami oraz zmiany w czasie. Dzięki temu często można lepiej kontrolować cechy obiektów, których nie obserwujemy bezpośrednio, ale które są względnie stałe w czasie.
Przykłady danych panelowych
Przykładami danych panelowych są:
dane o wielu bankach obserwowanych w latach 2015 – 2025,
dane o przedsiębiorstwach obserwowanych przez kilka kolejnych lat,
dane o gospodarstwach domowych badanych w kolejnych falach ankiety,
dane o regionach i ich stopie bezrobocia w kolejnych kwartałach,
dane o państwach i ich wskaźnikach makroekonomicznych w wielu latach,
dane o szkołach i wynikach egzaminacyjnych uczniów w kolejnych rocznikach.
Załóżmy, że analizujemy rentowność banków. Dla każdego banku mamy dane z kolejnych lat: zysk netto, aktywa, kapitał własny, wynik odsetkowy, kredyty zagrożone i koszty operacyjne. Taki zbiór danych jest panelem, ponieważ zawiera zarówno wymiar przekrojowy, czyli różne banki, jak i wymiar czasowy, czyli kolejne lata.
Panel zbilansowany i niezbilansowany
W danych panelowych wyróżnia się panel zbilansowany i niezbilansowany.
Panel zbilansowany występuje wtedy, gdy dla każdego obiektu mamy obserwacje dla tych samych okresów. Jeżeli badamy 10 banków w latach 2015 – 2025 i dla każdego banku mamy komplet danych za każdy rok, jest to panel zbilansowany.
Panel niezbilansowany występuje wtedy, gdy dla niektórych obiektów brakuje obserwacji w części okresów. Przykładowo jeden bank może mieć dane od 2015 roku, drugi od 2017 roku, a trzeci może mieć brak danych za 2020 rok.
Panel niezbilansowany jest bardzo częsty w praktyce. Braki danych mogą wynikać ze zmian metodologii, fuzji przedsiębiorstw, wejścia lub wyjścia obiektów z rynku, braku publikacji sprawozdań albo różnic w dostępności danych.
Przy pracy z danymi panelowymi trzeba dokładnie sprawdzić strukturę danych. Nie wystarczy wiedzieć, ile mamy wierszy w tabeli. Trzeba jeszcze wiedzieć, ile jest obiektów, ile okresów, czy panel jest zbilansowany oraz czy braki danych mają charakter przypadkowy.
Porównanie typów danych
Różnice między danymi przekrojowymi, szeregami czasowymi i danymi panelowymi można podsumować w tabeli.
| Typ danych | Co obserwujemy? | Główne źródło zmienności | Przykład | Typowe problemy |
|---|---|---|---|---|
| Dane przekrojowe | Wiele obiektów w jednym okresie | Różnice między obiektami | Ceny mieszkań w 2025 roku | Heteroskedastyczność, różnice skali, obserwacje odstające |
| Szereg czasowy | Jeden obiekt lub jedno zjawisko w wielu okresach | Zmiany w czasie | Miesięczna sprzedaż firmy | Trend, sezonowość, autokorelacja, niestacjonarność |
| Dane panelowe | Wiele obiektów w wielu okresach | Różnice między obiektami i zmiany w czasie | Wyniki finansowe banków w latach 2015 – 2025 | Efekty indywidualne, braki danych, autokorelacja, heteroskedastyczność |
Ten sam problem badawczy może wyglądać zupełnie inaczej w zależności od rodzaju danych. Analiza cen mieszkań w jednym mieście w kolejnych latach jest szeregiem czasowym. Analiza cen mieszkań w wielu miastach w jednym roku jest analizą przekrojową. Analiza cen mieszkań w wielu miastach w kolejnych latach ma charakter panelowy.
Jaki model dla jakich danych?
Rodzaj danych wpływa na wybór modelu ekonometrycznego i metod diagnostycznych.
Dla danych przekrojowych często stosuje się klasyczne modele regresji liniowej, modele logitowe, probitowe, modele dla danych jakościowych albo modele z odpornymi błędami standardowymi. Szczególną uwagę zwraca się na heteroskedastyczność, obserwacje odstające i poprawny dobór zmiennych objaśniających.
Dla szeregów czasowych stosuje się modele z trendem, sezonowością, opóźnieniami, modele autoregresyjne, modele ARIMA, modele VAR, modele korekty błędem oraz inne narzędzia analizy dynamicznej. Ważna jest stacjonarność, autokorelacja, opóźnienia i struktura czasowa zależności.
Dla danych panelowych stosuje się między innymi modele z efektami stałymi, modele z efektami losowymi oraz różne rozszerzenia uwzględniające autokorelację, heteroskedastyczność i zależności między obiektami. Dane panelowe pozwalają często kontrolować nieobserwowalne cechy obiektów, które są stałe w czasie.
Na poziomie wprowadzającym najważniejsze jest zrozumienie, że nie każdy zbiór danych można analizować w ten sam sposób. To, czy mamy dane przekrojowe, szereg czasowy czy panel, powinno być ustalone już na początku budowy modelu.
Najczęstsze błędy przy interpretacji danych
Jednym z częstych błędów jest traktowanie szeregu czasowego tak, jakby był zwykłym zbiorem niezależnych obserwacji. Jeżeli pominiemy kolejność czasu, możemy przeoczyć trend, sezonowość, autokorelację albo zmianę strukturalną.
Drugim błędem jest ignorowanie różnic między obiektami w danych panelowych. Jeżeli porównujemy wiele firm, banków albo państw, trzeba pamiętać, że mogą one różnić się cechami, których nie obserwujemy bezpośrednio. Te cechy mogą wpływać na wyniki modelu.
Trzecim błędem jest nadmierne zaufanie do wysokiej korelacji w szeregach czasowych. Dwie zmienne mogą rosnąć w czasie i wykazywać silny związek statystyczny tylko dlatego, że obie mają trend. Taka zależność może być pozorna.
Czwartym błędem jest mieszanie danych o różnej częstotliwości bez odpowiedniego przygotowania. Jeżeli jedna zmienna jest miesięczna, a druga roczna, trzeba zdecydować, jak je sprowadzić do wspólnej częstotliwości i jakie konsekwencje ma taka operacja.
Piątym błędem jest nieuwzględnienie celu modelu. Inaczej dobiera się dane do modelu opisowego, inaczej do modelu przyczynowego, a jeszcze inaczej do modelu prognostycznego. Rodzaj danych musi być zgodny z pytaniem badawczym.
Podsumowanie
Dane przekrojowe, szeregi czasowe i dane panelowe to trzy podstawowe typy danych wykorzystywanych w ekonometrii. Różnią się one strukturą, sposobem interpretacji oraz typowymi problemami, które pojawiają się podczas budowy i weryfikacji modelu.
Dane przekrojowe opisują wiele obiektów w jednym okresie. Szeregi czasowe opisują jedno zjawisko w kolejnych okresach. Dane panelowe łączą oba podejścia, ponieważ obejmują wiele obiektów obserwowanych w wielu okresach.
W danych przekrojowych szczególną uwagę zwraca się na różnice między obiektami, heteroskedastyczność i obserwacje odstające. W szeregach czasowych ważne są trend, sezonowość, autokorelacja i stacjonarność. W danych panelowych dochodzi dodatkowo problem efektów indywidualnych, braków danych oraz łączenia wymiaru przekrojowego z czasowym.
Rozpoznanie rodzaju danych powinno nastąpić przed doborem zmiennych, estymacją i weryfikacją modelu. Od tego zależy, jakie metody będą właściwe i jakie wnioski można bezpiecznie wyciągnąć z modelu ekonometrycznego.
W kolejnych artykułach można rozwinąć osobno modele szeregów czasowych, modele panelowe oraz praktyczne problemy przygotowania danych do analizy ekonometrycznej.
Utworzono: 16.05.2026 | Zmodyfikowano: 18.05.2026
Powiązane artykuły
- Model ekonometryczny — czym jest, do czego służy i jak go zbudować?
- Dobór zmiennych do modelu ekonometrycznego
- Generator danych do modelu ekonometrycznego online
- Metoda najmniejszych kwadratów — estymacja parametrów modelu ekonometrycznego
- Weryfikacja modelu ekonometrycznego
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc