
Miary statystyczne w statystyce opisowej
Miary statystyczne pozwalają opisać dane za pomocą kilku liczb. Dzięki nim można odpowiedzieć na pytania: jaka wartość jest typowa, jak bardzo dane są zróżnicowane, czy rozkład jest symetryczny, czy występują wartości skrajne i czy obserwacje są silnie skoncentrowane wokół określonego poziomu.
Statystyka opisowa nie polega wyłącznie na tworzeniu tabel i wykresów. Jej bardzo ważną częścią jest wyznaczanie miar statystycznych, czyli liczbowych charakterystyk badanego zbioru danych. Jedna dobrze dobrana miara może ułatwić interpretację danych, ale źle dobrana może prowadzić do mylących wniosków.
Dlatego przed liczeniem średniej, mediany, odchylenia standardowego czy współczynnika asymetrii warto zrozumieć, co dana miara opisuje, dla jakich danych ma sens oraz jak zmienia się jej interpretacja w zależności od sposobu uporządkowania danych. Jeśli potrzebujesz przypomnienia podstawowego podziału zmiennych, zobacz artykuł rodzaje danych statystycznych. Warto też znać artykuł szeregi statystyczne i formy prezentacji danych, ponieważ inaczej oblicza się miary dla danych szczegółowych, a inaczej dla danych pogrupowanych.
Spis treści
- Po co stosuje się miary statystyczne?
- Czym są miary statystyczne?
- Główne grupy miar statystycznych
- Miary położenia
- Miary zróżnicowania
- Miary asymetrii
- Kurtoza, eksces i kształt rozkładu
- Miary koncentracji
- Miary klasyczne i pozycyjne — drugi, niezależny podział
- Miary absolutne i względne
- Dobór miar do rodzaju danych
- Dobór miar do formy szeregu statystycznego
- Najczęstsze błędy interpretacyjne
- Krótkie zadanie dla czytelnika
- Podsumowanie
Po co stosuje się miary statystyczne?
Surowe dane mogą być trudne do ogarnięcia. Lista kilkudziesięciu wyników, cen, dochodów, ocen albo czasów oczekiwania sama w sobie często nie mówi jeszcze, jaki jest ogólny obraz zjawiska. Miary statystyczne pozwalają ten obraz streścić.
Za pomocą miar statystycznych można między innymi:
- wskazać typowy poziom zjawiska,
- porównać kilka zbiorowości między sobą,
- ocenić stopień zróżnicowania danych,
- sprawdzić, czy rozkład jest symetryczny,
- zauważyć wpływ obserwacji skrajnych,
- opisać koncentrację wartości w zbiorowości.
Trzeba jednak pamiętać, że żadna pojedyncza miara nie opisuje danych w pełni. Średnia może dobrze oddawać przeciętny poziom, ale nie pokaże, czy dane są silnie rozproszone. Odchylenie standardowe pokaże zróżnicowanie, ale nie powie, po której stronie rozkładu znajduje się dłuższy ogon. Dlatego w praktyce analizuje się zwykle kilka miar jednocześnie.
Czym są miary statystyczne?
Miary statystyczne to liczbowe charakterystyki zbioru danych. Ich zadaniem jest opisanie wybranej cechy rozkładu, na przykład jego położenia, zmienności, asymetrii, spłaszczenia albo koncentracji.
Można powiedzieć, że miary statystyczne zamieniają dużą liczbę obserwacji na krótką informację liczbową. Przykładowo zamiast wypisywać wszystkie oceny w grupie, możemy podać średnią, medianę, dominantę, odchylenie standardowe i rozstęp. Każda z tych liczb mówi jednak o czymś innym.
Ważna uwaga
Miara statystyczna nie jest celem samym w sobie. Jest narzędziem interpretacji danych. Dlatego nie wystarczy znać wzór. Trzeba jeszcze wiedzieć, co dana miara oznacza, kiedy warto ją stosować i kiedy może być myląca.
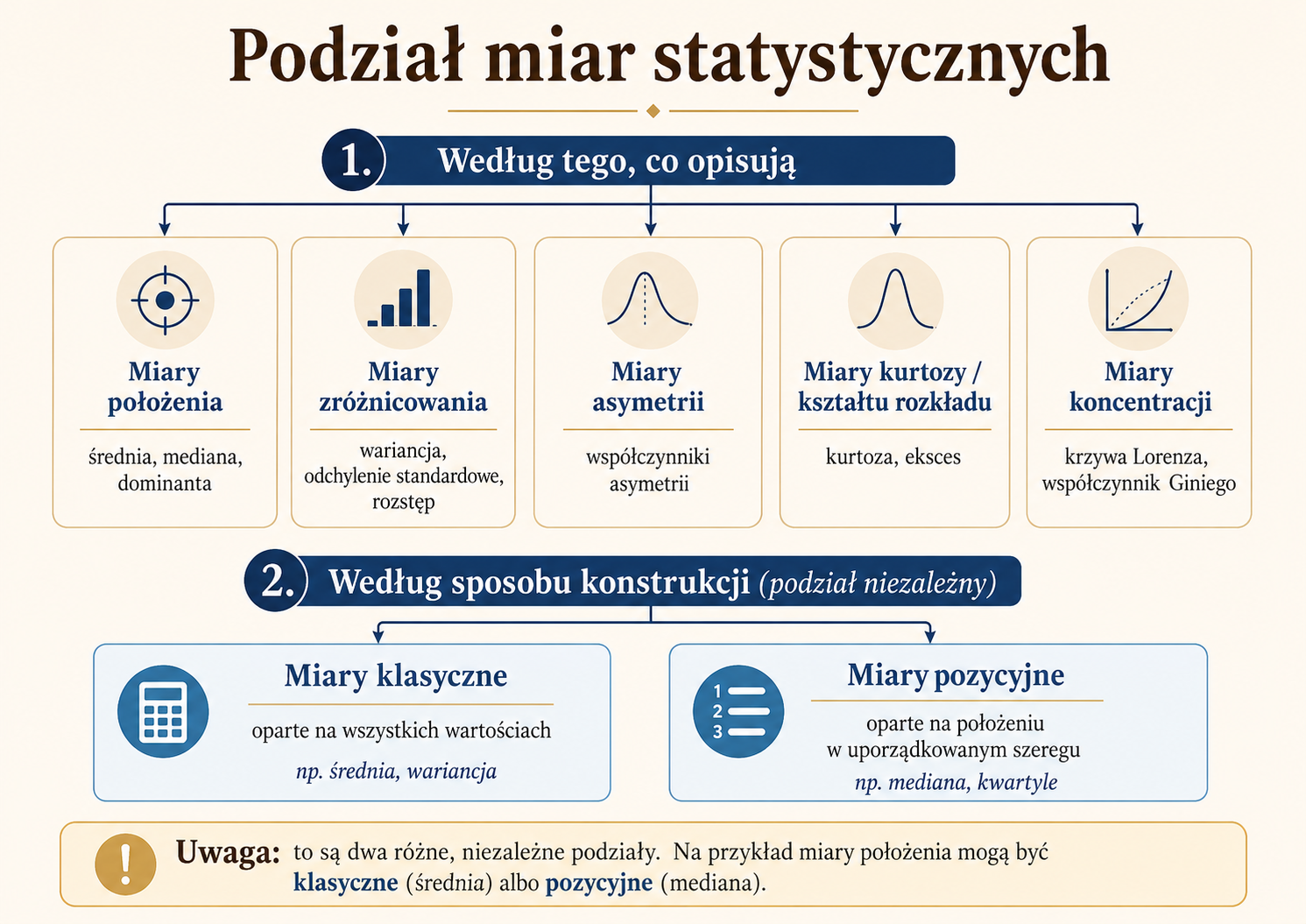
Główne grupy miar statystycznych
Najbardziej naturalny podział miar statystycznych wynika z pytania: co dana miara opisuje? W tym ujęciu wyróżnia się kilka podstawowych grup.
| Grupa miar | Na jakie pytanie odpowiada? | Przykłady |
|---|---|---|
| Miary położenia | Gdzie znajduje się typowa lub centralna wartość? | średnia, mediana, dominanta, kwartyle |
| Miary zróżnicowania | Jak bardzo wartości różnią się między sobą? | rozstęp, wariancja, odchylenie standardowe, współczynnik zmienności |
| Miary asymetrii | Czy rozkład jest symetryczny, czy ma dłuższy ogon z jednej strony? | współczynniki asymetrii |
| Miary spłaszczenia / kurtozy | Czy rozkład jest bardziej skupiony czy bardziej spłaszczony? | kurtoza, eksces |
| Miary koncentracji | Czy suma cechy jest skupiona w niewielkiej części zbiorowości? | krzywa Lorenza, współczynnik Giniego |
Miary położenia
Miary położenia opisują, gdzie znajduje się typowa, środkowa albo charakterystyczna wartość w zbiorze danych. Są one zwykle pierwszymi miarami, z którymi spotykamy się w statystyce opisowej.
Do najważniejszych miar położenia należą:
- średnia arytmetyczna — suma wartości podzielona przez ich liczbę,
- mediana — wartość dzieląca uporządkowany zbiór danych na dwie połowy,
- dominanta — wartość występująca najczęściej,
- kwartyle — wartości dzielące uporządkowany zbiór na cztery części,
- kwantyle — uogólnienie idei mediany, kwartyli, decyli i percentyli.
Najbardziej znaną miarą położenia jest średnia arytmetyczna. Jest wygodna i często intuicyjna, ale bywa wrażliwa na obserwacje odstające. Jeśli w małej grupie kilka osób zarabia bardzo dużo, średnia pensja może być znacznie wyższa niż wynagrodzenie większości osób. W takiej sytuacji mediana często lepiej opisuje typowy poziom zjawiska.
Dominanta jest szczególnie użyteczna przy danych jakościowych i skokowych, ponieważ wskazuje najczęściej występującą kategorię albo wartość. Przy danych ciągłych mierzonych z dużą dokładnością dominanta w szeregu szczegółowym może być mniej użyteczna, dlatego często analizuje się wtedy przedziały największej koncentracji obserwacji.
Miary zróżnicowania
Miary zróżnicowania, nazywane też miarami rozproszenia lub dyspersji, opisują, jak bardzo wartości różnią się między sobą. Dwie grupy mogą mieć taką samą średnią, ale zupełnie inne zróżnicowanie.
Przykładowo w dwóch grupach średni wynik sprawdzianu może wynosić 70%. W pierwszej grupie większość uczniów mogła uzyskać wyniki od 65% do 75%, a w drugiej wyniki mogły rozciągać się od 30% do 100%. Sama średnia nie pokaże tej różnicy. Potrzebne są miary zróżnicowania.
Do najważniejszych miar zróżnicowania należą:
- rozstęp — różnica między wartością największą i najmniejszą,
- rozstęp międzykwartylowy — różnica między trzecim i pierwszym kwartylem,
- odchylenie ćwiartkowe — połowa rozstępu międzykwartylowego,
- wariancja — średnia kwadratów odchyleń od średniej,
- odchylenie standardowe — pierwiastek z wariancji,
- współczynnik zmienności — względna miara zróżnicowania.
Miary zróżnicowania są niezbędne wtedy, gdy chcemy ocenić stabilność, jednorodność albo ryzyko. W finansach zróżnicowanie wyników może oznaczać ryzyko, w produkcji — niestabilność procesu, a w dydaktyce — duże różnice poziomu uczniów.
Miary asymetrii
Miary asymetrii opisują, czy rozkład wartości jest symetryczny, czy też bardziej rozciągnięty w jedną stronę. Asymetria jest związana z położeniem ogona rozkładu.
Jeżeli większość wartości jest raczej niska, ale występuje kilka bardzo wysokich obserwacji, mówimy zwykle o asymetrii prawostronnej. Przykładem mogą być dochody, ceny mieszkań albo wartości transakcji. Nieliczne bardzo wysokie wartości przesuwają średnią w górę.
Jeżeli natomiast większość wartości jest wysoka, ale pojawia się kilka bardzo niskich obserwacji, można mówić o asymetrii lewostronnej. W praktyce asymetrię można oceniać graficznie, porównując średnią z medianą albo wyznaczając odpowiednie współczynniki asymetrii.
Miary asymetrii pomagają zrozumieć, dlaczego sama średnia może nie wystarczać. W rozkładzie silnie asymetrycznym średnia może być przesunięta w stronę wartości skrajnych i nie musi dobrze reprezentować typowej obserwacji.
Kurtoza, eksces i kształt rozkładu
Kurtoza jest miarą opisującą pewne cechy kształtu rozkładu, zwłaszcza związane ze skupieniem wartości oraz ogonami rozkładu. W wielu kursach statystyki omawia się ją razem z pojęciem ekscesu, czyli kurtozy porównanej z rozkładem normalnym.
W uproszczeniu można powiedzieć, że eksces pomaga określić, czy rozkład jest bardziej „wysmukły” albo bardziej „spłaszczony” w porównaniu z rozkładem normalnym. Trzeba jednak uważać z potoczną interpretacją tej miary, ponieważ w praktyce kurtoza jest silnie związana z zachowaniem ogonów rozkładu i obserwacjami skrajnymi.
Na poziomie przeglądowym najważniejsze jest zapamiętanie, że kurtoza i eksces nie opisują położenia ani zwykłego zróżnicowania danych. Są to miary dotyczące kształtu rozkładu, dlatego powinny być interpretowane razem z wykresem, miarami położenia i miarami zróżnicowania.
Miary koncentracji
Miary koncentracji opisują, w jakim stopniu suma badanej cechy jest skupiona w części zbiorowości. Są szczególnie ważne w ekonomii, finansach, demografii i badaniach społecznych.
Klasycznym przykładem jest analiza dochodów. Możemy zapytać, czy łączny dochód w społeczeństwie jest rozłożony dość równomiernie, czy też duża jego część przypada niewielkiej grupie osób. Podobnie można analizować koncentrację sprzedaży, majątku, udziałów rynkowych albo produkcji.
Uwaga: nie należy mylić dwóch znaczeń koncentracji. W artykule o kurtozie, ekscesie i koncentracji chodzi o koncentrację rozkładu wokół środka oraz zachowanie ogonów. W przypadku krzywej Lorenza i współczynnika Giniego chodzi natomiast o koncentrację sumy wartości cechy między jednostkami.
Do najbardziej znanych narzędzi opisu koncentracji należą:
Miary koncentracji są zwykle omawiane jako osobna grupa narzędzi, ponieważ odpowiadają na nieco inne pytanie niż średnia, mediana czy odchylenie standardowe. Interesuje nas nie tylko rozproszenie pojedynczych wartości, ale także to, jak rozłożona jest suma analizowanej cechy.
Miary klasyczne i pozycyjne — drugi, niezależny podział
W podręcznikach statystyki często spotyka się także podział na miary klasyczne i miary pozycyjne. Bardzo ważne jest jednak to, że jest to inny porządek klasyfikacji niż podział na miary położenia, zróżnicowania, asymetrii, kurtozy i koncentracji.
Podział według grup odpowiada na pytanie: co dana miara opisuje? Natomiast podział na miary klasyczne i pozycyjne odpowiada na pytanie: jak dana miara jest konstruowana?
Są to więc dwa różne, krzyżujące się porządki klasyfikacji. Na przykład wśród miar położenia możemy mieć zarówno miary klasyczne, jak średnia arytmetyczna, jak i miary pozycyjne, takie jak mediana czy kwartyle. Podobnie wśród miar zróżnicowania możemy mieć klasyczne odchylenie standardowe oraz pozycyjny rozstęp międzykwartylowy.
| Grupa miar | Przykłady miar klasycznych | Przykłady miar pozycyjnych |
|---|---|---|
| Miary położenia | średnia arytmetyczna, średnia geometryczna | mediana, dominanta, kwartyle |
| Miary zróżnicowania | wariancja, odchylenie standardowe, odchylenie przeciętne | rozstęp, rozstęp międzykwartylowy, odchylenie ćwiartkowe |
| Miary asymetrii | klasyczny współczynnik asymetrii | pozycyjne współczynniki asymetrii, na przykład kwartylowy |
| Miary kurtozy | klasyczny współczynnik kurtozy, eksces | rzadziej stosowane miary oparte na kwantylach |
| Miary koncentracji | krzywa Lorenza i współczynnik Giniego są zwykle omawiane jako osobna grupa narzędzi | |
Nie myl dwóch podziałów
Miary położenia, zróżnicowania, asymetrii, kurtozy i koncentracji tworzą podział według tego, co opisujemy. Miary klasyczne i pozycyjne tworzą podział według tego, jak budujemy miarę. To nie są dwa poziomy jednej hierarchii, lecz dwa niezależne sposoby porządkowania tych samych narzędzi statystycznych.
Miary klasyczne są zwykle oparte na wszystkich wartościach obserwacji i często wykorzystują średnią arytmetyczną. Przykładami są średnia, wariancja i odchylenie standardowe. Ich zaletą jest to, że uwzględniają całość danych, ale wadą może być wrażliwość na obserwacje odstające.
Miary pozycyjne wynikają z położenia wartości w uporządkowanym szeregu. Przykładami są mediana, kwartyle, decyle, percentyle i rozstęp międzykwartylowy. Ich zaletą jest większa odporność na wartości skrajne, dlatego często są przydatne przy rozkładach asymetrycznych.
Miary absolutne i względne
Innym użytecznym rozróżnieniem jest podział na miary absolutne i miary względne. Miary absolutne są wyrażone w jednostkach badanej cechy albo w jednostkach pochodnych. Miary względne są najczęściej bezwymiarowe albo wyrażone procentowo.
Przykładowo odchylenie standardowe czasu dojazdu do pracy może być wyrażone w minutach. To miara absolutna. Współczynnik zmienności pokazuje natomiast zróżnicowanie w relacji do średniego poziomu i często podaje się go w procentach. Dzięki temu można porównywać zmienność cech mierzonych w różnych jednostkach albo o różnych poziomach średnich.
Miary względne są szczególnie przydatne wtedy, gdy samo odchylenie w jednostkach naturalnych nie wystarcza do porównania. Odchylenie standardowe równe 10 zł może mieć inne znaczenie przy średniej 50 zł, a inne przy średniej 5000 zł.
Dobór miar do rodzaju danych
Nie każda miara statystyczna ma sens dla każdego rodzaju danych. Dobór miary zależy między innymi od tego, czy mamy dane jakościowe, porządkowe, skokowe czy ciągłe.
| Rodzaj danych | Przykładowe właściwe miary | Uwagi interpretacyjne |
|---|---|---|
| Dane nominalne | liczebności, częstości, dominanta, struktura procentowa | Nie ma naturalnego porządku kategorii, więc nie liczymy średniej. |
| Dane porządkowe | mediana, kwartyle, dominanta, częstości | Można porządkować kategorie, ale odległości między nimi nie muszą być równe. |
| Dane ilościowe skokowe | średnia, mediana, dominanta, wariancja, odchylenie standardowe | Dobór zależy od liczby wartości, skali i kształtu rozkładu. |
| Dane ilościowe ciągłe | średnia, mediana, kwartyle, odchylenie standardowe, współczynnik zmienności | Przy silnej asymetrii warto porównywać średnią z medianą. |
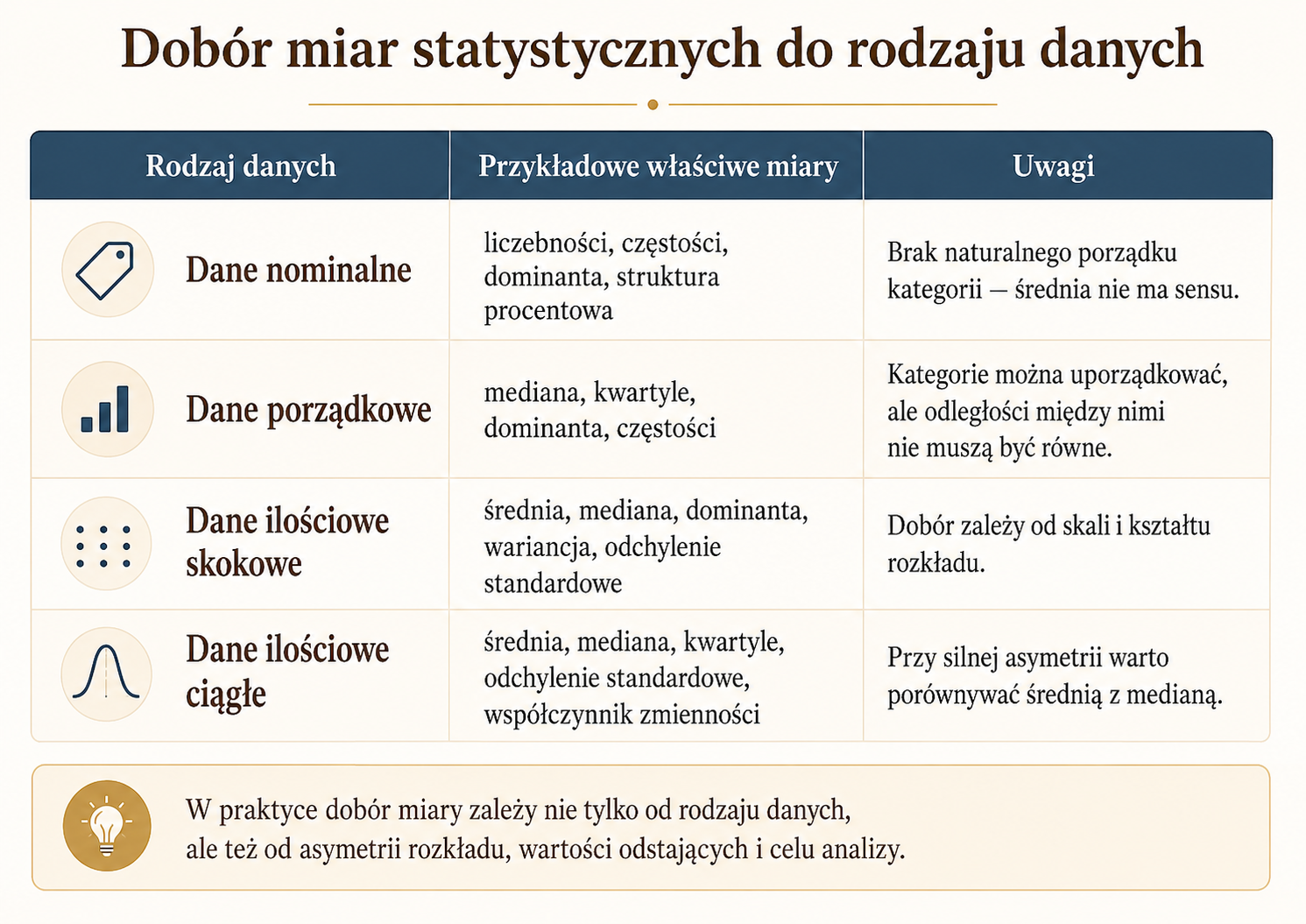
Przykładowo dla koloru oczu można wskazać najczęściej występującą kategorię, ale liczenie średniego koloru oczu nie ma sensu. Dla ocen wyrażonych opisowo, takich jak „niska”, „średnia”, „wysoka”, można mówić o medianie kategorii, ale trzeba ostrożnie interpretować odległości między poziomami. Dla danych liczbowych możliwości analizy są szersze, ale nadal trzeba uwzględniać asymetrię, wartości odstające i sposób pomiaru.
Dobór miar do formy szeregu statystycznego
Znaczenie ma nie tylko rodzaj danych, lecz także forma ich zapisu. Te same obserwacje można przedstawić jako szereg szczegółowy, szereg rozdzielczy punktowy albo szereg rozdzielczy przedziałowy. Od tego zależy sposób obliczeń.
Dla szeregu szczegółowego miary oblicza się bezpośrednio z pojedynczych obserwacji. Dla szeregu rozdzielczego punktowego trzeba uwzględnić liczebności poszczególnych wartości. Dla szeregu rozdzielczego przedziałowego często korzysta się ze środków przedziałów, dlatego wyniki mają charakter przybliżony.
| Forma danych | Sposób liczenia miar | Charakter wyniku |
|---|---|---|
| Szereg szczegółowy | bezpośrednio z obserwacji | najpełniejsze wykorzystanie danych |
| Szereg rozdzielczy punktowy | z uwzględnieniem liczebności wartości | wynik dokładny dla podanych wartości i liczebności |
| Szereg rozdzielczy przedziałowy | zwykle z użyciem środków przedziałów | wynik przybliżony |
| Szereg czasowy | zależnie od tego, czy jest to szereg okresów czy momentów | wymaga interpretacji czasowej |
To szczególnie ważne przy danych pogrupowanych w przedziały. Jeśli wiemy tylko, że dana osoba znajduje się w przedziale dochodów od 4000 do 6000 zł, nie znamy jej dokładnego dochodu. Obliczenia oparte na środku przedziału są wtedy wygodnym przybliżeniem, ale nie są tym samym, co obliczenia z pełnych danych szczegółowych.
Najczęstsze błędy interpretacyjne
Przy stosowaniu miar statystycznych często pojawiają się podobne błędy. Warto je znać, ponieważ mogą prowadzić do błędnych wniosków nawet wtedy, gdy same obliczenia są wykonane poprawnie.
- Utożsamianie średniej z typową wartością — średnia może być myląca przy silnej asymetrii lub obserwacjach odstających.
- Liczenie średniej dla danych nominalnych — nie każdą kategorię można sensownie uśredniać.
- Pomijanie zróżnicowania — dwie grupy mogą mieć taką samą średnią, ale zupełnie inną zmienność.
- Ignorowanie formy szeregu — miary z danych przedziałowych często są przybliżone.
- Mylenie podziałów miar — miary klasyczne i pozycyjne to inny podział niż miary położenia, zróżnicowania czy asymetrii.
- Interpretowanie jednej miary bez kontekstu — najlepiej analizować kilka miar wraz z tabelą lub wykresem.
Dobra analiza statystyczna polega nie tylko na podstawieniu liczb do wzoru, ale przede wszystkim na rozumieniu, co wynik oznacza i jakie ma ograniczenia.
Krótkie zadanie dla czytelnika
Dopasuj do każdej sytuacji grupę miar, która będzie szczególnie potrzebna w analizie:
- Chcemy wskazać typową wartość wynagrodzenia w firmie.
- Chcemy sprawdzić, czy wyniki uczniów są do siebie podobne, czy bardzo rozproszone.
- Chcemy ocenić, czy kilka bardzo wysokich dochodów zawyża średnią.
- Chcemy zbadać, czy duża część sprzedaży przypada niewielkiej grupie klientów.
- Chcemy porównać zmienność dwóch cech mierzonych w różnych jednostkach.
Sprawdź odpowiedź
- Miary położenia — na przykład mediana lub średnia, zależnie od rozkładu wynagrodzeń.
- Miary zróżnicowania — na przykład odchylenie standardowe, rozstęp lub rozstęp międzykwartylowy.
- Miary asymetrii oraz porównanie średniej z medianą.
- Miary koncentracji — na przykład krzywa Lorenza lub współczynnik Giniego.
- Miary względne — szczególnie współczynnik zmienności.
Podsumowanie
Miary statystyczne są podstawowym narzędziem statystyki opisowej. Pozwalają streścić dane, porównać zbiorowości i opisać najważniejsze cechy rozkładu. Nie wszystkie miary odpowiadają jednak na to samo pytanie.
Miary położenia opisują typowy lub centralny poziom wartości. Miary zróżnicowania informują o rozproszeniu danych. Miary asymetrii pomagają ocenić, czy rozkład jest symetryczny. Kurtoza i eksces dotyczą kształtu rozkładu, a miary koncentracji pokazują, czy suma cechy jest skupiona w części zbiorowości.
Niezależnie od tego można dzielić miary na klasyczne i pozycyjne. Ten podział nie konkuruje z podziałem na miary położenia, zróżnicowania czy asymetrii. Jest to drugi sposób patrzenia na te same narzędzia: według sposobu ich konstrukcji.
W praktyce najważniejsze jest nie tylko poprawne obliczenie miary, ale także jej właściwy dobór i interpretacja. Trzeba uwzględniać rodzaj danych, formę szeregu statystycznego, obecność wartości odstających, asymetrię rozkładu oraz cel analizy. Dopiero wtedy miary statystyczne stają się rzeczywistą pomocą w rozumieniu danych, a nie tylko zbiorem wzorów do zapamiętania.
Utworzono: 04.06.2026 | Zmodyfikowano: 21.06.2026
Powiązane artykuły
- Szeregi statystyczne i formy prezentacji danych
- Rodzaje danych statystycznych: zmienne jakościowe, skokowe i ciągłe
- Miary położenia, statystyka opisowa, średnia, mediana, dominanta, kwartyle.
- Średnia niejedno ma imię
- Miary zróżnicowania w statystyce opisowej — rozstęp, wariancja i odchylenie standardowe
- Miary asymetrii w statystyce opisowej — asymetria prawostronna i lewostronna
- Odchylenie standardowe i wariancja, jako miary rozrzutu
- Kwantyle w szeregu szczegółowym
- Kurtoza, eksces i koncentracja w statystyce opisowej
- Estymacja wartości oczekiwanej (średniej) — estymacja punktowa i przedziałowa
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc