
Testowanie hipotez dotyczących średniej w jednej populacji
Testowanie hipotez dotyczących średniej pozwala sprawdzić, czy średnia wyznaczona w próbie różni się od ustalonej wartości w sposób istotny statystycznie. W artykule omawiamy testy dla średniej jednej populacji: hipotezy jedno- i dwustronne, trzy klasyczne modele, obszar krytyczny, wartość p oraz związek testu z przedziałem ufności.
Średnia arytmetyczna z próby jest naturalnym oszacowaniem wartości oczekiwanej populacji. Czasem jednak samo oszacowanie nie wystarcza. Możemy chcieć sprawdzić, czy średnia masa produktu rzeczywiście wynosi wartość deklarowaną przez producenta, czy przeciętny czas wykonania usługi nie przekracza ustalonego limitu albo czy średni wynik egzaminu różni się od poziomu przyjętego w programie nauczania.
W takich sytuacjach stosujemy test statystyczny dla średniej jednej populacji. Test nie „udowadnia”, że określona średnia jest prawdziwa lub fałszywa. Pozwala natomiast ocenić, czy dane z próby są na tyle niezgodne z hipotezą dotyczącą średniej populacji, że należy ją odrzucić na przyjętym poziomie istotności.
Co sprawdza test dla średniej?
Niech \(X\) oznacza badaną cechę w populacji, a jej wartość oczekiwaną oznaczmy przez:
Średnia \(\mu\) może oznaczać między innymi przeciętną zawartość produktu w opakowaniu, średni czas realizacji zamówienia, średni dochód, średni wynik egzaminu albo przeciętne zużycie energii.
W teście statystycznym porównujemy nieznaną średnią populacji z wartością hipotetyczną \(\mu_0\). Wartość ta może wynikać z deklaracji producenta, normy technicznej, wymagania jakościowego, wcześniejszego badania lub przyjętej wartości referencyjnej.
Z próby losowej o liczebności \(n\) otrzymujemy obserwacje:
Po wykonaniu badania przyjmują one konkretne wartości:
Na ich podstawie obliczamy średnią z próby:
Jeżeli średnia z próby różni się od \(\mu_0\), nie oznacza to jeszcze automatycznie, że średnia populacji jest inna. Różnica może wynikać jedynie z losowego doboru próby. Zadaniem testu jest ocena, czy zaobserwowana różnica jest na tyle duża, że trudno byłoby uznać ją za zwykłe odchylenie losowe.
Hipoteza zerowa i alternatywna
Test dla średniej rozpoczynamy od sformułowania hipotezy zerowej \(H_0\) oraz hipotezy alternatywnej \(H_1\).
Hipoteza zerowa zawiera wartość średniej, którą chcemy sprawdzić:
Hipoteza alternatywna określa, jaki rodzaj odstępstwa od wartości \(\mu_0\) uznajemy za istotny z punktu widzenia problemu badawczego.
Przykład: producent deklaruje, że średnia objętość napoju w butelce wynosi 500 ml. Chcemy zweryfikować tę deklarację. Wartość hipotetyczna wynosi wtedy:
W dalszej części należy ustalić, czy interesuje nas każda różnica względem 500 ml, tylko zbyt mała średnia, czy może wyłącznie średnia przekraczająca 500 ml.
Hipotezy formułujemy przed analizą danych
Hipoteza alternatywna powinna wynikać z celu badania, teorii albo wymagań praktycznych. Nie należy dobierać jej kierunku dopiero po sprawdzeniu, czy średnia z próby wyszła większa czy mniejsza od wartości hipotetycznej.
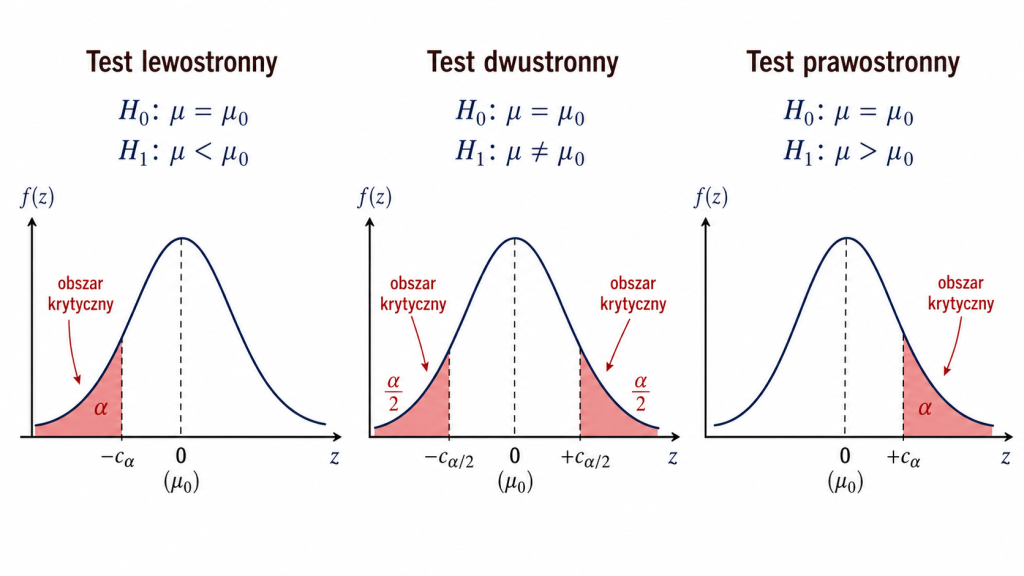
Test dwustronny, prawostronny i lewostronny
Wybór rodzaju testu zależy od postaci hipotezy alternatywnej.
Test dwustronny
Test dwustronny stosujemy wtedy, gdy interesuje nas każda różnica między średnią populacji a wartością hipotetyczną:
Przykład: kontrola jakości sprawdza, czy średnia zawartość opakowania różni się od 500 ml, niezależnie od tego, czy jest zbyt mała, czy zbyt duża.
Test prawostronny
Test prawostronny wybieramy wtedy, gdy interesuje nas wyłącznie sytuacja, w której średnia jest większa od wartości hipotetycznej:
Przykład: badamy, czy nowa metoda nauczania zwiększyła średni wynik egzaminu ponad dotychczasowy poziom.
Test lewostronny
Test lewostronny wybieramy wtedy, gdy istotne jest wyłącznie obniżenie średniej poniżej wartości referencyjnej:
Przykład: przedsiębiorstwo sprawdza, czy średni czas realizacji zamówienia jest krótszy od 48 godzin po wdrożeniu nowego systemu logistycznego.
W bardziej formalnym zapisie hipoteza zerowa dla testu prawostronnego może mieć postać \(H_0:\mu\leq\mu_0\), a dla testu lewostronnego \(H_0:\mu\geq\mu_0\). Przy wyznaczaniu rozkładu statystyki testowej rozpatruje się wtedy przypadek graniczny \(\mu=\mu_0\).
Założenia testu dla średniej
Dobór właściwego testu zależy przede wszystkim od trzech kwestii:
- czy populacja ma rozkład normalny,
- czy odchylenie standardowe populacji \(\sigma\) jest znane,
- czy próba jest dostatecznie duża, aby można było wykorzystać przybliżenie normalne.
W każdym modelu zakłada się również, że obserwacje pochodzą z losowej próby i są niezależne. Jeżeli dane są silnie zależne, na przykład kolejne pomiary tej samej osoby albo kolejne obserwacje szeregu czasowego, klasyczny test dla jednej średniej może nie być odpowiedni bez dodatkowych modyfikacji.
Warto też odróżniać odchylenie standardowe populacji \(\sigma\) od odchylenia standardowego wyznaczonego z próby. To rozróżnienie decyduje o wyborze rozkładu normalnego albo t-Studenta.
Trzy modele testowania średniej
W klasycznych zadaniach dotyczących jednej średniej populacji spotyka się trzy podstawowe modele. Są one bezpośrednio związane z modelami stosowanymi przy estymacji przedziałowej wartości oczekiwanej.
| Model | Założenia | Rozkład statystyki testowej |
|---|---|---|
| 1 | Populacja normalna, \(\sigma\) znane. | Normalny standaryzowany. |
| 2 | Populacja normalna, \(\sigma\) nieznane. | t-Studenta z \(n-1\) stopniami swobody. |
| 3 | Populacja o dowolnym rozkładzie, próba duża, wariancja skończona. | W przybliżeniu normalny standaryzowany. |
Model 1: populacja normalna i znane odchylenie standardowe
Zakładamy, że populacja ma rozkład normalny:
oraz że odchylenie standardowe populacji \(\sigma\) jest znane. Nie chodzi tu o wartość policzoną z bieżącej próby, ale o odchylenie znane wcześniej, na przykład z długotrwałej kontroli stabilnego procesu technologicznego.
Statystyka testowa ma wtedy postać:
Jeżeli hipoteza zerowa jest prawdziwa, statystyka \(Z\) ma rozkład normalny standaryzowany:
Po podstawieniu danych z próby otrzymujemy obserwowaną wartość statystyki:
Wartości krytyczne rozkładu normalnego można odczytać z tablicy rozkładu normalnego i kalkulatora.
Model 2: populacja normalna i nieznane odchylenie standardowe
To najczęściej spotykany model przy małej próbie. Zakładamy, że populacja ma rozkład normalny, ale odchylenie standardowe populacji \(\sigma\) jest nieznane.
Zastępujemy je skorygowanym odchyleniem standardowym z próby:
Statystyka testowa ma wtedy postać:
Jeżeli hipoteza zerowa jest prawdziwa i populacja ma rozkład normalny, statystyka \(T\) ma rozkład t-Studenta z \(n-1\) stopniami swobody:
Po podstawieniu danych otrzymujemy:
Jeżeli w zadaniu podano odchylenie standardowe obliczone z mianownikiem \(n\), oznaczone na przykład jako \(s_n\), można wykorzystać równoważną postać:
Wartości krytyczne oraz wartości p można wyznaczać z tablicy rozkładu t-Studenta i kalkulatora.
Mała próba wymaga założenia normalności
Jeżeli próba jest mała, odchylenie standardowe populacji jest nieznane, a stosujemy test t-Studenta, należy przyjąć założenie normalności populacji. Gdy zadanie nie podaje go wprost, warto zapisać: „Przyjmujemy, że badana populacja ma rozkład normalny”.
Model 3: duża próba i dowolny rozkład populacji
W tym modelu nie zakładamy normalności populacji. Wymagamy jednak, aby jej wariancja była skończona oraz aby próba była dostatecznie duża.
Podstawą jest centralne twierdzenie graniczne. Dla dużej próby rozkład średniej z próby jest w przybliżeniu normalny, nawet gdy sam rozkład populacji nie jest normalny.
Ponieważ \(\sigma\) jest zwykle nieznane, w praktyce zastępujemy je odchyleniem standardowym z próby. Otrzymujemy statystykę:
Wartość tej statystyki porównujemy z kwantylami rozkładu normalnego. W podręcznikowych zadaniach za próbę dużą często uznaje się próbę o liczebności:
Nie jest to jednak ścisła granica matematyczna. Przy bardzo silnej asymetrii, ciężkich ogonach rozkładu albo licznych obserwacjach nietypowych próba licząca 30 obserwacji może nie zapewniać dobrego przybliżenia normalnego.
Jeżeli próba jest mała i nie możemy przyjąć normalności populacji, nie należy automatycznie używać testu t-Studenta. W zależności od problemu właściwsze mogą być procedury bootstrapowe albo testy nieparametryczne.
Obszar krytyczny i wartość krytyczna
Po wybraniu modelu obliczamy wartość statystyki testowej oraz porównujemy ją z obszarem krytycznym. Obszar krytyczny jest zbiorem wartości statystyki prowadzących do odrzucenia hipotezy zerowej.
Niech \(c_{\alpha}\) oznacza dodatnią wartość krytyczną odpowiedniego rozkładu, wyznaczoną tak, że prawdopodobieństwo znalezienia się statystyki powyżej niej wynosi \(\alpha\).
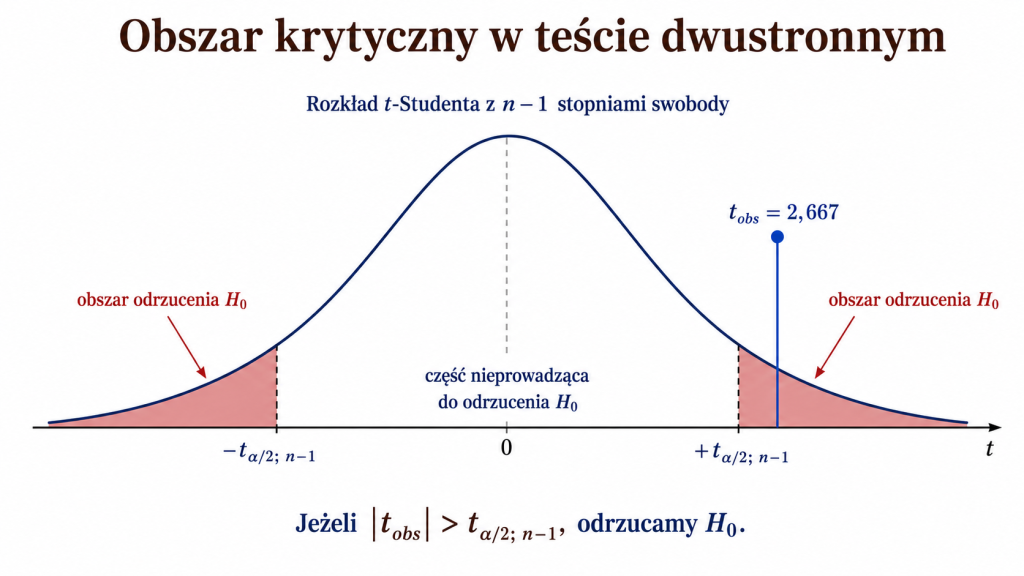
Reguła dla testu dwustronnego
W teście dwustronnym obszar krytyczny znajduje się w obu ogonach rozkładu. Odrzucamy \(H_0\), gdy:
Dla modelu normalnego \(c_{\alpha/2}=u_{\alpha/2}\), a dla modelu t-Studenta \(c_{\alpha/2}=t_{\alpha/2;n-1}\).
Reguła dla testu prawostronnego
W teście prawostronnym odrzucamy \(H_0\), gdy:
Reguła dla testu lewostronnego
W teście lewostronnym odrzucamy \(H_0\), gdy:
Wartość krytyczna jest wyznaczana przed podjęciem decyzji, na podstawie przyjętego poziomu istotności i właściwego rozkładu statystyki testowej.
Wartość p
Drugim sposobem podjęcia decyzji jest obliczenie wartości p. Jest to prawdopodobieństwo uzyskania — przy prawdziwości hipotezy zerowej — wyniku co najmniej tak skrajnego jak wynik zaobserwowany.
Reguła decyzyjna jest następująca:
W teście dwustronnym wartość p uwzględnia skrajność wyniku w obu kierunkach. W teście prawostronnym liczymy prawdopodobieństwo uzyskania wartości co najmniej tak dużej jak zaobserwowana, a w teście lewostronnym — wartości co najmniej tak małej.
Wartość p nie jest prawdopodobieństwem prawdziwości hipotezy zerowej. Mała wartość p oznacza jedynie, że wynik próby byłby mało zgodny z \(H_0\), gdyby \(H_0\) była prawdziwa.
Dlaczego kierunek testu jednostronnego ma znaczenie?
W testach jednostronnych nie wystarczy, że średnia z próby różni się od wartości hipotetycznej. Musi różnić się w kierunku wskazanym przez hipotezę alternatywną.
Załóżmy, że wykonujemy test prawostronny:
Jeżeli średnia z próby okaże się znacznie mniejsza od 100, statystyka testowa będzie ujemna. Wynik może sugerować, że rzeczywista średnia jest niższa od wartości hipotetycznej, ale nie dostarcza argumentu na rzecz hipotezy \(H_1:\mu>100\).
W takim przypadku test prawostronny z definicji nie prowadzi do odrzucenia \(H_0\), nawet gdy odchylenie w przeciwną stronę jest duże. Nie oznacza to, że \(H_0\) została potwierdzona. Oznacza jedynie, że dane nie wspierają alternatywy sformułowanej w tym konkretnym kierunku.
Nie zmieniaj kierunku po obejrzeniu wyniku
Jeżeli po otrzymaniu danych okazuje się, że średnia odchyliła się w stronę przeciwną do zakładanej, nie wolno po prostu zamienić testu prawostronnego na lewostronny. Byłoby to dopasowywanie procedury do wyniku i prowadziłoby do niekontrolowanego zwiększenia ryzyka błędu pierwszego rodzaju.
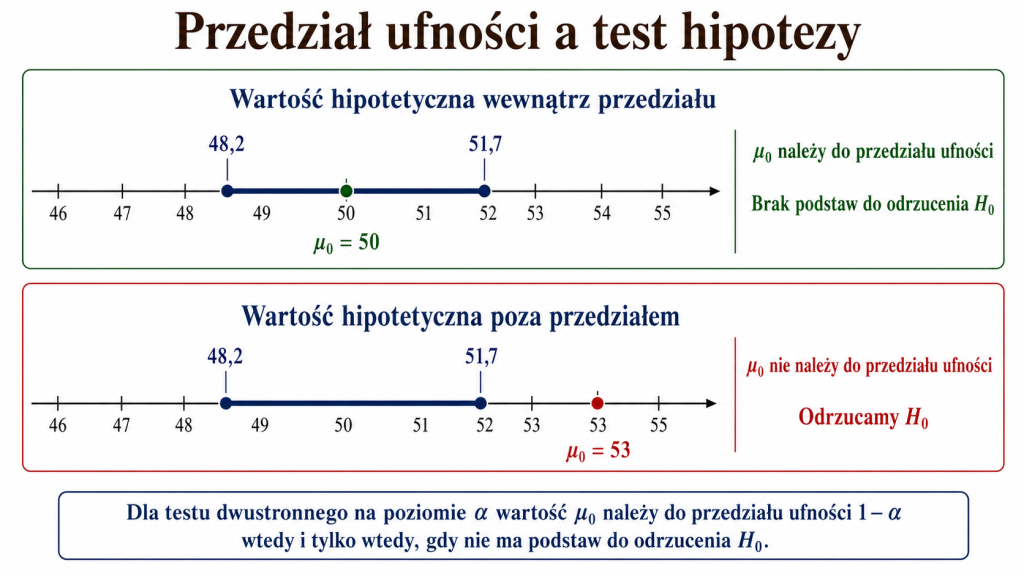
Test dla średniej a przedział ufności
Testowanie hipotez oraz estymacja przedziałowa są ze sobą ściśle powiązane. Dla tego samego modelu statystycznego, tych samych danych i zgodnych poziomów istotności obie procedury prowadzą do równoważnych decyzji.
Jeżeli budujemy dwustronny przedział ufności dla średniej na poziomie \(1-\alpha\), a następnie wykonujemy dwustronny test:
na poziomie istotności \(\alpha\), obowiązuje zasada:
- jeżeli wartość \(\mu_0\) należy do przedziału ufności, nie ma podstaw do odrzucenia \(H_0\);
- jeżeli wartość \(\mu_0\) leży poza przedziałem ufności, odrzucamy \(H_0\).
Przykładowo, gdy 95-procentowy przedział ufności dla średniej wynosi \((48{,}2;\;51{,}7)\), hipoteza \(H_0:\mu=50\) nie zostanie odrzucona na poziomie istotności \(\alpha=0{,}05\). Wartość 50 należy bowiem do przedziału. Hipoteza \(H_0:\mu=53\) zostałaby natomiast odrzucona, ponieważ 53 leży poza tym przedziałem.
W przypadku testów jednostronnych porównanie powinno dotyczyć odpowiedniego przedziału jednostronnego. Klasyczny dwustronny przedział ufności nie jest wtedy bezpośrednim odpowiednikiem testu jednostronnego.
Przykład: test dla średniej jednej populacji
Producent deklaruje, że średnia objętość napoju w butelkach wynosi 500 ml. Z losowej próby 16 butelek otrzymano:
Odchylenie standardowe populacji nie jest znane. Przyjmujemy, że populacja ma rozkład normalny. Stosujemy więc test t-Studenta dla jednej średniej.
Krok 1. Hipotezy
Chcemy sprawdzić każdą różnicę względem deklarowanych 500 ml, dlatego formułujemy test dwustronny:
Krok 2. Poziom istotności
Krok 3. Statystyka testowa
Krok 4. Obszar krytyczny
Liczba stopni swobody wynosi:
Dla testu dwustronnego na poziomie \(\alpha=0{,}05\) wartość krytyczna wynosi w przybliżeniu:
Obszar krytyczny ma zatem postać:
Ponieważ:
odrzucamy hipotezę zerową na poziomie istotności 0,05.
Krok 5. Wartość p
Dla obserwowanej wartości statystyki wartość p wynosi w przybliżeniu:
Ponieważ \(p<0{,}05\), metoda wartości p prowadzi do tej samej decyzji: odrzucamy \(H_0\).
Krok 6. Kontrola przez przedział ufności
95-procentowy przedział ufności dla średniej wynosi:
Wartość hipotetyczna 500 ml nie należy do przedziału ufności. Potwierdza to decyzję o odrzuceniu hipotezy \(H_0:\mu=500\).
Wniosek należy sformułować ostrożnie: dane z próby dostarczają podstaw do odrzucenia hipotezy, że średnia objętość napoju wynosi 500 ml. Nie oznacza to, że każda pojedyncza butelka ma objętość różną od 500 ml ani że znamy dokładną wartość średniej w całej populacji.
Moc testu dla średniej
Moc testu określa prawdopodobieństwo odrzucenia hipotezy zerowej wtedy, gdy jest ona fałszywa. W przypadku testu dla średniej moc rośnie przede wszystkim wtedy, gdy:
- zwiększa się liczebność próby,
- rzeczywista średnia coraz bardziej różni się od wartości hipotetycznej,
- zmienność badanej cechy jest mniejsza,
- przyjmiemy wyższy poziom istotności \(\alpha\).
Ostatni punkt wymaga ostrożności. Podniesienie \(\alpha\), na przykład z 0,05 do 0,10, ułatwia odrzucenie hipotezy zerowej i zwykle zwiększa moc testu. Jednocześnie zwiększa ryzyko błędu pierwszego rodzaju, czyli odrzucenia prawdziwej hipotezy zerowej.
Najbezpieczniejszym sposobem zwiększenia mocy jest zazwyczaj zwiększenie liczebności dobrze zaprojektowanej próby. Brak podstaw do odrzucenia \(H_0\) może bowiem wynikać nie tylko z jej zgodności z rzeczywistością, ale również ze zbyt małej próby i niewystarczającej mocy testu.
Kalkulatory i programy statystyczne
W prostych zadaniach wartość krytyczną można odczytać z tablic rozkładu normalnego lub t-Studenta. W praktyce częściej korzysta się z kalkulatorów oraz programów statystycznych, które obliczają zarówno statystykę testową, jak i wartość p.
Do najczęściej używanych narzędzi należą między innymi Excel, SPSS, Statistica, Gretl oraz R. Warto jednak rozumieć, jaki model został wybrany i jak interpretować otrzymaną wartość p, zamiast traktować wynik programu jako automatyczną odpowiedź.
Do ręcznej kontroli obliczeń przydadzą się także nasze narzędzia: tablica i kalkulator rozkładu normalnego oraz tablica i kalkulator rozkładu t-Studenta.
Najczęstsze błędy przy testowaniu średniej
- Mylenie braku podstaw do odrzucenia \(H_0\) z potwierdzeniem hipotezy zerowej. Test nie udowadnia, że \(H_0\) jest prawdziwa.
- Wybieranie testu jednostronnego po obejrzeniu danych. Kierunek hipotezy alternatywnej ustalamy przed analizą wyników.
- Stosowanie rozkładu normalnego zamiast t-Studenta przy małej próbie i nieznanym \(\sigma\).
- Pomijanie założenia normalności populacji w modelu z małą próbą.
- Mylenie odchylenia standardowego populacji \(\sigma\) z odchyleniem standardowym z próby.
- Stosowanie wartości krytycznej dla testu jednostronnego w teście dwustronnym albo odwrotnie.
- Nieuwzględnienie kierunku statystyki w teście jednostronnym. Wynik silnie odchylony w przeciwną stronę nie wspiera przyjętej hipotezy alternatywnej.
- Błędna interpretacja wartości p. Wartość p nie jest prawdopodobieństwem prawdziwości \(H_0\).
- Pomijanie praktycznego znaczenia różnicy. Istotność statystyczna nie przesądza jeszcze o znaczeniu ekonomicznym, technicznym ani społecznym wyniku.
Podsumowanie
Testowanie hipotez dotyczących średniej jednej populacji pozwala ocenić, czy różnica między średnią z próby a wartością hipotetyczną jest na tyle duża, że stanowi podstawę do odrzucenia hipotezy zerowej.
- W teście dla jednej średniej formułujemy hipotezę zerową \(H_0:\mu=\mu_0\) oraz odpowiednią hipotezę alternatywną.
- Test dwustronny stosujemy wtedy, gdy interesuje nas każda różnica, a test jednostronny wtedy, gdy kierunek różnicy został określony przed analizą danych.
- Przy normalnej populacji i znanym \(\sigma\) stosujemy rozkład normalny, a przy nieznanym \(\sigma\) i małej próbie — rozkład t-Studenta.
- Dla dużej próby można wykorzystać przybliżenie normalne wynikające z centralnego twierdzenia granicznego.
- Decyzję można podjąć przez porównanie statystyki z obszarem krytycznym albo przez porównanie wartości p z poziomem istotności.
- W teście dwustronnym na poziomie \(\alpha\) wartość hipotetyczna należy do przedziału ufności \(1-\alpha\) wtedy i tylko wtedy, gdy nie ma podstaw do odrzucenia \(H_0\).
Utworzono: 21.06.2026
Powiązane artykuły
- Testowanie hipotez statystycznych — hipoteza zerowa, błędy, poziom istotności i moc testu
- Estymacja wartości oczekiwanej (średniej) — estymacja punktowa i przedziałowa
- Średnia niejedno ma imię
- Odchylenie standardowe i wariancja, jako miary rozrzutu
- Miary położenia, statystyka opisowa, średnia, mediana, dominanta, kwartyle.
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc