
Miary położenia, statystyka opisowa, średnia, mediana, dominanta, kwartyle.
Miary położenia odpowiadają na jedno z najważniejszych pytań statystyki opisowej: gdzie „leży” badane zjawisko? Czy typowa wartość jest niska, wysoka, przeciętna, a może rozkład danych jest tak nierównomierny, że jedna liczba nie wystarcza do jego opisania?
Gdy analizujemy dane, bardzo często pierwszym odruchem jest obliczenie średniej. Jest to naturalne, ponieważ średnia arytmetyczna jest jedną z najbardziej znanych miar statystycznych. Nie zawsze jednak jest najlepsza. Czasem lepiej posłużyć się medianą, czasem dominantą, a w niektórych sytuacjach warto spojrzeć na kwartyle, decyle lub percentyle.
Ten artykuł jest szczegółowym rozwinięciem ogólnego omówienia miar statystycznych. Szerszy podział miar na miary położenia, rozproszenia, asymetrii i koncentracji znajduje się w artykule Miary statystyczne w statystyce opisowej.
W tym tekście omawiamy dokładniej najważniejsze miary położenia: średnią arytmetyczną, średnią ważoną, medianę, dominantę oraz kwantyle. Pokazujemy, jak je interpretować, kiedy je stosować i jakie błędy najczęściej pojawiają się przy ich używaniu.
Czym są miary położenia?
Miary położenia to miary statystyczne, które opisują, w jakim miejscu na osi liczbowej znajduje się badany zbiór danych. Innymi słowy, pomagają określić poziom typowy, przeciętny albo charakterystyczny dla analizowanego zjawiska.
Miary położenia to miary opisujące położenie rozkładu wartości badanej cechy. Informują, wokół jakiego poziomu koncentrują się dane albo poniżej jakiej wartości znajduje się określona część obserwacji.
Przykładowo, jeżeli analizujemy wynagrodzenia w grupie pracowników, miary położenia mogą odpowiedzieć na pytania:
- ile przeciętnie zarabia pracownik,
- ile wynosi wynagrodzenie środkowego pracownika po uporządkowaniu wszystkich wynagrodzeń,
- jakie wynagrodzenie występuje najczęściej,
- poniżej jakiego wynagrodzenia znajduje się 25%, 50% lub 75% pracowników.
Warto zauważyć, że nie wszystkie miary położenia działają w ten sam sposób. Niektóre wykorzystują wszystkie wartości w zbiorze, inne opierają się przede wszystkim na uporządkowaniu obserwacji.
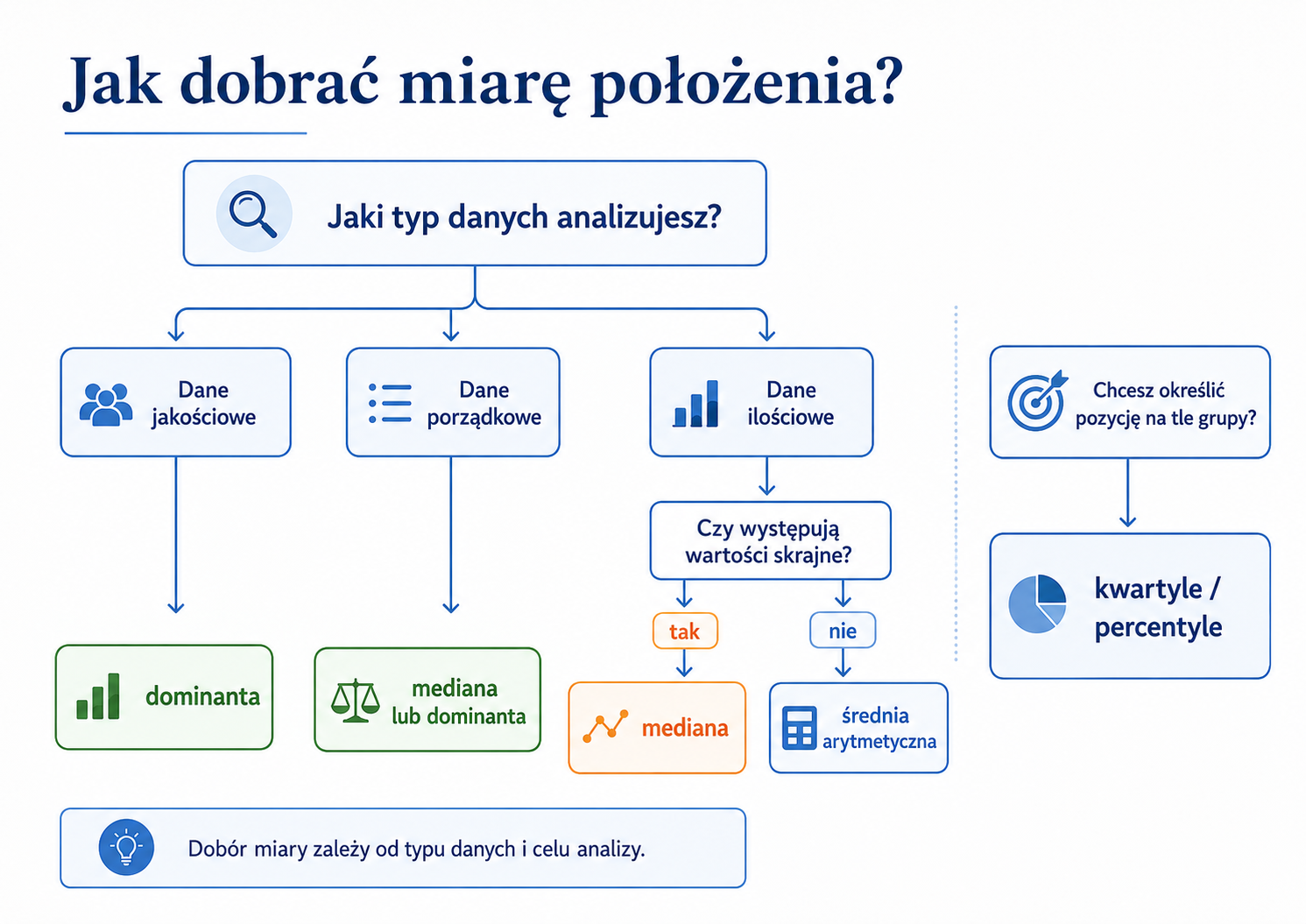
Miary położenia a miary pozycyjne
W praktyce dydaktycznej warto rozróżnić dwa pojęcia: miary położenia oraz miary pozycyjne. Brzmią podobnie, ale nie oznaczają dokładnie tego samego.
Miary położenia to szeroka grupa miar opisujących poziom, wokół którego znajdują się dane. Należą do nich między innymi średnia, mediana, dominanta oraz kwartyle.
Miary pozycyjne to takie miary, które wyznacza się na podstawie pozycji wartości w uporządkowanym szeregu. Do tej grupy należą przede wszystkim mediana, kwartyle, decyle i percentyle.
Uwaga: każda miara pozycyjna jest miarą położenia, ale nie każda miara położenia jest miarą pozycyjną. Średnia arytmetyczna jest miarą położenia, ale nie jest miarą pozycyjną, ponieważ nie wynika z pozycji obserwacji po uporządkowaniu danych.
Najważniejsze miary położenia
Najczęściej stosowane miary położenia można uporządkować następująco:
| Miara | Inna nazwa | Co opisuje? | Czy jest odporna na wartości skrajne? |
|---|---|---|---|
| Średnia arytmetyczna | średnia klasyczna | przeciętny poziom wartości | nie |
| Średnia ważona | średnia z wagami | przeciętny poziom przy różnej ważności obserwacji | nie |
| Mediana | wartość środkowa | wartość dzielącą uporządkowany zbiór na dwie części | tak |
| Dominanta | moda, wartość modalna | wartość występującą najczęściej | częściowo |
| Kwartyle | \(Q_1\), \(Q_2\), \(Q_3\) | wartości dzielące zbiór na cztery części | tak |
| Percentyle | centyle | wartości dzielące zbiór na sto części | tak |
Średnia arytmetyczna
Średnia arytmetyczna jest najczęściej stosowaną miarą przeciętnego poziomu zjawiska. Obliczamy ją przez dodanie wszystkich wartości i podzielenie otrzymanej sumy przez liczbę obserwacji.
Średnia arytmetyczna jest tylko jednym z wielu rodzajów średnich. Szerzej o średniej arytmetycznej, ważonej, geometrycznej, harmonicznej i innych sposobach rozumienia przeciętnego poziomu piszemy w artykule Średnia niejedno ma imię.
Wzór na średnią arytmetyczną:
\[ \bar{x}=\frac{x_1+x_2+\ldots+x_n}{n} \]
gdzie:
- \(\bar{x}\) — średnia arytmetyczna,
- \(x_1, x_2, \ldots, x_n\) — kolejne wartości cechy,
- \(n\) — liczba obserwacji.
Przykład obliczania średniej arytmetycznej
Załóżmy, że mamy następujące wyniki sprawdzianu:
\[ 2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 10 \]
Suma wartości wynosi:
\[ 2+4+4+5+7+8+10=40 \]
Liczba obserwacji wynosi \(7\), więc:
\[ \bar{x}=\frac{40}{7}\approx 5{,}71 \]
Średni wynik sprawdzianu wynosi więc około 5,71 punktu.
Zalety średniej arytmetycznej
- jest prosta do obliczenia,
- wykorzystuje wszystkie wartości w zbiorze,
- ma duże znaczenie w dalszych analizach statystycznych,
- dobrze opisuje dane o w miarę symetrycznym rozkładzie.
Wady średniej arytmetycznej
Podstawową wadą średniej arytmetycznej jest jej wrażliwość na wartości skrajne. Jedna bardzo duża albo bardzo mała wartość może silnie przesunąć średnią i sprawić, że przestanie ona dobrze opisywać typowy poziom zjawiska.
Rozważmy dwa zbiory danych:
| Zbiór | Wartości | Średnia |
|---|---|---|
| A | \(2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 10\) | \(5{,}71\) |
| B | \(2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 100\) | \(18{,}57\) |
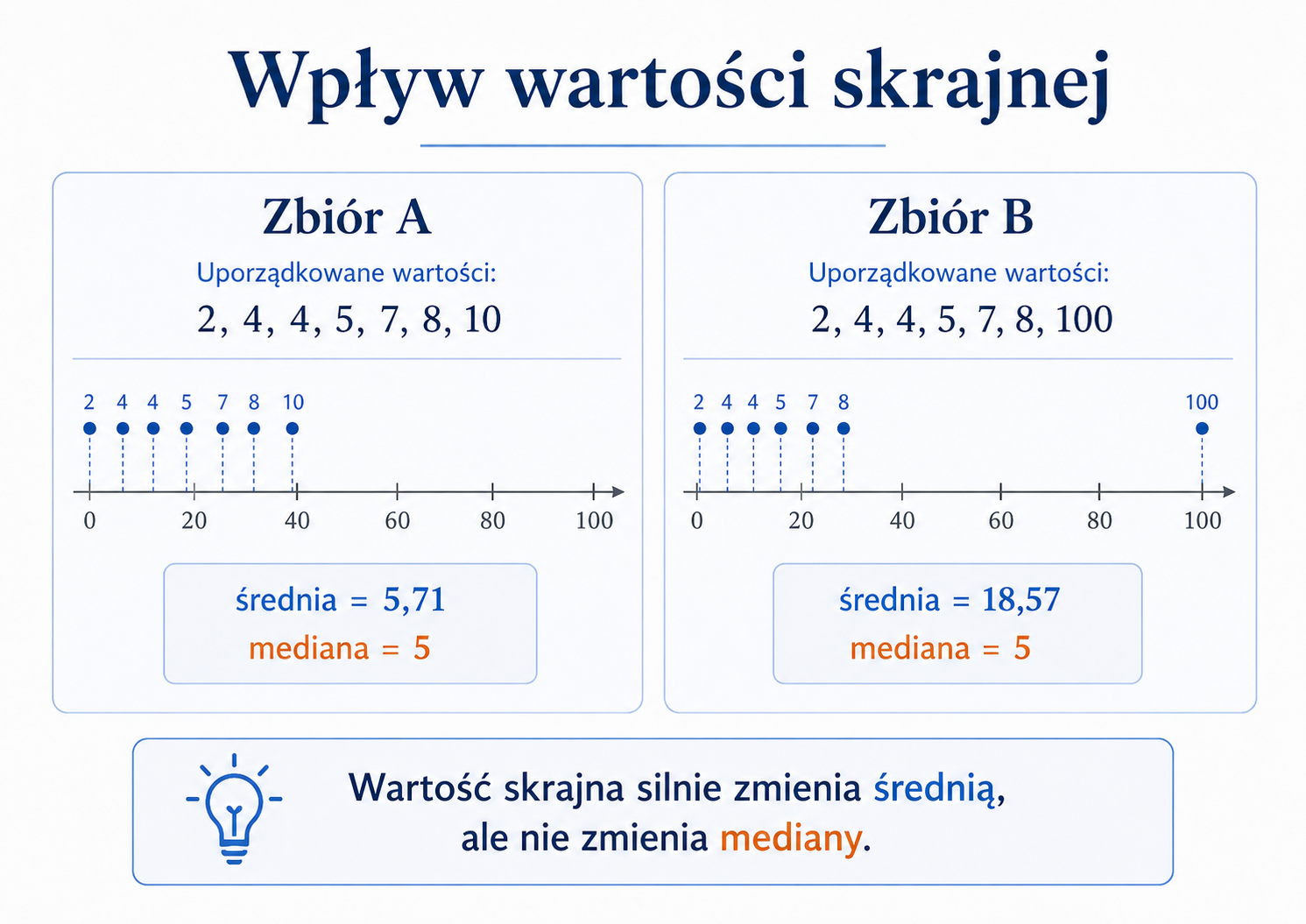
W drugim zbiorze tylko jedna wartość została zmieniona z \(10\) na \(100\), ale średnia wzrosła z \(5{,}71\) do \(18{,}57\). Widzimy więc, że średnia może być myląca, gdy w danych występują wartości odstające.
Średnia ważona
Średnia ważona jest odmianą średniej arytmetycznej stosowaną wtedy, gdy poszczególne wartości mają różną wagę, czyli różne znaczenie lub różną częstość występowania. Jej szczegółowe zastosowania można traktować jako część szerszego tematu różnych rodzajów średnich, omówionego w artykule Średnia niejedno ma imię.
Wzór na średnią ważoną:
\[ \bar{x}_w=\frac{x_1w_1+x_2w_2+\ldots+x_nw_n}{w_1+w_2+\ldots+w_n} \]
gdzie:
- \(x_i\) — wartość cechy,
- \(w_i\) — waga przypisana danej wartości.
Przykład średniej ważonej
Uczeń otrzymał następujące oceny:
| Ocena | Waga | Iloczyn oceny i wagi |
|---|---|---|
| \(3\) | \(1\) | \(3\) |
| \(4\) | \(2\) | \(8\) |
| \(5\) | \(3\) | \(15\) |
Suma iloczynów ocen i wag wynosi:
\[ 3+8+15=26 \]
Suma wag wynosi:
\[ 1+2+3=6 \]
Średnia ważona wynosi:
\[ \bar{x}_w=\frac{26}{6}\approx 4{,}33 \]
Średnia ważona jest wyższa od zwykłej średniej arytmetycznej z ocen \(3\), \(4\) i \(5\), ponieważ najwyższa ocena miała największą wagę.
Mediana
Mediana to wartość środkowa w uporządkowanym zbiorze danych. Dzieli ona zbiór obserwacji na dwie części: połowa obserwacji ma wartości nie większe od mediany, a połowa nie mniejsze od mediany.
Mediana to taka wartość, która po uporządkowaniu danych rosnąco znajduje się w środku szeregu albo jest średnią dwóch środkowych wartości.
Aby obliczyć medianę, należy najpierw uporządkować dane rosnąco. To dlatego mediana jest miarą pozycyjną: wynika z pozycji obserwacji w uporządkowanym szeregu.
Mediana przy nieparzystej liczbie obserwacji
Dane:
\[ 2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 10 \]
Liczba obserwacji wynosi \(7\). Wartość środkowa to czwarta obserwacja, czyli:
\[ Me=5 \]
Mediana przy parzystej liczbie obserwacji
Dane:
\[ 2,\ 4,\ 4,\ 5,\ 7,\ 8 \]
Liczba obserwacji wynosi \(6\). Dwie środkowe wartości to trzecia i czwarta obserwacja, czyli \(4\) i \(5\). Mediana wynosi:
\[ Me=\frac{4+5}{2}=4{,}5 \]
Dlaczego mediana jest odporna na wartości skrajne?
Mediana zależy od położenia wartości w uporządkowanym szeregu, a nie od sumy wszystkich wartości. Dzięki temu pojedyncza bardzo duża albo bardzo mała obserwacja nie zmienia jej tak silnie jak średniej.
| Zbiór | Wartości | Średnia | Mediana |
|---|---|---|---|
| A | \(2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 10\) | \(5{,}71\) | \(5\) |
| B | \(2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 100\) | \(18{,}57\) | \(5\) |
Wartość \(100\) bardzo mocno zmieniła średnią, ale nie zmieniła mediany. Dlatego mediana jest często lepszą miarą typowego poziomu w przypadku dochodów, wynagrodzeń, cen nieruchomości, czasu oczekiwania albo innych danych o asymetrycznym rozkładzie.
Dominanta
Dominanta, nazywana również modą albo wartością modalną, to wartość występująca w zbiorze danych najczęściej.
Dominanta to wartość cechy, która ma największą liczebność, czyli pojawia się najwięcej razy w badanym zbiorze.
Dla danych:
\[ 2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 10 \]
najczęściej występuje wartość \(4\), dlatego:
\[ Mo=4 \]
Dominanta jest szczególnie użyteczna wtedy, gdy interesuje nas najczęściej spotykana kategoria albo wartość. Można jej używać również dla danych jakościowych, na przykład dla najczęściej wybieranego kierunku studiów, najpopularniejszego koloru produktu albo najczęściej wskazywanej odpowiedzi w ankiecie.
Zbiory jednomodalne, wielomodalne i bez dominanty
Nie każdy zbiór danych ma jedną wyraźną dominantę. Możliwe są różne sytuacje:
| Rodzaj zbioru | Przykład | Interpretacja |
|---|---|---|
| Jednomodalny | \(2,\ 3,\ 3,\ 4,\ 5\) | jedna wartość występuje najczęściej: \(3\) |
| Dwumodalny | \(2,\ 3,\ 3,\ 4,\ 4,\ 5\) | dwie wartości występują najczęściej: \(3\) i \(4\) |
| Wielomodalny | \(1,\ 1,\ 2,\ 2,\ 3,\ 3,\ 4\) | kilka wartości ma taką samą największą liczebność |
| Bez dominanty | \(1,\ 2,\ 3,\ 4,\ 5\) | każda wartość występuje tyle samo razy |
W przypadku cech ciągłych mierzonych bardzo dokładnie dominanta może być mniej użyteczna, ponieważ wiele wartości może występować tylko jeden raz. Wtedy często najpierw grupuje się dane w przedziały i wskazuje przedział modalny, czyli przedział o największej liczebności. Tego typu sposób porządkowania danych omawiamy szerzej w artykule Szeregi statystyczne i formy prezentacji danych.

Kwantyle, kwartyle, decyle i percentyle
Kwantyle to miary pozycyjne, które dzielą uporządkowany zbiór danych na części. Najczęściej używa się kwartyli, decyli i percentyli.
Techniczne sposoby wyznaczania kwantyli, zwłaszcza dla szeregu szczegółowego, omawiamy dokładniej w artykule Kwantyle w szeregu szczegółowym. W tym miejscu skupiamy się przede wszystkim na ich interpretacji jako miar położenia.
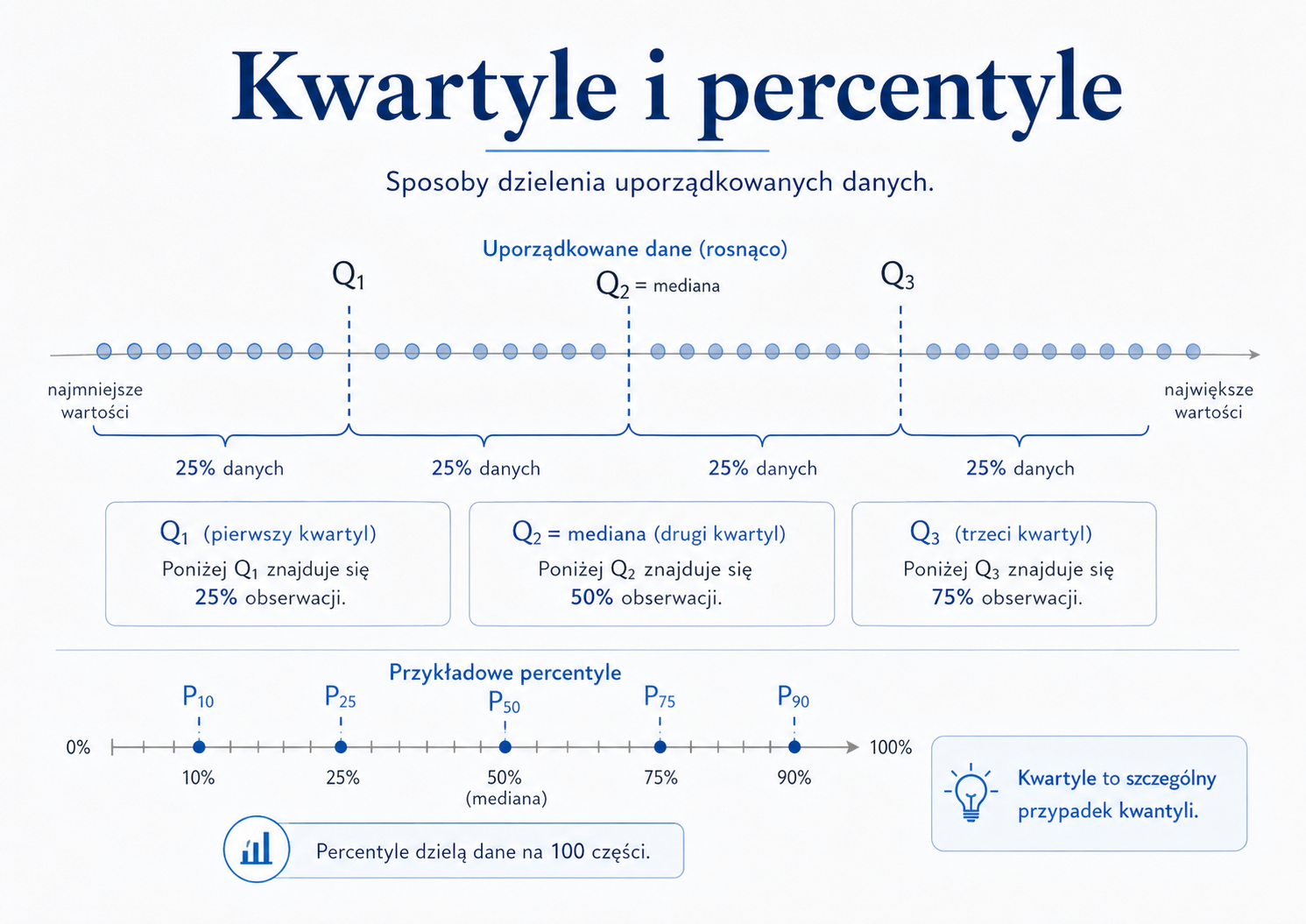
| Miara | Na ile części dzieli zbiór? | Przykład interpretacji |
|---|---|---|
| Kwartyle | \(4\) | \(Q_1\) oznacza, że około \(25\%\) obserwacji ma wartości nie większe od \(Q_1\) |
| Decyle | \(10\) | \(D_7\) oznacza, że około \(70\%\) obserwacji ma wartości nie większe od \(D_7\) |
| Percentyle | \(100\) | \(P_{90}\) oznacza, że około \(90\%\) obserwacji ma wartości nie większe od \(P_{90}\) |
Kwartyle
Kwartyle dzielą uporządkowany zbiór danych na cztery części:
- \(Q_1\) — kwartyl pierwszy, poniżej którego znajduje się około \(25\%\) obserwacji,
- \(Q_2\) — kwartyl drugi, równy medianie, poniżej którego znajduje się około \(50\%\) obserwacji,
- \(Q_3\) — kwartyl trzeci, poniżej którego znajduje się około \(75\%\) obserwacji.
Kwartyle są bardzo ważne przy analizie rozproszenia danych, ponieważ na ich podstawie wyznacza się między innymi rozstęp kwartylowy:
\[ IQR=Q_3-Q_1 \]
Rozstęp kwartylowy pokazuje, jak szeroki jest środkowy obszar obejmujący około \(50\%\) obserwacji. Jest to już jednak przejście od miar położenia do miar zmienności. Innym podstawowym sposobem opisu zmienności są wariancja i odchylenie standardowe, omówione w artykule Odchylenie standardowe i wariancja.
Percentyle
Percentyle są często używane wtedy, gdy chcemy określić pozycję danej osoby, jednostki lub obserwacji na tle większej grupy. Przykładowo, jeżeli wynik testu znajduje się na poziomie \(90\). percentyla, oznacza to, że około \(90\%\) wyników jest nie wyższych od tego wyniku.
Percentyle stosuje się między innymi w edukacji, medycynie, analizie dochodów, analizie wyników sportowych oraz badaniu rozkładu cen.
Miary położenia w szeregu przedziałowym
W praktyce dane często są przedstawione nie jako pojedyncze wartości, lecz jako szeregi przedziałowe. W takim przypadku dokładne wartości obserwacji nie są znane, ale wiadomo, ile obserwacji znajduje się w poszczególnych przedziałach.
Jeżeli nie pamiętasz, czym różni się szereg szczegółowy, punktowy i przedziałowy, warto wrócić do artykułu Szeregi statystyczne i formy prezentacji danych. Tutaj wykorzystamy szereg przedziałowy wyłącznie po to, aby pokazać, jak w takich danych wyznacza się średnią, medianę i dominantę.
Przykład szeregu przedziałowego:
| Przedział wartości | Środek przedziału | Liczebność | Skumulowana liczebność |
|---|---|---|---|
| \(0\text{ – }10\) | \(5\) | \(4\) | \(4\) |
| \(10\text{ – }20\) | \(15\) | \(8\) | \(12\) |
| \(20\text{ – }30\) | \(25\) | \(12\) | \(24\) |
| \(30\text{ – }40\) | \(35\) | \(6\) | \(30\) |
Łączna liczba obserwacji wynosi \(30\).
Średnia w szeregu przedziałowym
Średnią w szeregu przedziałowym obliczamy, wykorzystując środki przedziałów. Każdy środek przedziału mnożymy przez liczebność danego przedziału, sumujemy otrzymane iloczyny i dzielimy przez łączną liczebność.
Obliczenia:
\[ 5\cdot 4+15\cdot 8+25\cdot 12+35\cdot 6 =20+120+300+210=650 \]
\[ \bar{x}=\frac{650}{30}\approx 21{,}67 \]
Średnia wynosi około 21,67.
Mediana w szeregu przedziałowym
Najpierw ustalamy, w którym przedziale znajduje się mediana. Ponieważ liczba obserwacji wynosi \(30\), szukamy pozycji:
\[ \frac{n}{2}=\frac{30}{2}=15 \]
Piętnasta obserwacja znajduje się w przedziale 20 – 30, ponieważ liczebność skumulowana do poprzedniego przedziału wynosi \(12\), a po dodaniu kolejnego przedziału wynosi \(24\).
Wzór na medianę w szeregu przedziałowym:
\[ Me=L+\frac{\frac{n}{2}-F_p}{f_m}\cdot h \]
gdzie:
- \(L\) — dolna granica przedziału medianowego,
- \(n\) — łączna liczba obserwacji,
- \(F_p\) — liczebność skumulowana przed przedziałem medianowym,
- \(f_m\) — liczebność przedziału medianowego,
- \(h\) — szerokość przedziału.
Podstawiamy dane:
\[ Me=20+\frac{15-12}{12}\cdot 10 =20+2{,}5=22{,}5 \]
Mediana wynosi około 22,5.
Dominanta w szeregu przedziałowym
W szeregu przedziałowym najpierw wskazujemy przedział o największej liczebności. Jest to przedział modalny. W naszym przykładzie największą liczebność ma przedział 20 – 30, ponieważ znajduje się w nim \(12\) obserwacji.
Dominantę w szeregu rozdzielczym przedziałowym można wyznaczać ze wzoru tylko pod pewnymi warunkami. W praktyce dydaktycznej najczęściej przyjmuje się, że:
- musi istnieć jeden wyraźny przedział o największej liczebności, czyli jeden przedział modalny,
- przedział modalny nie powinien być pierwszym ani ostatnim przedziałem szeregu, ponieważ wzór korzysta z liczebności przedziału poprzedniego i następnego,
- przedział modalny oraz dwa przedziały sąsiednie powinny mieć taką samą rozpiętość; w wielu zadaniach zakłada się po prostu równe szerokości wszystkich przedziałów.
Jeżeli przedziały mają różne szerokości, sprawa jest bardziej delikatna. Spotyka się wtedy podejście oparte na liczebnościach skorygowanych albo gęstościach liczebności, czyli na relacji liczebności do szerokości przedziału. Nie jest to jednak zawsze omawiane w podstawowych kursach statystyki, dlatego w zadaniach szkolnych i akademickich najlepiej stosować metodę wymaganą przez prowadzącego lub podręcznik.
Wzór na dominantę w szeregu przedziałowym:
\[ Mo=L+\frac{d_1}{d_1+d_2}\cdot h \]
gdzie:
- \(L\) — dolna granica przedziału modalnego,
- \(d_1\) — różnica między liczebnością przedziału modalnego i poprzedniego,
- \(d_2\) — różnica między liczebnością przedziału modalnego i następnego,
- \(h\) — szerokość przedziału.
W naszym przykładzie:
- \(L=20\),
- \(d_1=12-8=4\),
- \(d_2=12-6=6\),
- \(h=10\).
Zatem:
\[ Mo=20+\frac{4}{4+6}\cdot 10 =20+4=24 \]
Dominanta wynosi około 24.
Porównanie średniej, mediany i dominanty
Średnia, mediana i dominanta mogą mieć podobne wartości, ale nie muszą. Ich wzajemne położenie pomaga czasem rozpoznać kształt rozkładu danych.
| Sytuacja | Typowy układ miar | Interpretacja |
|---|---|---|
| Rozkład symetryczny | średnia \(\approx\) mediana \(\approx\) dominanta | dane są względnie równomiernie rozłożone wokół środka |
| Rozkład prawostronnie asymetryczny | dominanta \(\) mediana \(\) średnia | po prawej stronie występują wysokie wartości skrajne |
| Rozkład lewostronnie asymetryczny | średnia \(\) mediana \(\) dominanta | po lewej stronie występują niskie wartości skrajne |
Ten układ należy traktować jako pomoc interpretacyjną, a nie jako sztywną regułę obowiązującą w każdej sytuacji. W praktycznych analizach zawsze warto spojrzeć również na tabelę liczebności, histogram albo wykres pudełkowy. Różne sposoby tabelarycznej i graficznej prezentacji danych omawia artykuł Szeregi statystyczne i formy prezentacji danych.
Grafika powyżej pokazuje rozkład prawostronnie asymetryczny, w którym długi „ogon” rozkładu znajduje się po prawej stronie. W przypadku rozkładu lewostronnie asymetrycznego sytuacja jest lustrzanym odbiciem: długi ogon znajduje się po lewej stronie, a typowy układ miar to zwykle średnia \(\) mediana \(\) dominanta.
Kiedy stosować poszczególne miary położenia?
| Sytuacja | Najlepsza miara | Dlaczego? |
|---|---|---|
| Dane liczbowe, brak wartości skrajnych, rozkład dość symetryczny | średnia arytmetyczna | dobrze opisuje przeciętny poziom i wykorzystuje wszystkie obserwacje |
| Dane liczbowe z wartościami odstającymi | mediana | jest odporna na wartości skrajne |
| Wynagrodzenia, ceny mieszkań, dochody | mediana | lepiej pokazuje typowy poziom niż średnia zawyżana przez wysokie wartości |
| Dane jakościowe | dominanta | średniej i mediany zwykle nie można sensownie obliczyć |
| Dane z różnymi wagami | średnia ważona | uwzględnia różną ważność obserwacji |
| Analiza pozycji jednostki na tle grupy | percentyle | pokazują, jaki odsetek obserwacji znajduje się poniżej danej wartości |
Miary położenia a typ danych
Nie każdą miarę położenia można stosować do każdego typu danych. Wybór miary zależy między innymi od tego, czy zmienna jest jakościowa, porządkowa czy ilościowa.
| Typ zmiennej | Średnia | Mediana | Dominanta | Kwantyle |
|---|---|---|---|---|
| Nominalna | nie | nie | tak | nie |
| Porządkowa | zwykle nie | tak | tak | tak |
| Ilościowa skokowa | tak | tak | tak | tak |
| Ilościowa ciągła | tak | tak | tak, ale często po grupowaniu | tak |
Dla zmiennej nominalnej, takiej jak kolor, województwo albo rodzaj produktu, można wskazać dominantę, ale nie ma sensu liczyć średniej. Dla zmiennej porządkowej, takiej jak poziom zadowolenia, można zwykle wyznaczyć medianę i dominantę, ale średnia bywa problematyczna, ponieważ odstępy między kategoriami nie muszą być równe.
Inne średnie jako miary położenia
W podstawowej statystyce opisowej najczęściej stosuje się średnią arytmetyczną. Istnieją jednak także inne średnie, które są użyteczne w szczególnych sytuacjach. Dokładniejsze omówienie różnych rodzajów średnich znajduje się w artykule Średnia niejedno ma imię.
Średnia geometryczna
Średnia geometryczna jest stosowana między innymi przy analizie przeciętnego tempa wzrostu, stóp zwrotu oraz zmian wyrażonych w postaci mnożnikowej.
Jeżeli inwestycja wzrosła w kolejnych latach o różne procenty, zwykła średnia arytmetyczna stóp wzrostu może być myląca. W takich przypadkach bardziej odpowiednia jest średnia geometryczna.
Średnia harmoniczna
Średnia harmoniczna jest używana wtedy, gdy analizujemy przeciętne tempo, wydajność albo wielkości typu „na jednostkę”, na przykład prędkość przy tej samej długości odcinków.
Przykładowo, jeżeli ktoś przejechał tę samą drogę w jedną stronę z prędkością \(40\ \text{km/h}\), a w drugą stronę z prędkością \(60\ \text{km/h}\), przeciętna prędkość dla całej trasy nie wynosi \(50\ \text{km/h}\). W takiej sytuacji właściwa jest średnia harmoniczna.
W praktyce szkolnej i akademickiej najczęściej wymaga się znajomości średniej arytmetycznej, średniej ważonej, mediany, dominanty i kwartyli. Średnia geometryczna i harmoniczna pojawiają się zwykle w bardziej specjalistycznych zastosowaniach.
Najczęstsze błędy przy interpretacji miar położenia
1. Utożsamianie średniej z typową wartością
Średnia nie zawsze oznacza wartość typową. Jeżeli dane są silnie asymetryczne, średnia może znajdować się daleko od większości obserwacji. Klasycznym przykładem są wynagrodzenia: kilka bardzo wysokich pensji może znacząco podnieść średnią, mimo że większość pracowników zarabia mniej.
2. Obliczanie średniej dla danych jakościowych
Dla danych jakościowych, takich jak kolor, marka produktu, kierunek studiów czy typ odpowiedzi, średnia arytmetyczna nie ma sensu. W takich sytuacjach właściwą miarą położenia może być dominanta.
3. Pomijanie wartości odstających
Przed obliczeniem i interpretacją średniej warto sprawdzić, czy w zbiorze nie występują wartości nietypowe. Nie zawsze należy je usuwać, ale trzeba wiedzieć, że mogą silnie wpływać na wynik. Wpływ wartości nietypowych widać później także przy analizie zmienności, między innymi przy wariancji i odchyleniu standardowym, które omawiamy w artykule Odchylenie standardowe i wariancja.
4. Mechaniczne stosowanie jednego wzoru na kwartyle
W różnych podręcznikach, kalkulatorach i programach statystycznych można spotkać różne techniczne sposoby wyznaczania kwartyli i percentyli. Przy małych zbiorach danych mogą one dawać nieco inne wyniki. Dlatego w zadaniach dydaktycznych warto stosować metodę wymaganą przez prowadzącego albo podręcznik. Szczegółowe przykłady takich obliczeń znajdują się w artykule Kwantyle w szeregu szczegółowym.
Zadanie dla czytelnika
Porównaj średnią, medianę i dominantę
Dane są dwa zbiory wyników:
\[ A:\ 2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 10 \]
\[ B:\ 2,\ 4,\ 4,\ 5,\ 7,\ 8,\ 100 \]
Oblicz średnią arytmetyczną, medianę i dominantę dla obu zbiorów. Następnie odpowiedz, która miara najmocniej zareagowała na wartość skrajną \(100\).
Pokaż rozwiązanie
Dla zbioru \(A\):
\[ \bar{x}_A=\frac{2+4+4+5+7+8+10}{7} =\frac{40}{7}\approx 5{,}71 \]
Dane są już uporządkowane. Środkowa, czwarta wartość to \(5\), więc:
\[ Me_A=5 \]
Najczęściej występuje wartość \(4\), dlatego:
\[ Mo_A=4 \]
Dla zbioru \(B\):
\[ \bar{x}_B=\frac{2+4+4+5+7+8+100}{7} =\frac{130}{7}\approx 18{,}57 \]
Środkowa, czwarta wartość nadal wynosi \(5\), więc:
\[ Me_B=5 \]
Najczęściej występuje nadal wartość \(4\), dlatego:
\[ Mo_B=4 \]
Najmocniej na wartość skrajną \(100\) zareagowała średnia arytmetyczna. Mediana i dominanta pozostały bez zmian. To pokazuje, dlaczego przy danych z wartościami odstającymi często warto analizować nie tylko średnią, lecz także medianę i dominantę.
Podsumowanie
Miary położenia są podstawowymi narzędziami statystyki opisowej. Pozwalają określić, gdzie znajduje się środek, typowy poziom albo charakterystyczna wartość badanego zbioru danych.
Średnia arytmetyczna dobrze opisuje dane symetryczne i pozbawione silnych wartości odstających. Mediana jest bardziej odporna na wartości skrajne i często lepiej opisuje typowy poziom dochodów, wynagrodzeń lub cen. Dominanta wskazuje wartość najczęściej występującą i może być stosowana także dla danych jakościowych. Kwartyle, decyle i percentyle pokazują położenie wybranych części rozkładu i są szczególnie przydatne przy porównywaniu jednostek na tle większej grupy.
Najważniejsze jest jednak nie samo obliczenie miary, lecz jej poprawna interpretacja. Ta sama średnia, mediana albo dominanta może mieć zupełnie inne znaczenie w zależności od typu danych, kształtu rozkładu i celu analizy.
Powiązane artykuły
- Miary statystyczne w statystyce opisowej
- Szeregi statystyczne i formy prezentacji danych
- Średnia niejedno ma imię
- Rodzaje danych statystycznych: zmienne jakościowe, skokowe i ciągłe
- Kwantyle w szeregu szczegółowym
- Miary zróżnicowania w statystyce opisowej — rozstęp, wariancja i odchylenie standardowe
- Miary asymetrii w statystyce opisowej — asymetria prawostronna i lewostronna
- Kurtoza, eksces i koncentracja w statystyce opisowej
- Testowanie hipotez dotyczących średniej w jednej populacji
Masz problem z tym tematem?
Wszechwiedza.pl pomaga zrozumieć matematykę, statystykę, ekonometrię, badania operacyjne, analizę danych, mechanikę, rachunkowość i wiele innych przedmiotów — spokojnie, konkretnie i krok po kroku.
Zapytaj o pomoc