
Testowanie różnicy średnich w dwóch populacjach — próby niezależne i zależne.
Testowanie różnicy średnich pozwala sprawdzić, czy dwie populacje różnią się przeciętnym poziomem badanej cechy, czy też zaobserwowana różnica między próbami może wynikać wyłącznie z losowości. W artykule omawiamy testy dla prób niezależnych i zależnych, klasyczny test ze wspólną wariancją, test Welcha, duże próby, wartość p oraz związek testu z przedziałem ufności dla różnicy średnich.
Porównanie dwóch średnich pojawia się między innymi wtedy, gdy chcemy ocenić, czy nowa metoda nauczania poprawia wyniki uczniów, czy dwa procesy technologiczne dają produkty o tej samej średniej masie albo czy kobiety i mężczyźni w badanej populacji różnią się przeciętnym czasem wykonywania określonego zadania.
Ważne jest jednak nie tylko to, że dysponujemy dwiema średnimi z prób. Trzeba również ustalić, czy próby są niezależne, czy zależne, czy możemy przyjąć równość wariancji populacji oraz czy liczebności prób są małe, czy duże.
Ogólne pojęcia, takie jak hipoteza zerowa, poziom istotności, błędy pierwszego i drugiego rodzaju oraz moc testu, zostały omówione w artykule Testowanie hipotez statystycznych. Warto też przypomnieć zasady formułowania testów jedno- i dwustronnych z materiału Testowanie hipotez dotyczących średniej w jednej populacji.
Co testujemy przy porównywaniu dwóch średnich?
Niech \(\mu_1\) i \(\mu_2\) oznaczają średnie w dwóch populacjach. W praktyce nie testujemy zwykle obu średnich osobno, lecz ich różnicę:
Najczęściej interesuje nas sprawdzenie, czy średnie są równe. Wtedy testujemy, czy różnica populacyjna wynosi zero:
Możemy jednak testować również inną wartość różnicy. Przykładowo przedsiębiorstwo może uznać, że nowa technologia ma znaczenie praktyczne dopiero wtedy, gdy skróci średni czas produkcji o co najmniej 10 minut. Wtedy wartością hipotetyczną nie musi być zero.
Z dwóch prób otrzymujemy średnie:
Ich różnica:
jest estymatorem różnicy średnich populacyjnych \(\mu_1-\mu_2\). Test statystyczny ocenia, czy różnica zaobserwowana w próbach jest wystarczająco duża względem jej błędu standardowego, aby zakwestionować hipotezę dotyczącą \(\delta\).
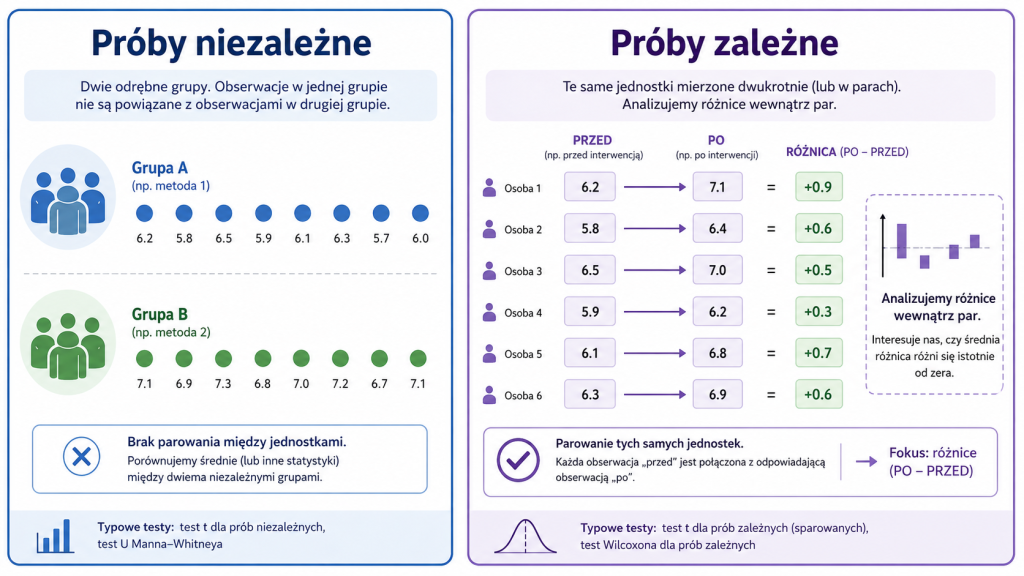
Próby niezależne i próby zależne
Najważniejszym krokiem przed wyborem testu jest rozpoznanie, czy obserwacje w obu próbach są niezależne, czy też tworzą naturalne pary.
Próby niezależne
Próby niezależne występują wtedy, gdy wynik jednej obserwacji w pierwszej grupie nie jest powiązany z wynikiem konkretnej obserwacji w drugiej grupie.
Przykłady:
- porównanie średnich wyników egzaminu w dwóch różnych klasach,
- porównanie średniej masy produktów z dwóch niezależnych linii produkcyjnych,
- porównanie średnich dochodów dwóch niezależnie dobranych grup respondentów,
- porównanie średniego czasu realizacji zamówień w dwóch oddziałach firmy.
Próby zależne
Próby zależne występują wtedy, gdy każdej obserwacji z pierwszej próby odpowiada konkretna obserwacja z drugiej próby. Zależność może wynikać z dwukrotnego pomiaru tej samej osoby lub obiektu albo z celowego dopasowania obserwacji w pary.
Przykłady:
- pomiar ciśnienia krwi tej samej osoby przed i po zastosowaniu leku,
- wynik egzaminu tych samych studentów przed kursem i po kursie,
- porównanie zużycia energii w tych samych gospodarstwach domowych przed i po modernizacji,
- porównanie osób dobranych w pary według wieku, płci lub innych cech.
Nie ignoruj powiązania obserwacji
Dane zależne nie powinny być automatycznie analizowane testem dla prób niezależnych. W analizie par wykorzystujemy informację o tym, że dwa wyniki dotyczą tego samego obiektu albo dobranych obiektów. Zignorowanie tej zależności może prowadzić do niewłaściwego błędu standardowego i obniżenia mocy testu.
Hipotezy dotyczące różnicy średnich
Najczęściej spotykamy trzy warianty hipotezy alternatywnej.
Test dwustronny
Najczęściej \(\delta_0=0\). Test dwustronny odpowiada na pytanie, czy średnie w populacjach różnią się, niezależnie od kierunku tej różnicy.
Test prawostronny
Stosujemy go wtedy, gdy interesuje nas wyłącznie sytuacja, w której średnia pierwszej populacji przewyższa średnią drugiej populacji o więcej niż wartość referencyjna.
Test lewostronny
Wybieramy go wtedy, gdy badanie dotyczy wyłącznie sytuacji, w której średnia pierwszej populacji jest mniejsza od średniej drugiej populacji.
Kierunek hipotezy alternatywnej należy wybrać przed analizą danych. Jeżeli wykonujemy test prawostronny, a różnica z próby okaże się ujemna, wynik nie wspiera hipotezy \(H_1\), nawet gdy odchylenie w przeciwną stronę jest duże. Szerzej o tym problemie piszemy w części Dlaczego kierunek testu jednostronnego ma znaczenie?.
Założenia testów
W klasycznych testach dla różnicy średnich zakładamy przede wszystkim, że próby zostały pobrane losowo oraz że obserwacje są niezależne w obrębie każdej z grup. Dodatkowo wybór modelu zależy od liczebności prób, normalności populacji oraz znajomości i relacji wariancji.
- Małe próby: klasyczne testy t wymagają zwykle założenia normalności populacji.
- Próby niezależne: potrzebujemy dwóch niezależnie pobranych grup.
- Próby zależne: zakładamy, że różnice w parach są niezależne między parami.
- Równość wariancji: jest konieczna tylko dla klasycznego testu t ze wspólną wariancją.
- Duże próby: pozwalają stosować przybliżenie normalne przy skończonych wariancjach populacji.
Brak podstaw do odrzucenia hipotezy o równości wariancji nie jest dowodem, że wariancje są dokładnie równe. Gdy założenie homogeniczności wariancji jest wątpliwe, bezpieczniejszym wyborem jest zazwyczaj test Welcha.
Próby niezależne: cztery modele testowania
Dla dwóch niezależnych prób najczęściej rozpatruje się cztery modele. Rozróżniają je założenia o wariancjach populacji oraz liczebnościach prób.
| Model | Założenia | Statystyka i rozkład |
|---|---|---|
| 1 | Populacje normalne, \(\sigma_1\) i \(\sigma_2\) znane. | Statystyka \(Z\), rozkład normalny standaryzowany. |
| 2 | Populacje normalne, wariancje nieznane, ale równe. | Test t ze wspólną wariancją, \(n_1+n_2-2\) stopnie swobody. |
| 3 | Populacje normalne, wariancje nieznane i nierówne. | Test Welcha z przybliżonymi stopniami swobody. |
| 4 | Duże, niezależne próby; skończone wariancje. | Przybliżony test normalny bez założenia równości wariancji. |
Model 1: znane wariancje populacji
Zakładamy, że obie populacje mają rozkład normalny, a ich odchylenia standardowe \(\sigma_1\) i \(\sigma_2\) są znane.
Statystyka testowa ma postać:
Jeżeli hipoteza zerowa jest prawdziwa, statystyka \(Z\) ma rozkład normalny standaryzowany:
Ten przypadek jest teoretycznie prosty, ale w praktyce spotykany rzadko. Zazwyczaj odchylenia standardowe populacji nie są znane i trzeba zastąpić je wielkościami wyznaczonymi z prób.
Model 2: nieznane, ale równe wariancje
W tym modelu zakładamy normalność obu populacji oraz równość ich wariancji:
Wariancja \(\sigma^2\) nie jest znana, dlatego szacujemy ją na podstawie obu prób. Wykorzystujemy w tym celu połączoną wariancję z próby:
Symbol \(S_p\) oznacza połączone odchylenie standardowe:
Statystyka testowa ma postać:
Przy prawdziwości hipotezy zerowej ma ona rozkład t-Studenta z liczbą stopni swobody:
Model ten jest właściwy wtedy, gdy założenie równych wariancji ma uzasadnienie merytoryczne albo wynika z wiedzy o badanych procesach. Nie należy jednak przyjmować go mechanicznie tylko dlatego, że jest prostszy obliczeniowo.
Po publikacji artykułu o testowaniu równości wariancji w tym miejscu warto dodać link do jego części dotyczącej weryfikacji założenia \(\sigma_1^2=\sigma_2^2\).
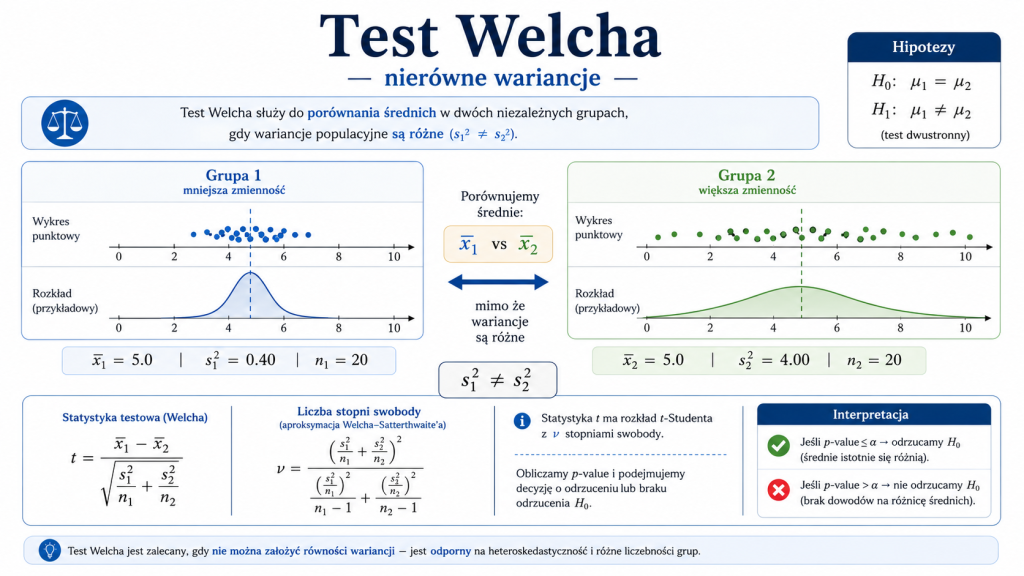
Model 3: nieznane i nierówne wariancje — test Welcha
Jeżeli populacje można uznać za normalne, ale nie możemy przyjąć równości wariancji, stosujemy test Welcha. Jest to obecnie standardowa procedura dla dwóch niezależnych prób o nierównych wariancjach, zwłaszcza gdy liczebności grup także są różne.
Statystyka testowa ma postać:
Jej rozkład przybliżamy rozkładem t-Studenta o liczbie stopni swobody wyznaczonej wzorem Welcha – Satterthwaite’a:
Wartość \(\nu\) nie musi być całkowita. Programy statystyczne i kalkulatory wykorzystują ją bez zaokrąglania. Przy korzystaniu z klasycznej tablicy t-Studenta można przyjąć niższą całkowitą liczbę stopni swobody, aby zastosować ostrożniejszą wartość krytyczną.
Dlaczego nie test Coxa?
W starszej literaturze można spotkać różne przybliżone rozwiązania problemu dwóch normalnych populacji o nierównych wariancjach, między innymi metody Coxa. W praktyce dydaktycznej i w nowoczesnych pakietach statystycznych najczęściej stosuje się jednak test Welcha wraz z przybliżeniem Welcha – Satterthwaite’a.
Model 4: duże próby i dowolny rozkład populacji
Jeżeli obie próby są dostatecznie duże, możemy skorzystać z centralnego twierdzenia granicznego. Nie musimy wtedy zakładać normalności populacji, pod warunkiem że ich wariancje są skończone.
Statystyka ma postać podobną do statystyki Welcha:
Dla dużych prób ma ona w przybliżeniu rozkład normalny standaryzowany. W tym modelu nie zakładamy równości wariancji populacji.
W podręcznikowych zadaniach często przyjmuje się orientacyjnie, że obie próby są duże, gdy:
Granica 30 ma jednak charakter umowny. Przy silnie asymetrycznych rozkładach, obserwacjach odstających lub bardzo nierównych liczebnościach grup warto zachować ostrożność i rozważyć bardziej odporne procedury.
Obszar krytyczny i wartość p
Niezależnie od wybranego modelu decyzję można podjąć na dwa równoważne sposoby: przez porównanie statystyki testowej z wartością krytyczną albo przez porównanie wartości p z poziomem istotności \(\alpha\).
W teście dwustronnym odrzucamy \(H_0\), gdy:
albo, w przypadku modelu normalnego:
W teście prawostronnym odrzucamy \(H_0\), gdy statystyka przekracza dodatnią wartość krytyczną. W teście lewostronnym odrzucamy \(H_0\), gdy jest mniejsza od ujemnej wartości krytycznej.
Przy metodzie wartości p obowiązuje reguła:
oraz:
Szersze omówienie poziomu istotności i wartości p znajduje się w artykule wprowadzającym do teorii testów.
Test a przedział ufności dla różnicy średnich
Dla każdego z opisanych modeli można zbudować przedział ufności dla różnicy średnich populacyjnych:
W teście dwustronnym na poziomie istotności \(\alpha\) obowiązuje ta sama zasada co przy jednej średniej: wartość hipotetyczna \(\delta_0\) należy do przedziału ufności \(1-\alpha\) wtedy i tylko wtedy, gdy nie ma podstaw do odrzucenia hipotezy zerowej.
W najczęstszym przypadku:
sprawdzamy po prostu, czy liczba zero należy do przedziału ufności dla różnicy średnich.
- Jeżeli \(0\) należy do przedziału ufności, nie ma podstaw do odrzucenia hipotezy o równości średnich.
- Jeżeli \(0\) nie należy do przedziału ufności, odrzucamy hipotezę o równości średnich.
W przypadku testów jednostronnych należy korzystać z odpowiedniego przedziału jednostronnego. Ogólną zasadę tej równoważności omówiliśmy w artykule Test statystyczny a przedział ufności.
Przykład: test Welcha dla prób niezależnych
Porównujemy wyniki dwóch niezależnych grup uczących się różnymi metodami. W pierwszej grupie otrzymano:
W drugiej grupie:
Próby są niezależne. Liczebności są niewielkie, a odchylenia standardowe wyraźnie się różnią. Przyjmujemy normalność populacji i stosujemy test Welcha.
Krok 1. Hipotezy
Badamy więc, czy średnie wyniki obu metod różnią się w populacjach.
Krok 2. Poziom istotności
Krok 3. Statystyka testowa
Krok 4. Przybliżona liczba stopni swobody
W kalkulatorze lub programie statystycznym stosujemy wartość ułamkową. Przy odczycie z klasycznej tablicy można przyjąć konserwatywnie \(\nu=15\).
Krok 5. Decyzja na podstawie wartości krytycznej
Dla testu dwustronnego, \(\alpha=0{,}05\) i około 15 stopni swobody otrzymujemy:
Ponieważ:
odrzucamy hipotezę zerową na poziomie istotności 0,05.
Krok 6. Wartość p i przedział ufności
Wartość p wynosi w przybliżeniu:
Jest ona mniejsza od 0,05, więc prowadzi do tej samej decyzji.
95-procentowy przedział ufności dla różnicy średnich wynosi w przybliżeniu:
Liczba zero nie należy do tego przedziału, co potwierdza odrzucenie hipotezy o równości średnich.
Wniosek: dane z prób dostarczają podstaw do stwierdzenia, że średnie wyniki obu metod różnią się w populacjach.
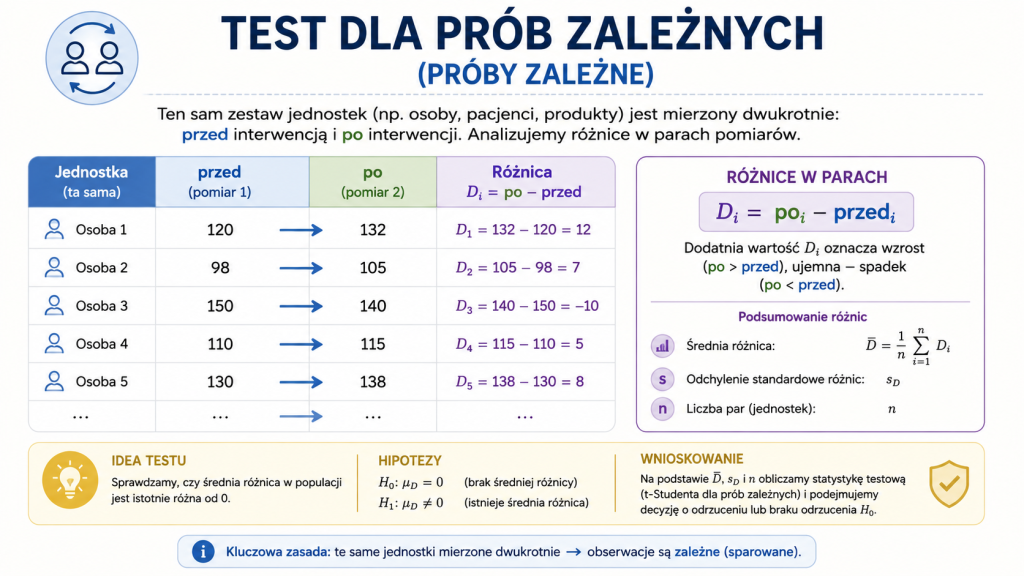
Próby zależne — test średniej różnic
W przypadku prób zależnych nie porównujemy dwóch niezależnych średnich. Dla każdej pary obserwacji obliczamy różnicę:
Następnie analizujemy jedną nową zmienną losową \(D\), czyli różnicę pomiędzy wynikami w parach. Jej wartość oczekiwana wynosi:
Test dla prób zależnych jest więc w istocie testem średniej jednej populacji — populacji różnic. Najczęściej sprawdzamy hipotezę:
czyli hipotezę, że przeciętna różnica między pomiarami w parach wynosi zero.
Możemy jednak przyjąć dowolną wartość hipotetyczną \(d_0\), na przykład gdy badamy, czy przeciętna poprawa wynosi co najmniej 5 punktów:
Dla małej próby zakładamy normalność populacji różnic, a niekoniecznie osobno normalność obu pierwotnych zmiennych.
Jeżeli mamy \(n\) par obserwacji, średnią różnic \(\overline{D}\) oraz odchylenie standardowe różnic \(S_D\), statystyka testowa ma postać:
Przy prawdziwości hipotezy zerowej i normalności różnic ma ona rozkład t-Studenta z liczbą stopni swobody:
Jest to dokładnie ten sam schemat, który stosujemy w teście dla średniej jednej populacji. Różnica polega tylko na tym, że analizowaną zmienną są różnice w parach. Zobacz również artykuł Testowanie hipotez dotyczących średniej w jednej populacji.
Kolejność odejmowania ma znaczenie
Przed obliczeniami trzeba jasno określić, czy różnicę definiujemy jako „po minus przed”, „metoda A minus metoda B” czy odwrotnie. Zmiana kolejności zmienia znak średniej różnic, a więc wpływa na interpretację testu jednostronnego. W teście dwustronnym decyzja pozostanie taka sama, ale opis wyniku będzie miał przeciwny znak.
Przykład: test dla prób zależnych
Dziesięciu uczestników kursu rozwiązało test przed szkoleniem i po jego zakończeniu. Dla każdej osoby obliczono różnicę:
Otrzymano:
Chcemy sprawdzić, czy kurs zwiększył średni wynik. Formułujemy test prawostronny:
Przyjmujemy poziom istotności \(\alpha=0{,}05\). Statystyka testowa wynosi:
Liczba stopni swobody wynosi:
Dla testu prawostronnego na poziomie istotności 0,05 wartość krytyczna wynosi:
Ponieważ:
odrzucamy hipotezę zerową. Dane dostarczają podstaw do stwierdzenia, że średni wynik po kursie jest wyższy niż przed kursem.
Kalkulatory i programy statystyczne
W prostych zadaniach można samodzielnie obliczyć statystykę testową, liczbę stopni swobody i porównać wynik z wartością krytyczną. W praktyce częściej korzysta się jednak z programów statystycznych, które podają również wartość p i przedział ufności dla różnicy średnich.
Takie procedury oferują między innymi Excel, SPSS, Statistica, Gretl oraz R. W zależności od programu test Welcha może występować pod nazwą Welch t-test, unequal variances t-test albo test t bez zaznaczenia założenia równych wariancji.
Do kontroli wartości krytycznych przydadzą się również nasze narzędzia: tablica i kalkulator rozkładu t-Studenta oraz tablica i kalkulator rozkładu normalnego.
Najczęstsze błędy
- Traktowanie prób zależnych jak niezależnych. Pomija to informację zawartą w parach obserwacji.
- Stosowanie testu ze wspólną wariancją bez uzasadnienia założenia \(\sigma_1^2=\sigma_2^2\).
- Automatyczne wybieranie testu t ze wspólną wariancją tylko dlatego, że ma prostszy wzór.
- Mylenie różnicy \(\overline{x}_1-\overline{x}_2\) z różnicą \(\overline{x}_2-\overline{x}_1\). Zmiana kolejności zmienia znak wyniku.
- Przyjmowanie \(\delta_0=0\) bez sprawdzenia, czy problem nie dotyczy innej wartości referencyjnej.
- Wybieranie testu jednostronnego dopiero po obejrzeniu danych.
- Uznawanie braku podstaw do odrzucenia \(H_0\) za dowód równości średnich.
- Pomijanie znaczenia praktycznego różnicy. Różnica istotna statystycznie może być zbyt mała, aby miała znaczenie techniczne, ekonomiczne lub społeczne.
Podsumowanie
Testowanie różnicy średnich pozwala ocenić, czy średnie w dwóch populacjach różnią się w sposób istotny statystycznie. Najważniejszym krokiem przed rozpoczęciem obliczeń jest poprawne rozpoznanie rodzaju prób.
- Dla prób niezależnych porównujemy średnie z dwóch odrębnych grup.
- Dla prób zależnych analizujemy średnią różnic w parach, dlatego test sprowadza się do testu dla jednej średniej.
- Przy normalnych populacjach i równych wariancjach można stosować klasyczny test t ze wspólną wariancją.
- Przy nierównych wariancjach właściwą standardową procedurą jest test Welcha.
- Dla dużych prób można wykorzystać przybliżenie normalne bez zakładania równości wariancji.
- W teście dwustronnym liczba zero należy do przedziału ufności dla różnicy średnich wtedy i tylko wtedy, gdy nie ma podstaw do odrzucenia hipotezy o równości średnich.
Utworzono: 22.06.2026
Powiązane artykuły
- Testowanie hipotez dotyczących średniej w jednej populacji
- Testowanie hipotez statystycznych — hipoteza zerowa, błędy, poziom istotności i moc testu
- Odchylenie standardowe i wariancja, jako miary rozrzutu
- Średnia niejedno ma imię
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc