
Rodzaje danych statystycznych: zmienne jakościowe, skokowe i ciągłe
Każda analiza statystyczna zaczyna się od prostego pytania: z jakim rodzajem danych mamy do czynienia? Od odpowiedzi zależy dobór wykresów, miar statystycznych, metod obliczeniowych, a nawet sposób rozumienia prawdopodobieństwa.
Na pierwszy rzut oka dane to po prostu liczby, kategorie albo odpowiedzi zebrane w ankiecie. W praktyce jednak nie wszystkie dane wolno analizować w ten sam sposób. Inaczej traktujemy kolor samochodu, inaczej ocenę z egzaminu, inaczej liczbę klientów w sklepie, a jeszcze inaczej temperaturę za oknem.
W tym artykule uporządkujemy podstawowe rodzaje danych statystycznych. Szczególną uwagę poświęcimy różnicy między zmienną skokową a zmienną ciągłą, ponieważ jest to jedno z najważniejszych rozróżnień w statystyce i rachunku prawdopodobieństwa.

Podstawowy podział danych statystycznych
W najprostszym ujęciu dane statystyczne można podzielić na jakościowe i ilościowe. Dane jakościowe opisują cechy, typy lub kategorie. Dane ilościowe opisują wielkości liczbowe, które można mierzyć albo zliczać.
Najczęściej wyróżnia się cztery podstawowe grupy danych:
- dane jakościowe nominalne,
- dane jakościowe porządkowe,
- dane ilościowe skokowe,
- dane ilościowe ciągłe.
Ten podział nie jest tylko akademicką klasyfikacją. Ma on bardzo praktyczne znaczenie. Od rodzaju danych zależy na przykład, czy sensownie jest obliczać średnią, czy lepiej użyć mediany, czy można zastosować histogram, a także jaki model probabilistyczny będzie odpowiedni.
Dane jakościowe nominalne
Dane jakościowe nominalne opisują przynależność obserwacji do pewnej kategorii. Kategorie te nie mają naturalnego porządku. Możemy je nazwać, zliczyć i porównać liczebności, ale nie możemy powiedzieć, że jedna kategoria jest większa albo mniejsza od drugiej.
Przykładami danych nominalnych są:
- kolor samochodu,
- województwo zamieszkania,
- branża działalności gospodarczej,
- marka telefonu,
- typ szkoły,
- forma płatności wybrana przez klienta.
Jeżeli takie kategorie zostaną zakodowane liczbami, na przykład 1, 2, 3, to liczby te są tylko etykietami. Kod „3” nie oznacza kategorii większej od kategorii oznaczonej kodem „1”. Z tego powodu nie ma sensu obliczanie średniej z numerów przypisanych kolorom albo województwom.
Dane jakościowe porządkowe
Dane jakościowe porządkowe również opisują kategorie, ale tym razem kategorie te można ustawić w naturalnej kolejności. Wiemy, że jedna odpowiedź oznacza poziom wyższy lub niższy od innej.
Przykładami danych porządkowych są:
- ocena z egzaminu: niedostateczny, dostateczny, dobry, bardzo dobry,
- poziom satysfakcji: niski, średni, wysoki,
- odpowiedzi ankietowe: zdecydowanie nie, raczej nie, trudno powiedzieć, raczej tak, zdecydowanie tak,
- poziom ryzyka: małe, umiarkowane, duże.
W danych porządkowych ważna jest kolejność, ale nie zawsze można zakładać, że odległości między kolejnymi kategoriami są jednakowe. Różnica między oceną dostateczną a dobrą nie musi oznaczać tego samego, co różnica między oceną dobrą a bardzo dobrą.
Dlatego przy danych porządkowych trzeba ostrożnie interpretować średnie arytmetyczne. Często bardziej naturalne są: mediana, dominanta, rozkład odpowiedzi oraz wykresy słupkowe.
Dane ilościowe
Dane ilościowe opisują wielkości liczbowe. Można je mierzyć, zliczać, porównywać oraz wykonywać na nich działania arytmetyczne. W tej grupie szczególnie ważny jest podział na dane skokowe i ciągłe.
Różnica między nimi może wydawać się subtelna, ale ma zasadnicze znaczenie dla rachunku prawdopodobieństwa. Zmienną skokową opisujemy za pomocą prawdopodobieństw przypisanych konkretnym wartościom. Zmienną ciągłą opisujemy za pomocą gęstości, a prawdopodobieństwa dotyczą przedziałów.
Skala interwałowa i skala ilorazowa
Przy danych ilościowych warto zwrócić uwagę jeszcze na jedno bardzo ważne rozróżnienie: skalę interwałową i skalę ilorazową. Obie skale pozwalają wykonywać działania na liczbach, ale nie wszystkie działania mają w nich taką samą interpretację.
Skala interwałowa to taka skala, w której sens mają przede wszystkim interwały, czyli różnice między wartościami. Możemy powiedzieć, że jedna wartość jest o określoną liczbę jednostek większa lub mniejsza od drugiej. Nie możemy jednak sensownie interpretować ilorazu dwóch wartości, ponieważ punkt zerowy skali jest umowny.
Klasycznym przykładem jest temperatura w skali Celsjusza. Temperatura 20°C jest o 10 stopni wyższa niż temperatura 10°C. Taka różnica ma sens. Nie można jednak powiedzieć, że 20°C oznacza temperaturę „dwa razy większą” niż 10°C. Zero stopni Celsjusza nie oznacza braku temperatury, lecz jest umownie przyjętym punktem związanym z zamarzaniem wody.
W skali interwałowej sensowne są więc porównania typu „o ile więcej?” albo „o ile mniej?”. Nie są natomiast poprawne porównania typu „ile razy więcej?”. Podobny charakter mają na przykład lata kalendarzowe. Rok 2000 jest o 100 lat późniejszy niż rok 1900, ale nie oznacza to, że jest „około 1,05 razy większy” w sensie merytorycznym.
Skala ilorazowa jest mocniejsza. W tej skali sens mają nie tylko różnice, ale również ilorazy. Oznacza to, że można poprawnie powiedzieć zarówno, że jedna wartość jest o określoną liczbę jednostek większa od drugiej, jak i że jest na przykład dwa razy większa.
Przykładem zmiennej mierzonej w skali ilorazowej jest długość, masa, czas trwania, liczba klientów albo liczba sprzedanych produktów. Jeżeli jeden przedmiot ma masę 20 kg, a drugi 10 kg, to pierwszy jest nie tylko o 10 kg cięższy, ale także dwa razy cięższy. To „dwa razy” ma tutaj rzeczywisty sens, ponieważ zero kilogramów oznacza brak masy.
Podobnie, jeśli jedno zadanie trwało 20 minut, a drugie 10 minut, to pierwsze trwało dwa razy dłużej. W przypadku liczby klientów 20 klientów to również dwa razy więcej niż 10 klientów. Skala ilorazowa ma zatem naturalne zero, które oznacza brak mierzonej wielkości.
| Rodzaj skali | Co można sensownie interpretować? | Przykład | Na co uważać? |
|---|---|---|---|
| Skala interwałowa | Różnice między wartościami | Temperatura w °C, rok kalendarzowy | Ilorazy nie mają sensu, bo zero jest umowne |
| Skala ilorazowa | Różnice i ilorazy między wartościami | Masa, długość, czas trwania, liczba klientów | Zero oznacza rzeczywisty brak mierzonej wielkości |
To rozróżnienie ma znaczenie także przy doborze miar statystycznych. Średnią i odchylenie standardowe można sensownie interpretować już dla wielu zmiennych interwałowych, ale miary oparte na ilorazach, takie jak współczynnik zmienności, wymagają zwykle skali ilorazowej. Trzeba więc pytać nie tylko o to, czy zmienna jest jakościowa czy ilościowa, ale również o to, w jakiej skali została zmierzona.
Zmienna skokowa
Zmienna skokowa przyjmuje wartości należące do zbioru skończonego albo przeliczalnego. Oznacza to, że możliwe wartości można wypisać kolejno, nawet jeśli jest ich nieskończenie wiele.
Przykładami zmiennych skokowych są:
- liczba dzieci w rodzinie,
- liczba klientów w sklepie w ciągu dnia,
- liczba błędów w tekście,
- wynik rzutu kostką,
- liczba zgłoszeń serwisowych w miesiącu,
- liczba awarii maszyny w ciągu roku.
W przypadku zmiennej skokowej można mówić o prawdopodobieństwie przyjęcia konkretnej wartości. Jeżeli \(X\) oznacza wynik rzutu uczciwą kostką, to:
\[ P(X=1)=\frac{1}{6}, \quad P(X=2)=\frac{1}{6}, \quad \ldots, \quad P(X=6)=\frac{1}{6} \]
Zmienną skokową opisuje funkcja prawdopodobieństwa, czyli funkcja przypisująca każdej możliwej wartości odpowiednie prawdopodobieństwo:
\[ p(x_i)=P(X=x_i) \]
Prawdopodobieństwa wszystkich możliwych wartości muszą sumować się do jedności:
\[ \sum_i P(X=x_i)=1 \]
Nie oznacza to jednak, że zmienna skokowa musi mieć tylko skończoną liczbę możliwych wartości. Przykładem zmiennej skokowej o nieskończonej liczbie wartości jest zmienna o rozkładzie Poissona. Może ona przyjmować wartości:
\[ 0,1,2,3,\ldots \]
Takich wartości jest nieskończenie wiele, ale nadal można je uporządkować i kolejno wypisać. Dlatego mówimy, że zbiór wartości jest przeliczalny.
Zmienna ciągła
Zmienna ciągła może przyjmować dowolne wartości z pewnego przedziału. Nie ogranicza się do oddzielnych punktów, takich jak 0, 1, 2 albo 3. Między dwiema różnymi wartościami zawsze można wskazać kolejne wartości pośrednie.
Przykładami zmiennych ciągłych są:
- temperatura,
- wzrost,
- masa ciała,
- czas wykonania zadania,
- długość elementu,
- prędkość,
- dochód traktowany jako wielkość mierzona z dużą dokładnością.
W przypadku zmiennej ciągłej pojawia się bardzo ważna własność: prawdopodobieństwo przyjęcia jednej, dokładnie określonej wartości jest równe zero:
\[ P(X=a)=0 \]
Na początku brzmi to zaskakująco. Przecież w życiu codziennym mówimy, że temperatura wynosi 20°C, ktoś ma 180 cm wzrostu albo zadanie zostało wykonane w 10 minut. Statystyka matematyczna wymaga jednak większej precyzji.
Dlaczego prawdopodobieństwo dokładnie 20°C jest równe zero?
Wyobraźmy sobie idealny termometr, który pokazuje temperaturę z nieskończoną dokładnością, czyli z nieskończenie wieloma cyframi po przecinku. Wtedy wartość dokładnie równa 20°C oznaczałaby:
\[ 20{,}000000000000000\ldots \]
W modelu ciągłym prawdopodobieństwo trafienia dokładnie w tę jedną wartość jest równe zero. Nie oznacza to, że temperatura „nie może” wynosić 20°C w sensie potocznym. Oznacza to tylko, że pojedynczy punkt na osi liczbowej nie ma dodatniej masy prawdopodobieństwa.
W praktyce, kiedy mówimy „jest 20 stopni”, zwykle mamy na myśli wynik zaokrąglony. Jeśli termometr pokazuje pełne stopnie, to odczyt 20°C może odpowiadać na przykład temperaturom z przedziału:
\[ 19{,}5 \leq X < 20{,}5 \]
Wtedy zachodzą jednocześnie dwie rzeczy:
\[ P(X=20)=0 \]
oraz
\[ P(19{,}5 \leq X < 20{,}5)>0 \]
To bardzo ważna intuicja: dla zmiennej ciągłej sensownie pytamy nie o prawdopodobieństwo jednej dokładnej wartości, lecz o prawdopodobieństwo znalezienia się w określonym przedziale.
Uwaga praktyczna
W rzeczywistych badaniach wiele zmiennych ciągłych zapisujemy z ograniczoną dokładnością. Wzrost podajemy w centymetrach, temperaturę często w pełnych stopniach albo z jedną cyfrą po przecinku, a czas w sekundach lub minutach. Taki zapis może sprawiać wrażenie, że zmienna jest skokowa. Trzeba jednak odróżnić naturę zmiennej od sposobu jej pomiaru i zapisu.
Temperatura jest zmienną ciągłą, nawet jeśli termometr pokazuje ją z dokładnością do jednego stopnia. Liczba klientów w sklepie jest natomiast zmienną skokową, ponieważ klientów można zliczać tylko jako 0, 1, 2, 3 i tak dalej.
Gęstość prawdopodobieństwa
Dla zmiennej skokowej poszczególnym wartościom przypisujemy prawdopodobieństwa. Dla zmiennej ciągłej nie da się tego zrobić w taki sam sposób, ponieważ pojedyncze punkty mają prawdopodobieństwo równe zero. Zamiast funkcji prawdopodobieństwa używamy wtedy gęstości prawdopodobieństwa.
Gęstość oznaczamy zwykle symbolem \(f(x)\). Musi ona spełniać dwa podstawowe warunki:
\[ f(x)\geq 0 \]
oraz
\[ \int_{-\infty}^{\infty} f(x)\,dx=1 \]
Pierwszy warunek oznacza, że gęstość nie może być ujemna. Drugi mówi, że całkowite prawdopodobieństwo, czyli całe pole pod wykresem gęstości, musi być równe 1.
Prawdopodobieństwo, że zmienna ciągła znajdzie się w przedziale od \(a\) do \(b\), obliczamy za pomocą całki:
\[ P(a\leq X\leq b)=\int_a^b f(x)\,dx \]
Innymi słowy, prawdopodobieństwo odpowiada polu pod wykresem gęstości na danym przedziale.
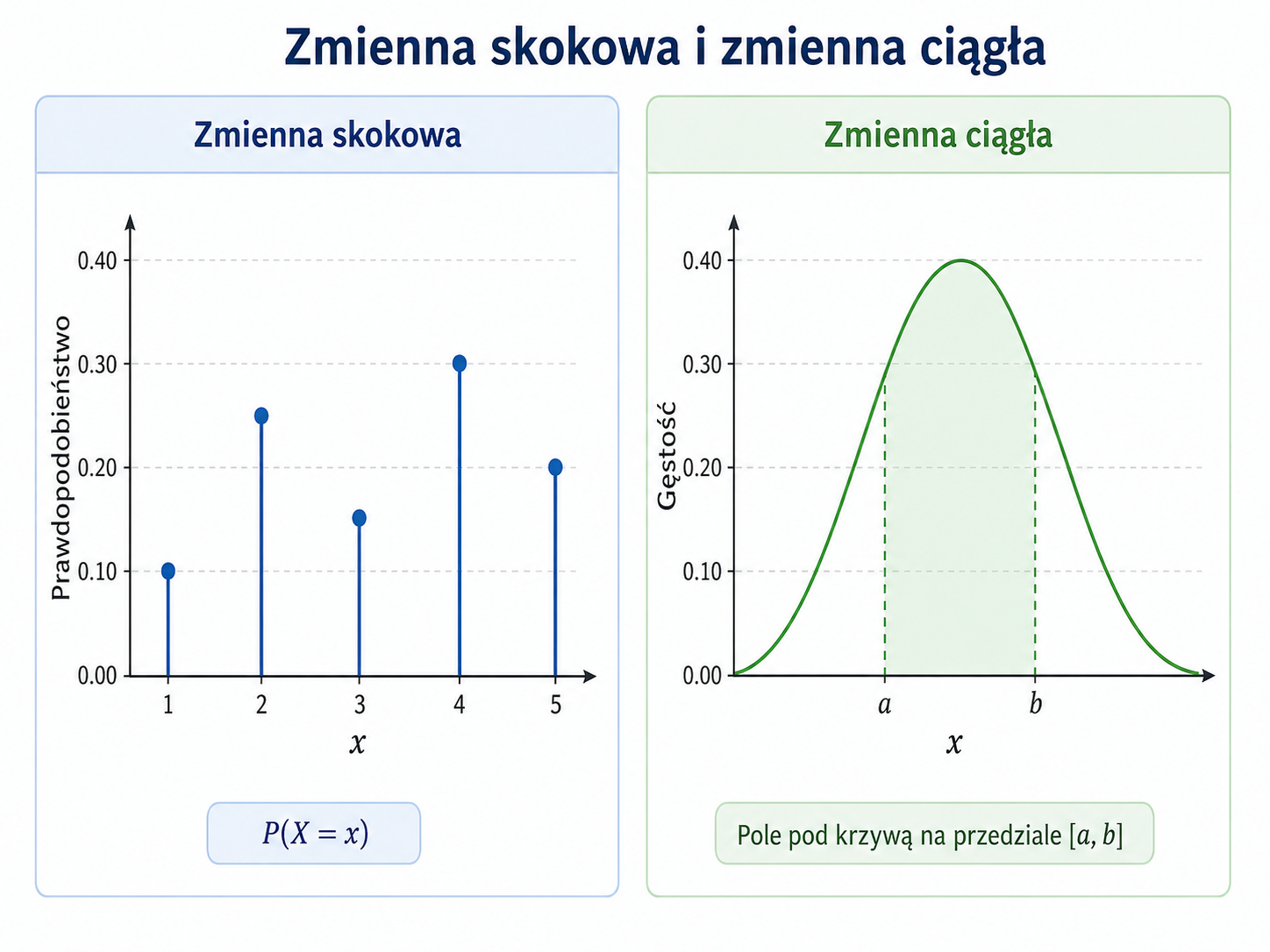
Porównanie zmiennej skokowej i ciągłej
Najważniejsze różnice między zmienną skokową a ciągłą można zebrać w krótkiej tabeli.
| Cecha | Zmienna skokowa | Zmienna ciągła |
|---|---|---|
| Charakter wartości | Oddzielne wartości, które można wypisać | Dowolne wartości z pewnego przedziału |
| Typowy przykład | Liczba klientów, liczba błędów, wynik rzutu kostką | Temperatura, czas, wzrost, masa |
| Zbiór wartości | Skończony albo przeliczalny | Zwykle nieprzeliczalny przedział liczb rzeczywistych |
| Prawdopodobieństwo jednej wartości | Może być dodatnie, np. \(P(X=3)>0\) | Jest równe zero, czyli \(P(X=a)=0\) |
| Podstawowy opis | Funkcja prawdopodobieństwa | Gęstość prawdopodobieństwa |
| Warunek unormowania | \(\sum_i P(X=x_i)=1\) | \(\int_{-\infty}^{\infty} f(x)\,dx=1\) |
| Typowy wykres | Słupki prawdopodobieństw | Krzywa gęstości |
Rodzaj danych a dobór miar statystycznych
Rodzaj danych ma bezpośredni wpływ na to, jakie miary statystyczne można sensownie zastosować. Nie każdą miarę da się obliczyć dla każdego typu zmiennej, a nawet jeśli technicznie jest to możliwe po zakodowaniu danych liczbami, wynik może nie mieć poprawnej interpretacji.
Dla zmiennych nominalnych, takich jak kolor produktu albo województwo, sensowne są przede wszystkim liczebności, udziały procentowe i dominanta. Nie ma natomiast sensu obliczanie średniej arytmetycznej z nazw kategorii ani ze sztucznie przypisanych im numerów.
Dla zmiennych porządkowych można dodatkowo analizować kolejność odpowiedzi, medianę oraz rozkład wskazań. Nadal jednak trzeba ostrożnie podchodzić do średniej, ponieważ różnice między kolejnymi kategoriami nie zawsze są jednakowe.
Najszerszy zakres klasycznych miar statystycznych stosuje się dla zmiennych ilościowych. Wtedy można mówić między innymi o średniej, wariancji, odchyleniu standardowym, kwartylach, minimum, maksimum czy współczynniku zmienności.
| Rodzaj danych | Przykłady sensownych miar | Na co uważać? |
|---|---|---|
| Dane nominalne | Liczebności, udziały procentowe, dominanta | Nie obliczamy średniej z nazw kategorii ani ze sztucznych kodów liczbowych |
| Dane porządkowe | Liczebności, udziały, dominanta, mediana, kwartyle | Średnia bywa stosowana w praktyce, ale wymaga ostrożnej interpretacji |
| Dane ilościowe interwałowe | Średnia, mediana, wariancja, odchylenie standardowe | Sens mają różnice, ale nie ilorazy; ostrożnie z porównaniami typu „dwa razy więcej” |
| Dane ilościowe ilorazowe | Średnia, mediana, wariancja, odchylenie standardowe, rozstęp, współczynnik zmienności | Ilorazy mają sens, ponieważ istnieje naturalne zero oznaczające brak mierzonej wielkości |
Dlatego przed obliczeniem średniej, wariancji czy odchylenia standardowego trzeba najpierw zapytać, z jakim typem zmiennej mamy do czynienia. Ten temat prowadzi naturalnie do kolejnego zagadnienia: podziału miar statystycznych i zasad ich poprawnego stosowania.
Dystrybuanta, czyli wspólny język opisu
Zarówno zmienne skokowe, jak i ciągłe można opisywać za pomocą dystrybuanty. Jest to funkcja, która informuje, z jakim prawdopodobieństwem zmienna losowa przyjmie wartość nie większą od danej liczby.
Najczęściej współcześnie dystrybuantę definiuje się następująco:
\[ F(x)=P(X\leq x) \]
W starszej literaturze można jednak spotkać także definicję:
\[ F(x)=P(X<x) \]
Dla zmiennej ciągłej różnica między tymi definicjami nie ma praktycznego znaczenia, ponieważ dla każdej konkretnej wartości zachodzi:
\[ P(X=x)=0 \]
W przypadku zmiennej skokowej różnica może być natomiast istotna. Jeżeli zmienna przyjmuje wartość \(x\) z dodatnim prawdopodobieństwem, to zdarzenia \(X<x\) oraz \(X\leq x\) nie są równoważne.
Przy definicji \(F(x)=P(X\leq x)\) dystrybuanta ma następujące własności:
- jest niemalejąca,
- przyjmuje wartości od 0 do 1,
- \(\lim_{x\to-\infty}F(x)=0\),
- \(\lim_{x\to+\infty}F(x)=1\),
- jest prawostronnie ciągła.
Dla zmiennej skokowej dystrybuanta ma zwykle postać schodkową. Skoki pojawiają się w tych punktach, w których zmienna ma dodatnie prawdopodobieństwo. Przy definicji \(F(x)=P(X\leq x)\) wartość w punkcie skoku należy już do „nowego” poziomu dystrybuanty. Dlatego na wykresach często zaznacza się kropki zamalowane i niezamalowane.
Dla zmiennej ciągłej dystrybuanta rośnie płynnie. Przykładem może być dystrybuanta rozkładu normalnego, która ma charakterystyczny, gładki kształt litery S.
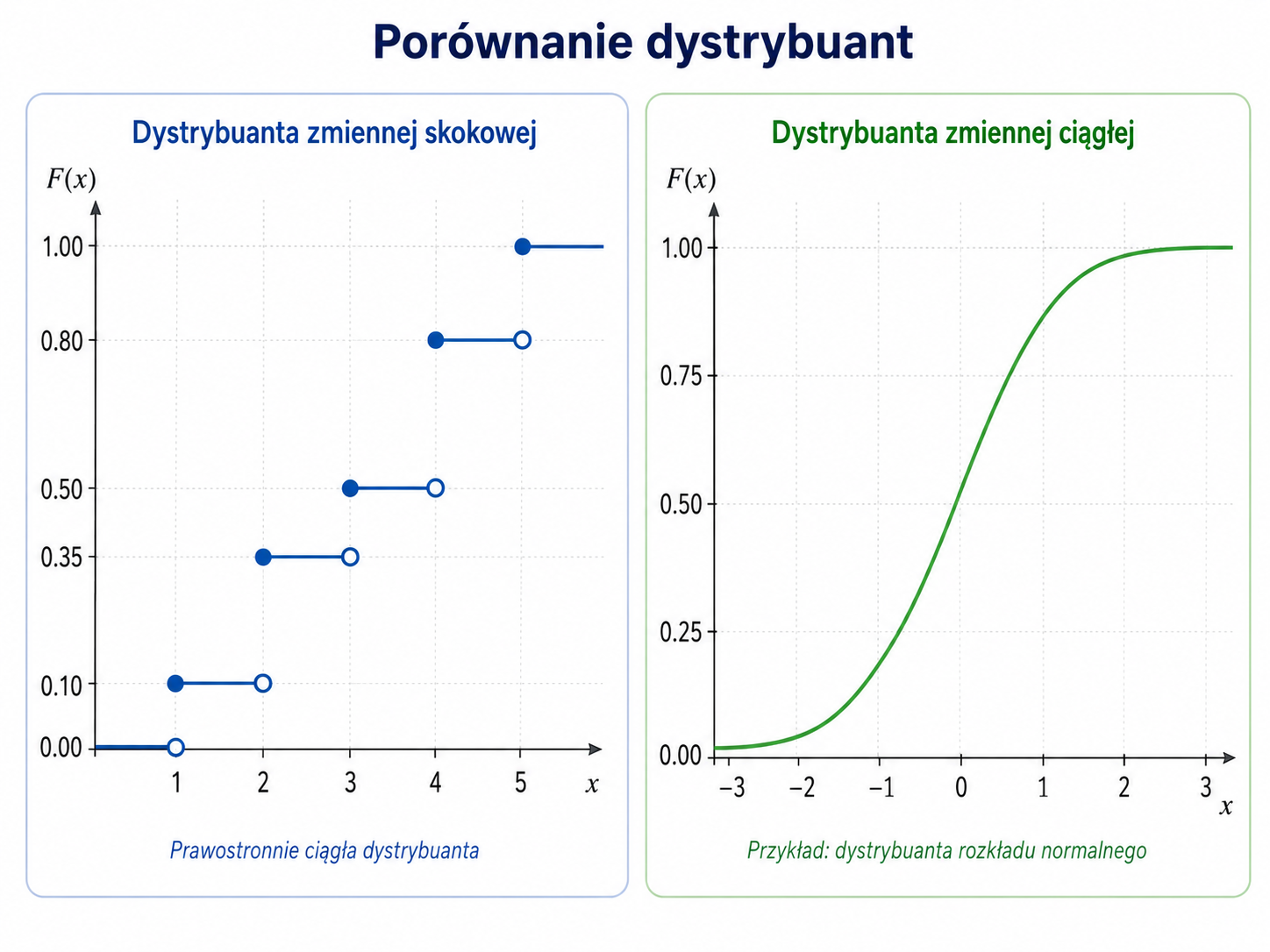
Dlaczego rodzaj danych ma znaczenie?
Rozpoznanie rodzaju danych jest jednym z pierwszych kroków poprawnej analizy statystycznej. Błąd popełniony na tym etapie może prowadzić do niewłaściwego doboru metod i mylących wniosków.
Dla danych nominalnych sensowne są przede wszystkim liczebności, udziały procentowe i wykresy słupkowe. Dla danych porządkowych ważne są kolejność kategorii, mediana i struktura odpowiedzi. Dla zmiennych skokowych można analizować prawdopodobieństwa konkretnych wartości. Dla zmiennych ciągłych naturalnym językiem stają się przedziały, gęstość i całki.
Ten podział powraca później w wielu działach statystyki: przy opisie rozkładów prawdopodobieństwa, budowie modeli ekonometrycznych, testowaniu hipotez, analizie ankiet, regresji oraz interpretacji wyników badań.
Krótkie zadanie dla czytelnika
Określ, czy poniższe zmienne są nominalne, porządkowe, skokowe czy ciągłe:
- Liczba reklamacji złożonych przez klientów w ciągu miesiąca.
- Temperatura powietrza mierzona dokładnym termometrem.
- Ocena zadowolenia klienta w skali: niski, średni, wysoki.
- Kolor wybranego produktu.
- Czas oczekiwania na połączenie z konsultantem.
Sprawdź odpowiedź
- Zmienna skokowa — liczba reklamacji jest wynikiem zliczania: 0, 1, 2, 3 i tak dalej.
- Zmienna ciągła interwałowa — temperatura może przyjmować wartości z przedziału, ale w skali Celsjusza sens mają różnice, a nie ilorazy.
- Zmienna porządkowa — poziomy „niski”, „średni”, „wysoki” mają naturalną kolejność.
- Zmienna nominalna — kolor jest kategorią bez naturalnego porządku.
- Zmienna ciągła ilorazowa — czas oczekiwania może być mierzony z dowolnie dużą dokładnością, a ilorazy czasu mają sens.
Podsumowanie
Dane statystyczne mogą mieć różny charakter. Niektóre opisują kategorie bez naturalnego porządku, inne kategorie uporządkowane, a jeszcze inne konkretne wielkości liczbowe. Wśród danych ilościowych szczególnie ważny jest podział na zmienne skokowe i ciągłe.
Zmienna skokowa przyjmuje wartości ze zbioru skończonego lub przeliczalnego. Można dla niej mówić o prawdopodobieństwie konkretnych wartości, na przykład \(P(X=3)\). Zmienna ciągła przyjmuje wartości z przedziału, a prawdopodobieństwo jednej dokładnie określonej wartości jest równe zero.
Wśród zmiennych ilościowych trzeba dodatkowo odróżniać skalę interwałową od ilorazowej. W skali interwałowej sens mają różnice między wartościami, ale nie ilorazy. W skali ilorazowej znaczenie mają zarówno różnice, jak i porównania typu „dwa razy więcej”.
Dlatego w przypadku zmiennych ciągłych nie pytamy zwykle o prawdopodobieństwo pojedynczego punktu, lecz o prawdopodobieństwo przedziału. Przykład z temperaturą dobrze pokazuje tę różnicę: matematycznie \(P(X=20)=0\), ale prawdopodobieństwo, że temperatura znajdzie się między 19,5°C a 20,5°C, może być dodatnie.
Od rodzaju danych zależy również dobór miar statystycznych. Dla zmiennych nominalnych wystarczają zwykle liczebności, procenty i dominanta, natomiast dla zmiennych ilościowych można stosować średnią, wariancję, odchylenie standardowe i inne klasyczne miary opisu.
Zrozumienie tego rozróżnienia ułatwia późniejszą naukę rachunku prawdopodobieństwa, rozkładów statystycznych, dystrybuanty, gęstości oraz metod analizy danych.
Utworzono: 04.06.2026 | Zmodyfikowano: 21.06.2026
Powiązane artykuły
- Miary statystyczne w statystyce opisowej
- Szeregi statystyczne i formy prezentacji danych
- Miary położenia, statystyka opisowa, średnia, mediana, dominanta, kwartyle.
- Średnia niejedno ma imię
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc