
Szeregi statystyczne i formy prezentacji danych
Dane statystyczne można przedstawić na wiele sposobów, ale nie każda forma zapisu jest równie wygodna do analizy. Czasem wystarcza lista pojedynczych obserwacji, a czasem potrzebujemy tabeli liczebności, przedziałów klasowych albo uporządkowania danych w czasie. Właśnie temu służą szeregi statystyczne.
W statystyce opisowej bardzo ważne jest nie tylko to, jakiego rodzaju są dane, ale również w jakiej postaci zostały zapisane. Od tego zależy przejrzystość prezentacji, dobór wykresu, a często także sposób obliczania średniej, mediany, dominanty czy miar zróżnicowania.
W tym artykule uporządkujemy najważniejsze formy prezentacji danych statystycznych. Omówimy szereg szczegółowy, szereg rozdzielczy punktowy, szereg rozdzielczy przedziałowy oraz szereg czasowy. Zobaczymy też, czym różni się wykres słupkowy od histogramu i dlaczego grupowanie danych bywa jednocześnie użyteczne i upraszczające.
Spis treści
- Po co porządkować dane statystyczne?
- Co to jest szereg statystyczny?
- Szereg szczegółowy
- Szereg rozdzielczy punktowy
- Szereg rozdzielczy przedziałowy
- Zalety i ograniczenia grupowania danych
- Jak dobrać przedziały klasowe?
- Szereg czasowy
- Szereg okresów i szereg momentów
- Tablice statystyczne
- Wykresy jako forma prezentacji danych
- Dlaczego forma danych wpływa na obliczanie miar statystycznych?
- Podsumowanie
Po co porządkować dane statystyczne?
W praktyce statystycznej bardzo rzadko pracujemy wyłącznie na nieuporządkowanej liście wyników. Gdy obserwacji jest niewiele, można jeszcze zapisać je jedna po drugiej. Gdy jednak danych jest kilkadziesiąt, kilkaset albo kilka tysięcy, potrzebujemy sposobu, który pozwoli szybko zobaczyć ich strukturę.
Porządkowanie danych ma kilka podstawowych celów:
- ułatwia odczytanie najważniejszych informacji,
- pozwala wykryć skupienia i rozproszenie wartości,
- przygotowuje dane do tworzenia wykresów,
- ułatwia obliczanie miar statystycznych,
- pozwala przejść od chaotycznej listy obserwacji do czytelnej tabeli lub schematu.
To właśnie dlatego w statystyce używa się szeregów statystycznych, czyli uporządkowanych form zapisu danych.
Co to jest szereg statystyczny?
Szereg statystyczny to uporządkowany zapis danych statystycznych według określonej zasady. Zależnie od rodzaju zmiennej i celu analizy dane można przedstawić na różne sposoby: jako listę pojedynczych obserwacji, jako tabelę liczebności, jako zestaw przedziałów klasowych albo jako wartości uporządkowane w czasie.
Najczęściej wyróżnia się:
- szereg szczegółowy,
- szereg rozdzielczy punktowy,
- szereg rozdzielczy przedziałowy,
- szereg czasowy.

Szereg szczegółowy
Szereg szczegółowy to najprostsza forma prezentacji danych. Polega na zapisaniu wszystkich obserwacji osobno, bez grupowania ich w klasy lub przedziały.
Przykładowo wyniki sprawdzianu ośmiu uczniów można zapisać następująco:
| Uczeń | Wynik (%) |
|---|---|
| 1 | 42 |
| 2 | 55 |
| 3 | 61 |
| 4 | 61 |
| 5 | 70 |
| 6 | 78 |
| 7 | 82 |
| 8 | 90 |
Taki zapis zachowuje pełną informację o każdej obserwacji. Dzięki temu można bezpośrednio obliczać medianę, kwartyle, rozstęp albo analizować konkretne wartości. Wadą szeregu szczegółowego jest jednak to, że przy większej liczbie danych staje się mało czytelny.
Szereg szczegółowy jest więc szczególnie przydatny wtedy, gdy:
- liczba obserwacji jest niewielka,
- chcemy zachować pełną informację o każdej wartości,
- potrzebujemy uporządkować dane rosnąco lub malejąco,
- planujemy obliczać miary pozycyjne bez grupowania danych.
Szereg rozdzielczy punktowy
Szereg rozdzielczy punktowy stosujemy wtedy, gdy zmienna przyjmuje pojedyncze, wyraźnie rozróżnialne wartości, najczęściej skokowe. Zamiast zapisywać każdą obserwację osobno, podajemy możliwe wartości zmiennej oraz to, ile razy każda z nich wystąpiła.
Przykład: liczba reklamacji w kolejnych miesiącach.
| Liczba reklamacji | Liczba miesięcy | Częstość |
|---|---|---|
| 0 | 3 | 0,20 |
| 1 | 5 | 0,33 |
| 2 | 4 | 0,27 |
| 3 | 2 | 0,13 |
| 4 | 1 | 0,07 |
W takim szeregu pojawiają się ważne pojęcia:
- wartość zmiennej — możliwy wynik obserwacji,
- liczebność — liczba obserwacji przyjmujących daną wartość,
- częstość — udział tej liczebności w całej zbiorowości,
- liczebność skumulowana — suma liczebności do danej wartości,
- częstość skumulowana — suma częstości do danej wartości.
Szereg rozdzielczy punktowy porządkuje dane i pozwala szybko zobaczyć, które wartości pojawiają się najczęściej. W porównaniu z szeregiem szczegółowym jest to już uproszczenie, ale zwykle nie tracimy jeszcze informacji o konkretnych wartościach zmiennej — wiemy, ile razy wystąpiła każda z nich.
Szereg rozdzielczy przedziałowy
Szereg rozdzielczy przedziałowy stosuje się przede wszystkim wtedy, gdy zmienna może przyjmować wiele różnych wartości, zwłaszcza gdy jest zmienną ciągłą albo gdy liczba obserwacji jest bardzo duża. W takim przypadku zamiast pojedynczych wartości podajemy przedziały klasowe oraz liczebności obserwacji należących do tych przedziałów.
Przykład: czas dojazdu do pracy.
| Czas dojazdu (min) | Liczba osób |
|---|---|
| 0 – 10 | 4 |
| 10 – 20 | 12 |
| 20 – 30 | 18 |
| 30 – 40 | 9 |
| 40 – 50 | 3 |
W szeregu przedziałowym ważne są takie elementy, jak:
- przedział klasowy — zakres wartości należących do jednej klasy,
- dolna granica przedziału,
- górna granica przedziału,
- szerokość przedziału,
- środek przedziału — często używany później w obliczeniach przybliżonych,
- liczebność klasy.
Szereg rozdzielczy przedziałowy jest bardziej radykalnym uporządkowaniem danych. Zamiast pojedynczych wartości znamy tylko przedziały, do których te wartości należą. W tym sensie jest to pewnego rodzaju kompresja stratna: zyskujemy przejrzystość, ale tracimy informację o dokładnych wartościach obserwacji.
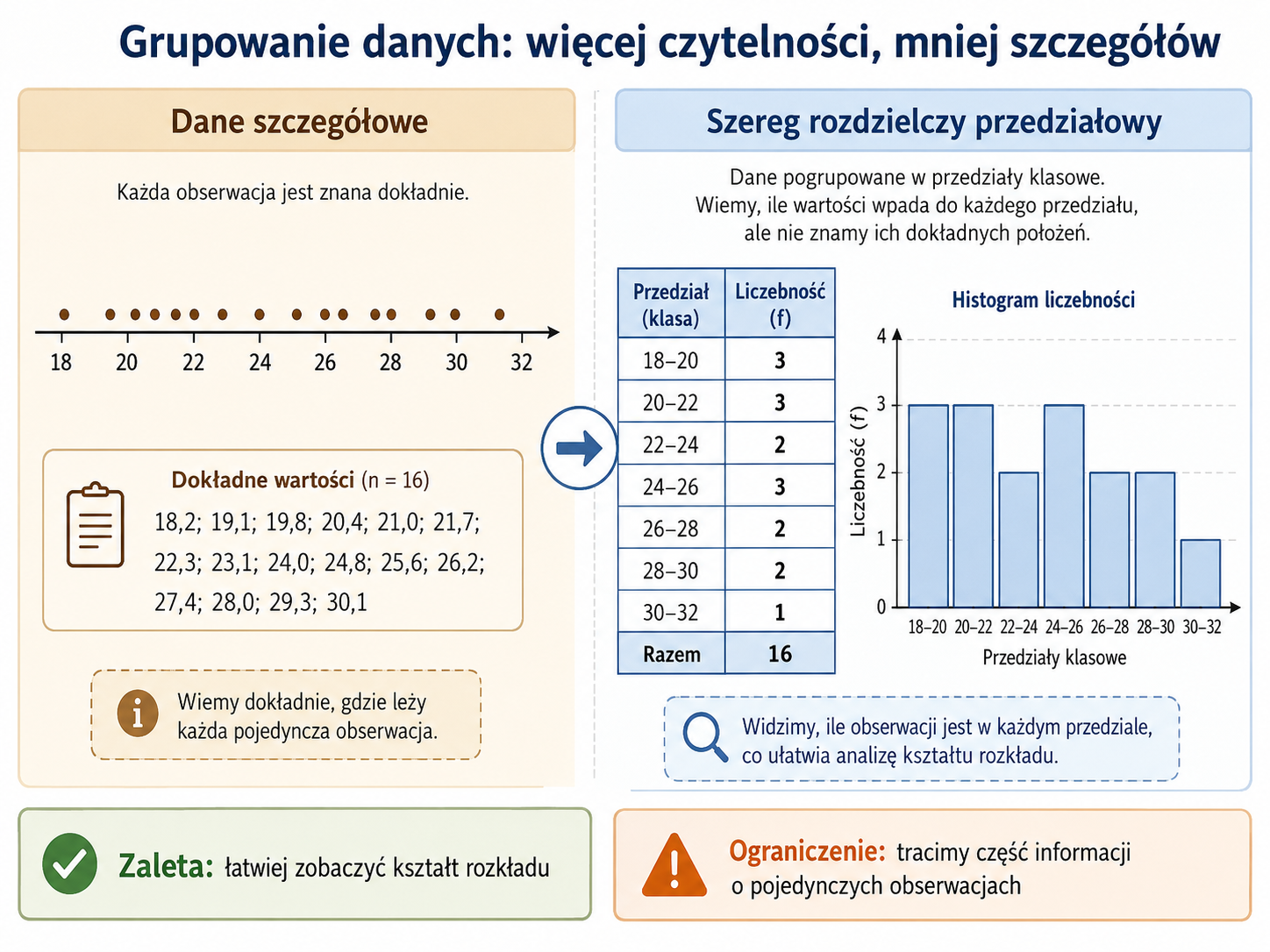
Zalety i ograniczenia grupowania danych
Grupowanie danych nie jest ani wyłącznie zaletą, ani wyłącznie wadą. To narzędzie, które upraszcza obraz zbiorowości, ale jednocześnie pomaga zobaczyć jej strukturę.
Do najważniejszych zalet grupowania danych należą:
- większa czytelność danych licznych i zróżnicowanych,
- łatwiejsze uchwycenie ogólnego kształtu rozkładu,
- możliwość budowy histogramu,
- łatwiejsza identyfikacja obszarów koncentracji wartości.
Najważniejsze ograniczenia to natomiast:
- utrata informacji o dokładnych wartościach obserwacji,
- zależność wyniku od sposobu doboru przedziałów,
- fakt, że część miar wyznaczonych z danych pogrupowanych ma charakter przybliżony.
Czasem dane szczegółowe mogą wręcz utrudniać interpretację. Jeśli zmienna jest mierzona bardzo dokładnie, na przykład do dwóch miejsc po przecinku, wiele wartości może wystąpić tylko raz. Może się wtedy zdarzyć, że formalna dominanta szeregu szczegółowego będzie przypadkowa, bo akurat jakaś wartość powtórzyła się dwa razy. Po pogrupowaniu danych w przedziały łatwiej zauważyć, w którym obszarze wartości rzeczywiście koncentrują się najczęściej.
Nie oznacza to jednak, że szereg przedziałowy jest zawsze lepszy. Oznacza jedynie, że w statystyce trzeba dobierać formę prezentacji danych do charakteru zmiennej i celu analizy.
Jak dobrać przedziały klasowe?
Dobór przedziałów klasowych jest ważnym etapem budowy szeregu rozdzielczego przedziałowego. Nie istnieje jedna absolutnie obowiązująca metoda, która byłaby najlepsza w każdej sytuacji.
W praktyce zwraca się uwagę przede wszystkim na:
- liczbę przedziałów,
- szerokość przedziałów,
- punkt początkowy pierwszego przedziału,
- dokładność pomiaru,
- czytelność i sens merytoryczny podziału.
Zbyt mała liczba przedziałów prowadzi do nadmiernego wygładzenia danych, a zbyt duża sprawia, że tabela staje się mało przejrzysta i traci swój porządkujący charakter. W praktyce stosuje się różne reguły pomocnicze, na przykład regułę pierwiastkową albo regułę Sturgesa, ale należy traktować je jako wskazówki techniczne, a nie sztywne prawa.
Przykładowo można spotkać przybliżenia:
\[ k \approx \sqrt{n} \]
albo
\[ k \approx 1 + 3{,}322 \log_{10} n \]
gdzie \(k\) oznacza liczbę klas, a \(n\) liczbę obserwacji. W praktyce i tak najważniejsze jest to, aby przedziały były logiczne, przejrzyste i adekwatne do analizowanej zmiennej.
Szereg czasowy
Szereg czasowy to uporządkowany zapis wartości zmiennej statystycznej według czasu. Jego podstawową cechą jest to, że każda obserwacja jest przypisana do określonego momentu albo okresu.
Szeregi czasowe są bardzo ważne w ekonomii, demografii, finansach, meteorologii i wielu innych dziedzinach. Pozwalają badać zmienność zjawisk w czasie, obserwować trendy, wahania sezonowe, cykle i zmiany długookresowe.
Przykłady szeregów czasowych:
- miesięczna sprzedaż przedsiębiorstwa,
- roczna produkcja energii,
- dzienna temperatura powietrza,
- stan magazynu na koniec każdego miesiąca,
- liczba ludności według stanu na 31 grudnia kolejnych lat.
Szereg okresów i szereg momentów
Wśród szeregów czasowych wyróżnia się przede wszystkim szeregi okresów oraz szeregi momentów.
Szereg okresów dotyczy wielkości odnoszących się do całych odcinków czasu. Przykładem może być sprzedaż miesięczna, produkcja roczna albo liczba zgłoszeń w tygodniu.
Szereg momentów dotyczy natomiast stanu zjawiska w określonych punktach czasu, na przykład stanu magazynu na koniec miesiąca, liczby pracowników według stanu na dany dzień albo salda rachunku na koniec kwartału.
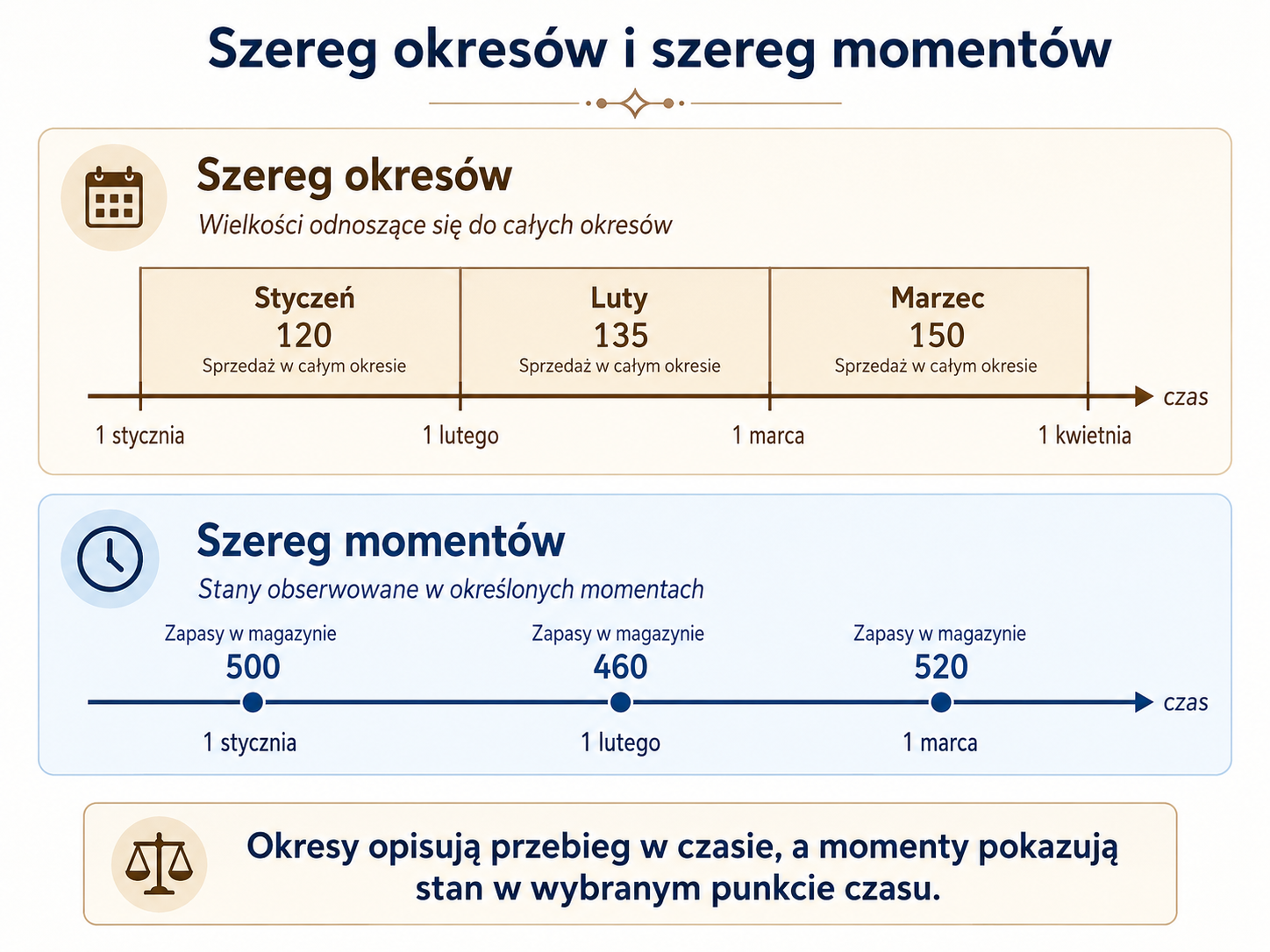
To rozróżnienie jest ważne również przy obliczaniu średnich. Dla szeregów momentów zwykła średnia arytmetyczna nie zawsze jest najwłaściwszym narzędziem. W niektórych sytuacjach stosuje się wtedy średnią chronologiczną, zwłaszcza gdy obserwacje dotyczą stanów w równych odstępach czasu.
Tablice statystyczne
Szeregi statystyczne bardzo często przyjmują postać tablic statystycznych. Dobrze przygotowana tablica nie tylko porządkuje dane, ale również ułatwia ich interpretację.
Dobra tablica statystyczna powinna zawierać:
- czytelny tytuł,
- jasno opisane wiersze i kolumny,
- jednostki miary, jeśli są potrzebne,
- w razie potrzeby źródło danych,
- ewentualne uwagi objaśniające.
W praktyce tablica bywa pierwszym etapem prezentacji danych, a dopiero później na jej podstawie tworzy się wykresy lub oblicza miary statystyczne.
Wykresy jako forma prezentacji danych
Dane statystyczne można prezentować nie tylko w tabelach, lecz także za pomocą wykresów. Dobór wykresu powinien być dostosowany do rodzaju danych i celu analizy.
Najczęściej spotyka się:
- wykres słupkowy — dla danych jakościowych lub skokowych,
- wykres kołowy — dla prezentacji struktury udziałów,
- histogram — dla danych pogrupowanych w przedziały,
- wykres liniowy — dla szeregów czasowych,
- wykres pudełkowy — do prezentacji mediany, kwartyli i obserwacji odstających.
Bardzo ważne jest odróżnienie wykresu słupkowego od histogramu. Są to dwa różne narzędzia, choć na pierwszy rzut oka mogą wyglądać podobnie.
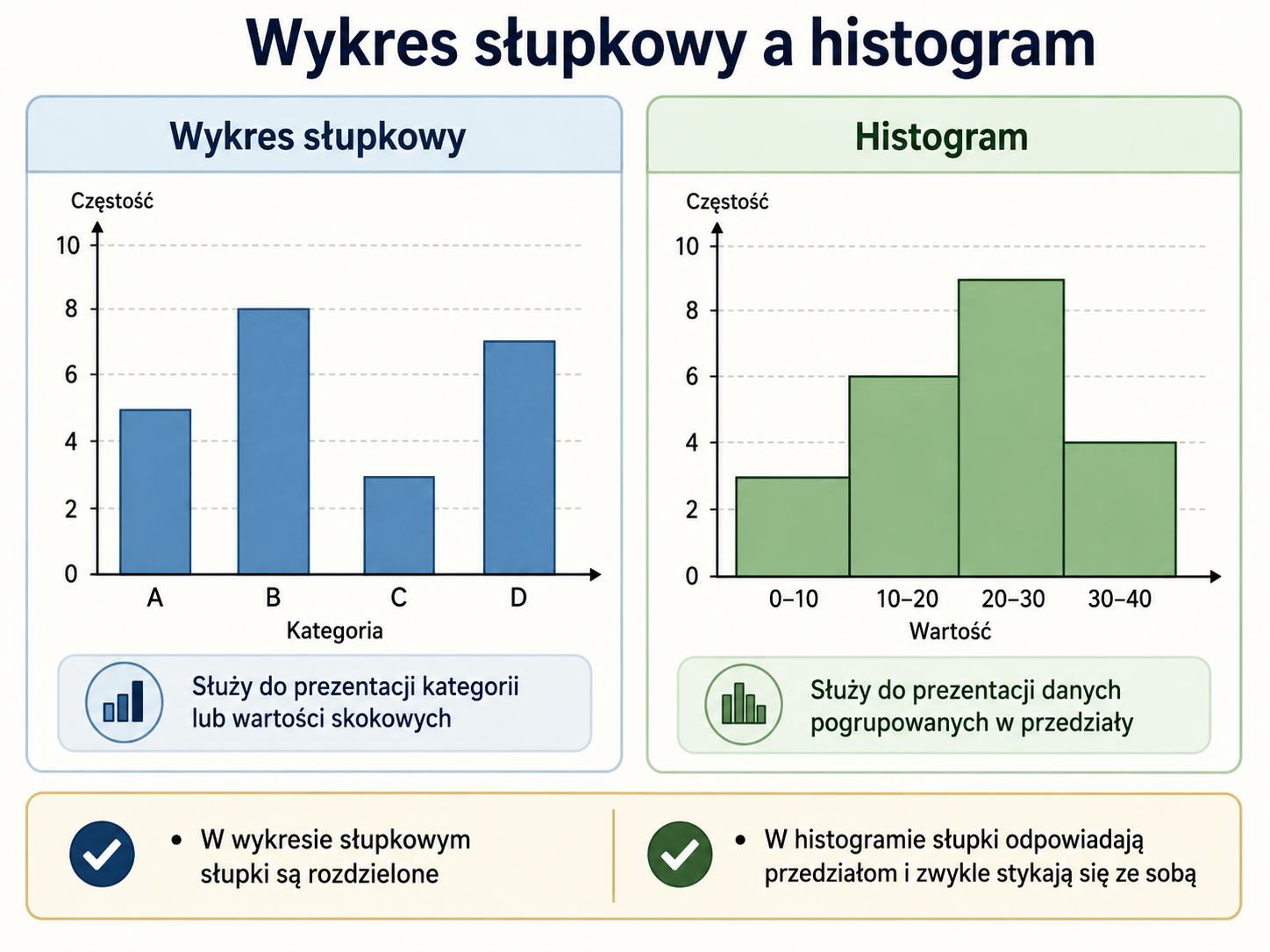
W wykresie słupkowym słupki odpowiadają oddzielnym kategoriom albo poszczególnym wartościom zmiennej skokowej. W histogramie słupki odpowiadają przedziałom wartości zmiennej, a ich sąsiedztwo ma znaczenie, ponieważ przedstawiają one ciągły zakres zmienności.
Dlaczego forma danych wpływa na obliczanie miar statystycznych?
Forma prezentacji danych wpływa nie tylko na czytelność, lecz także na sposób obliczania miar statystycznych.
Dla szeregu szczegółowego średnią arytmetyczną liczymy bezpośrednio z wszystkich obserwacji:
\[ \overline{x}=\frac{x_1+x_2+\dots+x_n}{n} \]
Dla szeregu rozdzielczego punktowego wykorzystujemy liczebności:
\[ \overline{x}=\frac{\sum x_i n_i}{\sum n_i} \]
Natomiast dla szeregu rozdzielczego przedziałowego często posługujemy się środkami przedziałów, a więc uzyskany wynik ma charakter przybliżony.
To pokazuje, że sposób uporządkowania danych nie jest obojętny. Dane w szeregu szczegółowym zachowują maksimum informacji, ale bywają nieczytelne. Dane pogrupowane są wygodniejsze do prezentacji i interpretacji, ale czasem trzeba zaakceptować pewne uproszczenie.
Krótkie zadanie dla czytelnika
Przyporządkuj poniższym sytuacjom odpowiedni rodzaj szeregu statystycznego:
- Lista wzrostów 12 uczniów klasy.
- Tabela liczby dzieci w rodzinie oraz liczby rodzin mających 0, 1, 2, 3 dzieci itd.
- Tabela dochodów podzielonych na klasy: 0 – 2000 zł, 2000 – 4000 zł, 4000 – 6000 zł itd.
- Miesięczna sprzedaż sklepu w kolejnych miesiącach roku.
- Stan magazynu na koniec każdego miesiąca.
Sprawdź odpowiedź
- Szereg szczegółowy — zapisujemy każdą obserwację osobno.
- Szereg rozdzielczy punktowy — mamy pojedyncze wartości zmiennej i odpowiadające im liczebności.
- Szereg rozdzielczy przedziałowy — dane zostały pogrupowane w przedziały klasowe.
- Szereg czasowy okresów — sprzedaż odnosi się do całych miesięcy.
- Szereg czasowy momentów — stan magazynu dotyczy określonych punktów czasu.
Podsumowanie
Szeregi statystyczne są podstawowym narzędziem porządkowania danych. Dzięki nim można przejść od surowej listy obserwacji do bardziej przejrzystych form prezentacji, takich jak tabele liczebności, przedziały klasowe czy szeregi czasowe.
Szereg szczegółowy zachowuje pełną informację o każdej obserwacji. Szereg rozdzielczy punktowy porządkuje dane skokowe przez zestawienie wartości i ich liczebności. Szereg rozdzielczy przedziałowy upraszcza dane przez grupowanie w klasy, co poprawia czytelność, ale wiąże się z częściową utratą informacji. Szereg czasowy pozwala natomiast analizować zmienność zjawisk w czasie.
W praktyce wybór formy prezentacji danych nie jest przypadkowy. Zależy od rodzaju zmiennej, liczby obserwacji, celu analizy oraz tego, czy ważniejsza jest pełna dokładność, czy raczej ogólny obraz rozkładu. Dlatego forma danych wpływa nie tylko na sposób ich prezentacji, ale również na późniejsze obliczanie i interpretację miar statystycznych.
Zrozumienie tych zależności stanowi ważny krok przed dalszym studiowaniem miar położenia, miar zróżnicowania, asymetrii i koncentracji. To właśnie z dobrze uporządkowanych danych zaczyna się rzetelna analiza statystyczna.
Utworzono: 04.06.2026 | Zmodyfikowano: 21.06.2026
Powiązane artykuły
- Miary statystyczne w statystyce opisowej
- Rodzaje danych statystycznych: zmienne jakościowe, skokowe i ciągłe
- Miary położenia, statystyka opisowa, średnia, mediana, dominanta, kwartyle.
- Miary zróżnicowania w statystyce opisowej — rozstęp, wariancja i odchylenie standardowe
- Miary asymetrii w statystyce opisowej — asymetria prawostronna i lewostronna
- Indeksy dynamiki, przyrosty i średnie tempo zmian
- Kurtoza, eksces i koncentracja w statystyce opisowej
- Kwantyle w szeregu szczegółowym
- Średnia niejedno ma imię
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc